Debezium 管理平台
|
本项目目前处于孵化状态。确切的语义、配置选项等可能会根据我们收到的反馈而更改。 |
Debezium Management Platform 旨在以一种高度确定性的方式简化 Debezium 在各种环境中的部署。为了实现这一目标,该平台采用了数据中心视角来管理 Debezium 组件。
平台的实现代表了 Debezium Server 的自然演进。过去的版本提供了 Debezium Operator 来简化 Kubernetes 环境中的操作。通过引入该平台,Debezium 现在提供了一个高级抽象,可以在不同环境中部署数据管道,同时利用 Debezium Server。
基本概念
在 Debezium 管理平台中,有四个主要概念:
- 源
-
定义数据的来源。
- 目标
-
定义数据的目标。
- 转换
-
定义单个数据事件在管道中流动时如何进行转换。
- 管道
-
定义数据如何在转换的同时从源流向目标。
定义管道后,它将根据平台的配置方式进行部署。
每个管道都映射到一个 Debezium Server 实例。对于 Kubernetes 环境(目前唯一支持的环境),服务器实例对应一个 DebeziumServer 自定义资源。

安装
|
目前,唯一支持的环境是 Kubernetes。 |
-
Helm
-
带有入口控制器的 Kubernetes 集群
安装通过 Helm chart 提供。
-
输入以下命令添加 Debezium charts 仓库:
helm repo add debezium https://charts.debezium.io -
输入以下命令之一来安装所需的平台版本:
helm install debezium-platform debezium/debezium-platform --version 3.1.0-beta1 --set database.enabled=true --set domain.url=platform.debezium.io或者,要使用 OCI artifact 来安装平台,请输入以下命令:
helm install debezium-platform --set database.enabled=true --set domain.url=platform.debezium.io --version 3.1.0-beta1 oci://quay.io/debezium-charts/debezium-platformdomain.url是唯一必需的属性;它用作Ingress定义中的host。在前面的示例中,使用了
database.enabled属性。此属性通过自动部署 conductor 服务所需的 PostgreSQL 数据库来简化测试环境中的部署。在生产环境中部署时,请勿启用 PostgreSQL 数据库的自动部署。而是通过设置database.name、database.host和连接数据库所需的其他属性来指定现有数据库实例。有关更多信息,请参阅下表。
下表列出了 chart 的所有属性:
| 名称 | 描述 | Default (默认值) |
|---|---|---|
