Debezium 架构
最常见的是,您通过 Apache Kafka Connect 来部署 Debezium。Kafka Connect 是一个用于实现和运行的框架和运行时
-
源连接器,如 Debezium,它们将记录发送到 Kafka
-
目标连接器,将记录从 Kafka 主题传播到其他系统
下图显示了基于 Debezium 的变更数据捕获管道的架构
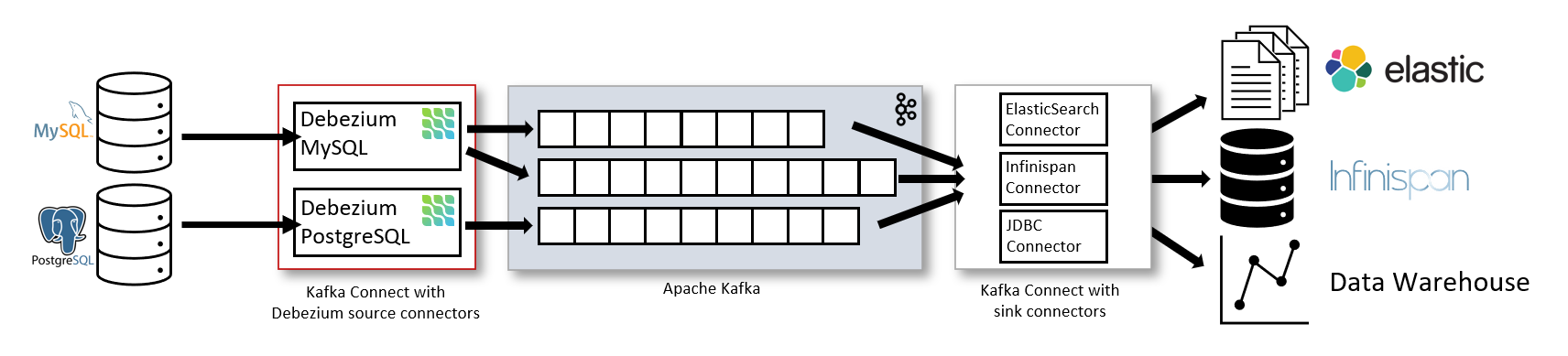
如图所示,Debezium 用于 MySQL 和 PostgreSQL 的连接器被部署用于捕获这两个数据库的更改。每个 Debezium 连接器都与其源数据库建立连接
-
MySQL 连接器使用客户端库访问
binlog。 -
PostgreSQL 连接器从逻辑复制流中读取。
Kafka Connect 作为 Kafka 代理之外的独立服务运行。
默认情况下,来自一个数据库表的更改会写入一个与表名对应的 Kafka 主题。如果需要,您可以通过配置 Debezium 的 主题路由转换 来调整目标主题名称。例如,您可以
-
将记录路由到一个名称与表名不同的主题
-
将多个表的所有变更事件记录流式传输到一个主题中
在变更事件记录进入 Apache Kafka 后,Kafka Connect 生态系统中的不同连接器可以将记录流式传输到其他系统和数据库,如 Elasticsearch、数据仓库和分析系统,或缓存,如 Infinispan。根据所选的目标连接器,您可能需要配置 Debezium 的 新记录状态提取 转换。这个 Kafka Connect SMT 将 Debezium 变更事件的 after 结构传播给目标连接器。修改后的变更事件记录将替换默认传播的、更冗长的原始记录。
Debezium 服务器
部署 Debezium 的另一种方法是使用 Debezium 服务器。Debezium 服务器是一个可配置的、即用型应用程序,它将变更事件从源数据库流式传输到各种消息传递基础设施。下图显示了一个使用 Debezium 服务器的变更数据捕获管道的架构
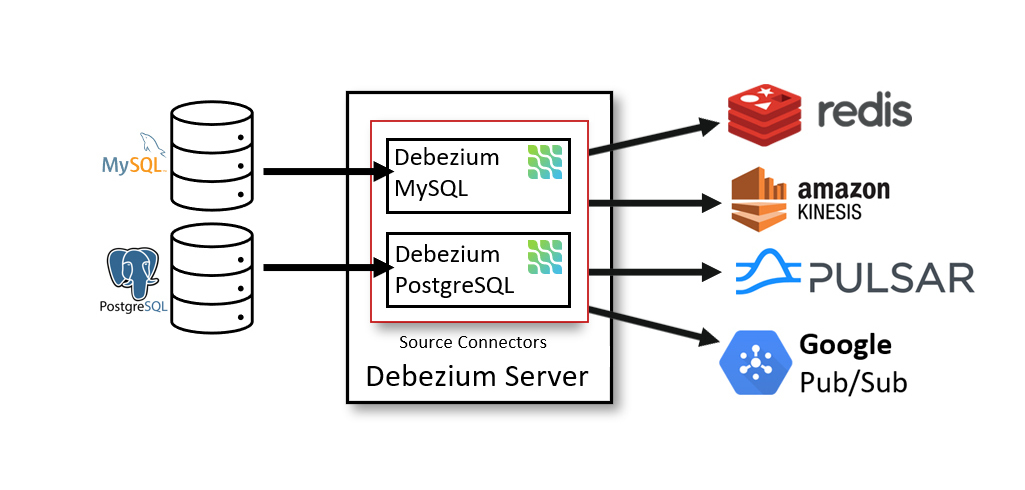
您可以配置 Debezium 服务器使用其中一个 Debezium 源连接器从源数据库捕获更改。变更事件可以被序列化成不同的格式,如 JSON 或 Apache Avro,然后发送到一个各种消息传递基础设施,如 Amazon Kinesis、Google Cloud Pub/Sub 或 Apache Pulsar。
Debezium 引擎
使用 Debezium 连接器的另一种替代方法是 Debezium 引擎。在这种情况下,Debezium 不会通过 Kafka Connect 运行,而是作为库嵌入到您的自定义 Java 应用程序中。这对于在应用程序本身内部消费变更事件(无需部署完整的 Kafka 和 Kafka Connect 集群)或将更改流式传输到其他消息代理(如 Amazon Kinesis)非常有用。您可以在示例存储库中找到后者的 示例。