domain.url |
用作入口主机的域。 |
"" |
stage.image |
Helm 用于部署 stage (UI) pod 的镜像。 |
quay.io/debezium/platform-stage:<release_tag> |
conductor.image |
Helm 用于部署 conductor pod 的镜像。 |
quay.io/debezium/platform-conductor:<release_tag> |
conductor.offset.existingConfigMap |
存储 conductor 偏移量的 ConfigMap 的名称。如果未指定值,Helm 将自动创建 ConfigMap。 |
"" |
database.enabled |
启用 Helm 安装 PostgreSQL。 |
false |
database.name |
平台要存储数据的现有数据库的名称。 |
postgres |
database.host |
平台要使用的数据库的主机。 |
postgres |
database.auth.existingSecret |
存储平台用于向数据库进行身份验证的 如果您为此属性提供了一个值,请不要设置 |
"" |
database.auth.username |
平台连接到数据库的用户名。 |
user |
database.auth.password |
由 |
password |
offset.reusePlatformDatabase |
指定管道是否使用配置的平台数据库来存储偏移量。要配置管道使用不同的专用数据库来存储偏移量,请将值设置为 |
true |
offset.database.name |
平台用于存储偏移量的数据库的名称。 |
postgres |
offset.database.host |
平台存储偏移量的数据库的主机。 |
postgres |
offset.database.port |
平台连接到其存储偏移量的数据库的端口。 |
5432 |
offset.database.auth.existingSecret |
存储平台用于向存储偏移量的数据库进行身份验证的 如果您提供了一个 Secret 的名称,请不要设置 |
"" |
offset.database.auth.username |
平台连接到偏移量数据库的用户名。 |
user |
offset.database.auth.password |
由 |
password |
schemaHistory.reusePlatformDatabase |
指定管道是否使用配置的平台数据库来存储模式历史记录。要配置管道使用不同的专用数据库来存储模式历史记录,请将值设置为 |
true |
schemaHistory.database.name |
平台存储模式历史记录的专用数据库的名称。 |
postgres |
schemaHistory.database.host |
平台存储模式历史记录的专用数据库的主机。 |
postgres |
schemaHistory.database.port |
平台连接到其存储模式历史记录的专用数据库的端口。 |
5432 |
schemaHistory.database.auth.existingSecret |
存储平台用于向存储模式历史记录的数据库进行身份验证的 如果您提供了一个 Secret 的名称,请不要设置 |
"" |
schemaHistory.database.auth.username |
平台连接到模式历史记录数据库的用户名。 |
user |
schemaHistory.database.auth.password |
由 |
password |
env |
要传递给 conductor 的环境变量列表。 |
[] |
使用平台
您可以使用平台 UI 执行多种不同的任务。
定义数据源
使用 UI 的Source部分指定托管数据的数据库。您可以将 Debezium 支持的任何数据库配置为数据源。创建的数据源可以由多个管道共享。对数据源的更改将反映在使用它的每个管道中。
创建数据源
您可以使用以下任一编辑器来配置数据源:
- 表单编辑器
-
允许您指定数据源的名称和描述,以及属性列表。有关连接器可用属性的完整列表,请参阅连接器文档。
- 智能编辑器
-
提供一种以 JSON 格式定义数据源配置的方法。您还可以使用该编辑器重新格式化为 Kafka Connect 或 Debezium Server 环境中的 Debezium 连接器设计的数据源配置,以便在平台中使用。该编辑器会自动将平台所需的 JSON 格式应用于指定的数据源配置。

您可以基于现有的 Debezium 配置创建数据源配置,例如用于 Kafka Connect 的 Debezium 连接器或 Debezium Server 的配置。 从Source catalog页面上的工具栏中,选择Create using smart editor。 |
使用智能编辑器配置数据源
您可以使用Smart Editor指定定义数据源配置的 JSON。您可以直接在编辑器中输入和编辑 JSON,或将 JSON 从外部源粘贴到编辑器中。用于在 Debezium 管理平台中配置数据源的 JSON 与 Kafka Connect 上的 Debezium 连接器或 Debezium Server 的配置中 config 部分的 JSON 几乎相同。
要重用现有的 Debezium 连接器配置,您可以上传包含配置的文件,或者将配置复制并粘贴到智能编辑器中。Stage UI 会智能识别您提供的配置格式,并提示您将其重新格式化以供平台使用。
例如,考虑以下用于指定 Kafka Connect 上 Debezium MySQL 连接器配置的 JSON
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"topic.prefix": "dbserver1",
"database.include.list": "inventory"
}
}当您将此 JSON 添加到智能编辑器时,它会检测到它是为 Kafka Connect 格式化的,并显示一个警报。
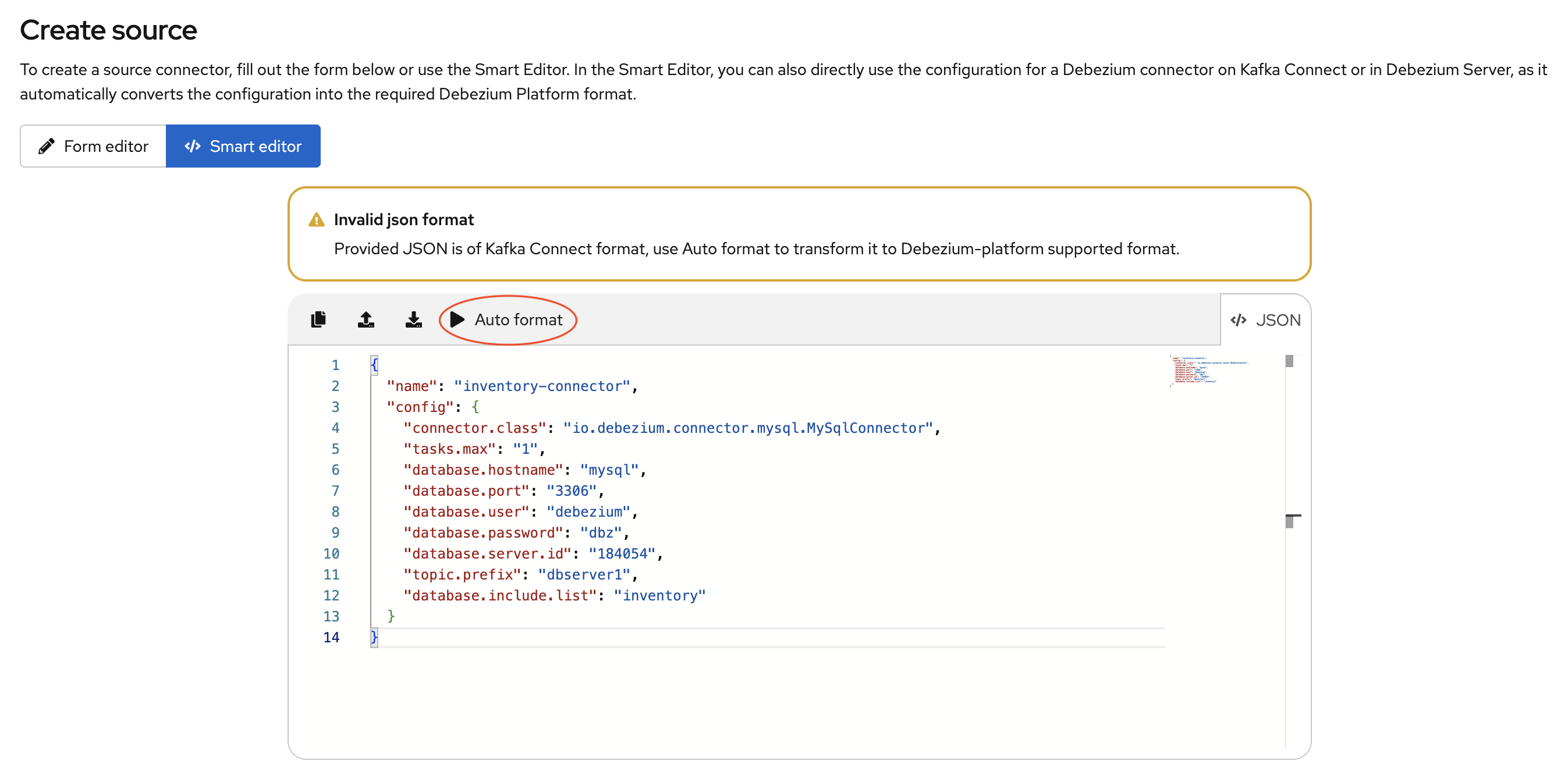
智能编辑器工具栏然后显示Auto Format选项,如前图所示。Autoformat 选项会自动将提供的 JSON 转换为所需的 Debezium Platform JSON 格式。
下图显示了在使用 Autoformat 选项将 MySQL 数据源的配置转换为 JSON 后得到的结果。您可以选择性地编辑 JSON 以更新name字段的值或填充 `description` 字段。
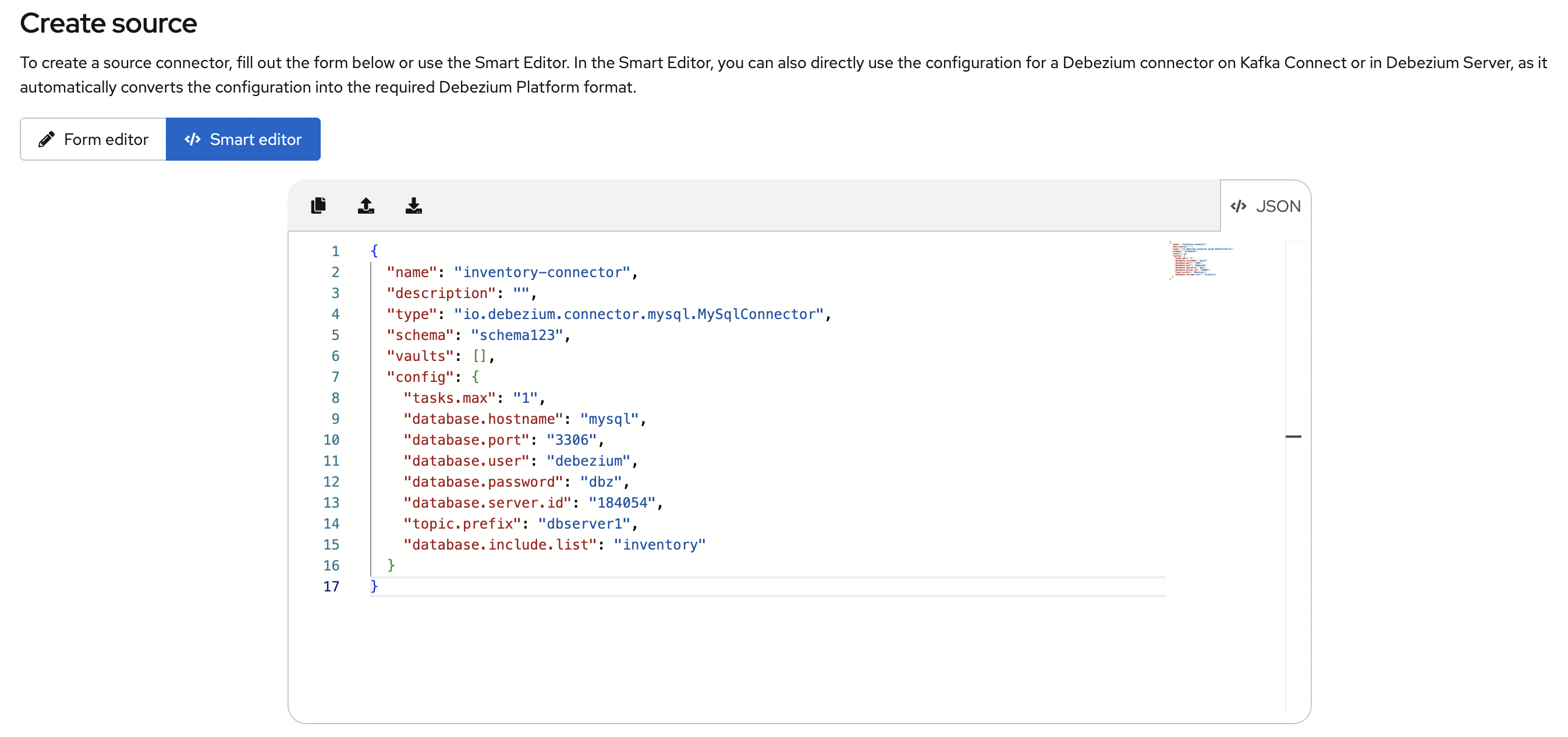
以下示例显示了在更新name和description字段后,平台的配置 JSON。
{
"name": "my-source",
"description": "This is my first source",
"type": "io.debezium.connector.mysql.MySqlConnector",
"schema": "schema123",
"vaults": [],
"config": {
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"topic.prefix": "dbserver1",
"database.include.list": "inventory"
}
}同样,您可以将 Debezium Server 配置在Smart Editor中打开,以自动提取数据源配置并将其重新格式化以供 Debezium 平台使用。有关更多信息,请参阅使用智能编辑器配置数据目标。

定义数据目标
使用 UI 的Destination部分指定平台将源数据发送到的数据接收器。所有 Debezium Server 接收器都可以作为数据目标使用。创建数据目标后,它可以由不同的管道共享,这意味着对数据目标的任何更改都将反映在使用它的每个管道中。
创建数据目标
使用 UI 的Destination部分配置平台发送数据的接收器目标。您可以使用以下任一编辑器来配置数据目标:
- 表单编辑器
-
允许您指定数据目标的名称和描述,以及属性列表。有关接收器连接器可用属性的完整列表,请参阅连接器文档。
- 智能编辑器
-
允许您以 JSON 格式定义接收器配置。或者,您可以提取 Debezium Server 接收器配置并自动将其重新格式化以供平台使用。

要从现有的 Debezium Server 配置创建接收器目标,请在Destination catalog页面上,点击Create using smart editor。 |
使用智能编辑器配置数据目标
您可以使用Smart Editor指定定义数据源配置的 JSON。您可以直接在编辑器中输入和编辑 JSON,或将 JSON 从外部源粘贴到编辑器中。除了少数细微差别外,用于在Smart Editor中配置数据目标的 JSON 与用于定义 Debezium Server sink 的配置几乎相同。
您可以通过上传或粘贴到智能编辑器中来直接使用 Debezium Server 配置。Stage UI 会智能识别配置类型,并提示您将其重新格式化以供平台使用。该编辑器会自动提取 Debezium Server 接收器配置,并将其转换为平台支持的 JSON 格式。
例如,考虑来自 Debezium Server 配置的以下属性
# ...
debezium.sink.type=pubsub
debezium.sink.pubsub.project.id=debezium-tutorial-local
debezium.sink.pubsub.address=pubsub:8085
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.database.hostname=mysql
debezium.source.database.server.id=223344
debezium.source.database.port=3306
debezium.source.database.user=debezium
debezium.source.database.password=dbz
debezium.source.schema.history.internal=io.debezium.storage.file.history.FileSchemaHistory
debezium.source.schema.history.internal.file.filename=data/schema.dat
debezium.source.offset.storage.file.filename=data/offsets.dat
debezium.source.offset.flush.interval.ms=0
debezium.source.topic.prefix=tutorial
debezium.source.database.include.list=inventory
debezium.source.table.include.list=inventory.customers
# ..当您将前面的属性文件添加到智能编辑器时,它会确认它识别该文件为 Debezium Server 配置。
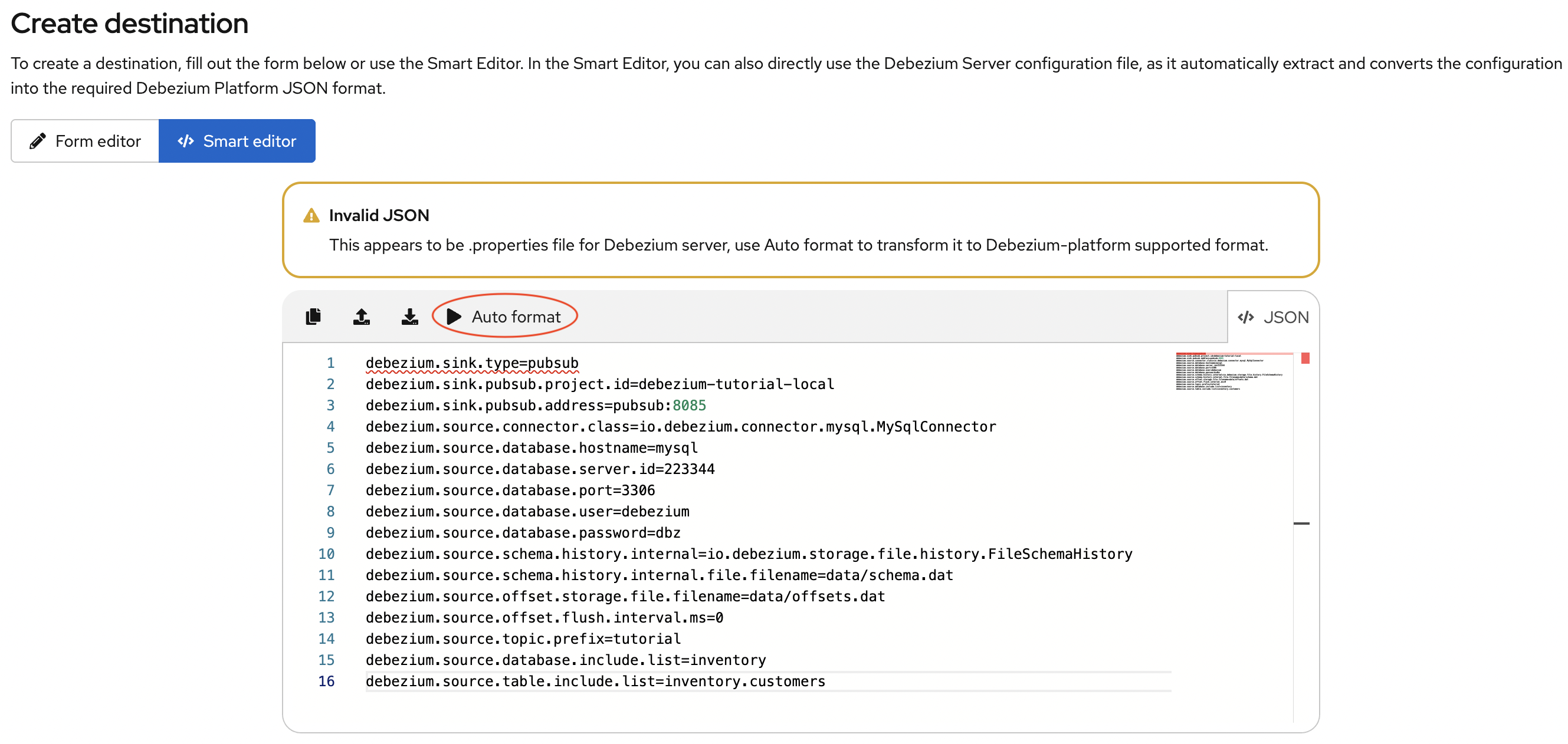
智能编辑器工具栏会显示Auto Format选项,如前图所示。选择此选项可自动提取接收器配置,并将接收器属性转换为 Debezium Platform 支持的 JSON 格式。
下图显示了在编辑器自动格式化您添加的发布-订阅接收器属性后生成的 JSON。编辑 JSON 以更新 name 字段的值,并可选地填充 description 字段。
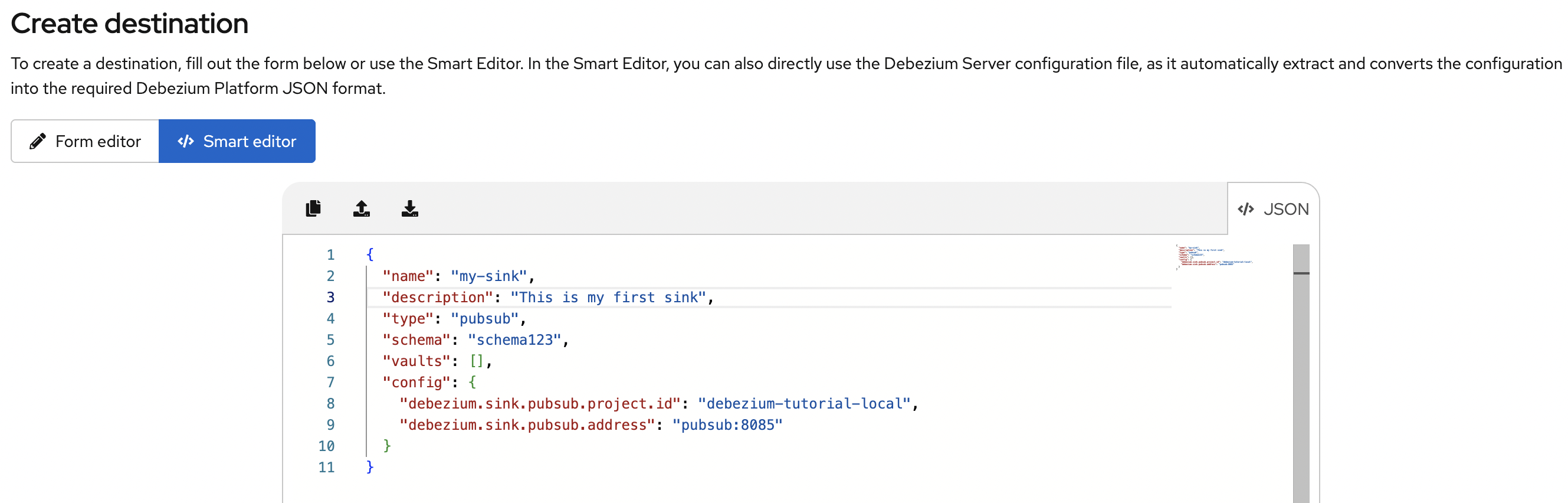
更新名称和描述后,将产生以下 JSON:
{
"name": "my-sink",
"description": "This is my first sink",
"type": "pubsub",
"schema": "schema123",
"vaults": [],
"config": {
"debezium.sink.pubsub.project.id": "debezium-tutorial-local",
"debezium.sink.pubsub.address": "pubsub:8085"
}
}管理转换
使用平台 UI 的Transforms部分来管理您希望在数据管道中使用的转换。
目前,该平台支持 Debezium 提供的所有单消息转换以及任何 Kafka Connect 转换。
转换在管道之间共享。修改转换时,更改将反映在使用该转换的所有管道中。
创建转换
使用平台 UI 的Transforms部分来配置和管理单消息转换。
您可以使用以下任一编辑器来配置转换:
- 表单编辑器
-
允许您指定转换的名称、类型和描述。您还可以设置转换类型特有的其他配置选项。
可选地,如果您只想将转换应用于满足特定条件的记录,可以指定一个谓词。您可以从列表中选择谓词,并设置其属性。
- 智能编辑器
-
允许您使用 JSON 来配置转换。
使用智能编辑器配置转换
您可以使用Smart Editor指定定义转换配置的 JSON。您可以直接在编辑器中输入和编辑 JSON,或将 JSON 从外部源粘贴到编辑器中。
智能编辑器中配置转换的格式与 Debezium 用于配置转换的 Kafka Connect 格式不同,但您可以轻松地在格式之间进行转换。
通常,转换配置中的条目都以 transforms.<transform_name> 作为前缀,其中 <transform_name> 是分配给转换的名称。
例如,在 Debezium 中,以下配置与 unwrap (ExtractNewRecordState) 转换一起使用:
# ...
transforms=unwrap
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.add.fields=op
transforms.unwrap.add.headers=db,table
predicates=onlyProducts
predicates.onlyProducts.type=org.apache.kafka.connect.transforms.predicates.TopicNameMatches
predicates.onlyProducts.pattern=inventory.inventory.products
# ..为了使此配置在 Debezium 平台中使用,请将包含前缀 transforms.unwrap 的属性(transforms.unwrap.type 除外)转换为 JSON 格式。对谓词语句应用相同的过程。
| Smart Editor对直接使用 Kafka Connect 配置格式的支持计划在未来版本中提供。 |
在转换了 unwrap 转换的 Debezium 配置后,将产生以下 JSON:
{
"name": "Debezium marker",
"description": "Extract Debezium payloa d",
"type": "io.debezium.transforms.ExtractNewRecordState",
"schema": "string",
"vaults": [],
"config": {
"add.fields": "op",
"add.headers": "db,table"
},
"predicate": {
"type": "org.apache.kafka.connect.transforms.predicates.TopicNameMatches",
"config": {
"pattern": "inventory.inventory.products"
},
"negate": false
}
}创建和管理管道
管道部分是您连接“点”的地方。您可以定义数据的来源、如何最终转换它们以及它们应该去哪里。
创建管道
-
从平台 UI,打开Pipeline菜单,然后点击Create your first pipeline。Pipeline Designer将打开。在Pipeline designer中,指定要添加到数据管道的组件。
-
点击+ Source框以添加数据源,然后选择一个先前创建的数据源,或创建一个新的数据源。
-
(可选)点击+ Transform框以应用一个或多个转换。
-
点击+ Destination框以添加数据目标,然后选择一个先前创建的数据目标,或创建一个新的数据目标。
Debezium 应用转换的顺序非常重要,并会影响最终输出。请验证您指定的顺序能否产生预期的输出。
在 Pipeline designer* 中,您可以删除转换,或更改应用的转换顺序。有关使用Pipeline designer的更多信息,请参阅使用Pipeline designer删除和排序转换。
| 配置了谓词的转换将带有谓词图标( |

完成管道设计后,点击Configure Pipeline,然后指定管道的名称、描述和日志级别。
从 Debezium Server 配置创建管道
Pipeline designer提供了一个选项,通过上传现有的 Debezium Server 配置属性文件来创建数据管道资源(即,源、目标和转换)。
-
在Pipeline designer中,点击DBZ server config,上传或拖放 Debezium server 属性文件,然后点击Create。Designer 将根据您提供的 Debezium server 配置创建管道的 Source、Transforms 和 Destination。
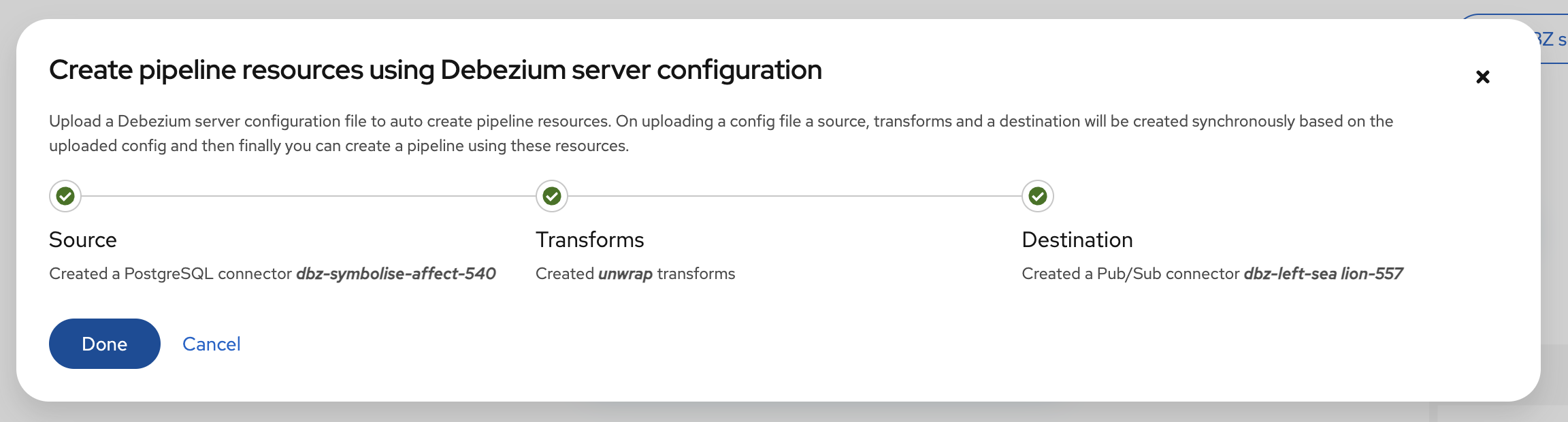
| 源和目标名称会自动生成。 |
编辑管道
-
从平台 UI,打开Pipeline菜单,点击要编辑的管道的Action菜单,然后点击Edit。
-
在Pipeline designer中,根据需要修改转换。有关使用 Pipeline designer 的更多信息,请参阅使用 Pipeline designer 删除和排序转换。
-
点击Save and next以编辑管道的名称、描述和日志级别属性。
使用 Pipeline designer 删除和排序转换
从Pipeline designer,您可以删除转换,或重新排列它们的运行顺序。
-
从Pipeline designer,点击Transform框中的铅笔图标(
 )。
)。 -
从Transform list中,点击转换名称旁边的垃圾桶图标。
如果您配置连接器使用多个转换,您可以使用Pipeline designer中的Transform list来指定它们的应用顺序。列表中的第一个转换首先处理消息。
-
从Pipeline designer,点击Transform框中的铅笔图标(
)。 -
从Transform list中,将转换拖放到您希望应用的顺序,然后点击Apply。