
SQL Server 通过 更改表 提供变更数据捕获 (CDC) - 这些是记录选定“普通”表修改的特殊系统表集。如果您想实时监控更改,可以定期查询这些更改表。这正是 Debezium 目前的工作方式:它以配置好的间隔轮询 SQL Server 的更改表,并将结果转换为连续的 CDC 记录流。这种方法效果很好,但我们可以做得更好吗?
捕获的表由 SQL Server Agent 填充,该代理读取事务日志,提取更改,并将它们存储在更改表中。理论上,我们可以跳过中间人,直接解析事务日志。像 OpenLogReplicator 这样的工具就是这样为 Oracle 数据库处理 CDC 的。让我们深入了解 SQL Server 的内部机制,并稍微探索一下它是如何工作的以及如何存储记录的。
在本文中,我们将
-
准备一个本地 SQL Server 实例用于实验
-
探索 SQL Server 事务日志的内部结构
-
了解记录是如何存储在磁盘上的
准备 SQL Server
我们将本地设置 SQL Server,以便我们可以查看其日志文件。您有两种主要选择:Docker 容器或 VM 安装。让我们看看这两种方法。
设置 SQL Server 容器
使用容器非常简单,您只需启动它即可
docker run -it --rm --name sqlserver \
-e "ACCEPT_EULA=Y" \
-e "MSSQL_SA_PASSWORD=Password!" \
-p 1433:1433 mcr.microsoft.com/mssql/server:2022-latest容器运行后,您可以直接从主机连接,或者附加到容器并使用内置的 mssql-tools
docker exec -it sqlserver /bin/bash
/opt/mssql-tools18/bin/sqlcmd -S localhost -U SA -P Password! -C -No在 VM 中设置 SQL Server
请按照 官方指南 进行 RHEL 或 Fedora 的操作。添加适当存储库、安装和配置服务器的步骤很简单
curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/9/mssql-server-2022.repo
dnf install -y mssql-server
/opt/mssql/bin/mssql-conf setup您可能还需要安装 SQL Server 客户端工具
curl -o /etc/yum.repos.d/mssql-release.repo https://packages.microsoft.com/config/rhel/9/prod.repo
dnf install -y mssql-tools18 unixODBC-devel并在本地连接
/opt/mssql-tools18/bin/sqlcmd -S localhost -U SA -P Password! -C -No如果您想从 VM 外部连接,请打开端口 1433
firewall-cmd --zone=public --add-port=1433/tcp --permanent
firewall-cmd --reload创建测试数据库
服务器启动并运行后,我们就可以在其内部创建一个测试数据库和表了
CREATE DATABASE TestDB;
GO
USE TestDB;
CREATE TABLE products (
id INT PRIMARY KEY,
name NVARCHAR(255) NOT NULL,
description NVARCHAR(512),
weight FLOAT
);
INSERT INTO products VALUES
(1,'scooter','Small 2-wheel scooter',3.14),
(2,'car battery','12V car battery',8.1),
(3,'12-pack drill bits','12-pack of drill bits with sizes ranging from #40 to #3',0.8);
GOSQL Server 事务日志内部原理
SQL Server 中每个持久化的更改,无论是插入、更新、删除还是架构更改,都会写入事务日志。该日志确保在发生崩溃时可以恢复事务。默认情况下,数据库文件位于 /var/opt/mssql/。事务日志文件存储在 /var/opt/mssql/data 中,扩展名为 .ldf。该文件夹还包含 *.mdf 文件 - 包含数据本身和架构信息的.主数据文件。对于我们的示例数据库,这些文件是 TestDB.mdf 和 TestDB_log.ldf。
如果由于任何原因您在此位置找不到这些文件,则可以通过运行以下查询直接从 SQL Server 获取物理文件的位置
SELECT name, physical_name
FROM sys.master_files
WHERE database_id = DB_ID('TestDB');
GOSQL Server 应该会给出类似这样的结果
name physical_name
------------------------------ ------------------------------
TestDB /var/opt/mssql/data/TestDB.mdf
TestDB_log /var/opt/mssql/data/TestDB_log虚拟日志文件 (VLF)
事务日志不是一个巨大的整体空间 — 而是划分为虚拟日志文件 (VLF)。SQL Server 根据日志大小决定创建多少个 VLF。您可以通过调用 sys.dm_db_log_info 过程来获取 VLF 序列号和其他关于数据库的信息
SELECT file_id, vlf_sequence_number, vlf_begin_offset, vlf_size_mb
FROM sys.dm_db_log_info(DB_ID('TestDB'));包含 VLF 序列号、开始偏移量(在文件中的起始位置)和大小(MB)的示例文本输出如下
file_id vlf_sequence_number vlf_begin_offset vlf_size_mb
------- -------------------- -------------------- ------------------------
2 42 8192 1.9299999999999999
2 0 2039808 1.9299999999999999
2 0 4071424 1.9299999999999999
2 0 6103040 2.1699999999999999除了 VLF 序列号外,另一个有趣之处是 VLF 偏移量。第一个 VLF 实际上并不是从日志文件的最开头开始的,而是从文件的 8192 字节之后开始。最初的 8KB 保留给日志文件头。
VLF 头包含 VLF 是活动状态还是非活动状态的信息。VLF 以循环方式使用,未使用的 VLF 可以被新创建的 VLF 重用。当 VLF 处于活动状态时,它不能被重用。这种情况通常发生在它包含未提交事务的记录,或者记录尚未存档或被系统的其他部分处理(例如,复制到更改表、复制到另一个服务器等)。VLF 从活动状态转换为非活动状态的过程称为“日志截断”。VLF 如何以及何时被重用也取决于给定数据库的恢复模型。对于 SIMPLE 恢复模型,VLF 在检查点操作后会被重用,而在 FULL 恢复模型中,检查点操作不会导致 TX 日志截断。
您可以通过运行以下 SQL 命令来找出数据库的当前恢复模式
SELECT name, recovery_model,recovery_model_desc
FROM sys.databases
WHERE name = N'TestDB';
GO磁盘上 VLF 的物理结构与上述列表中 VLF 的行相同。这也可以从 VLF 偏移量 vlf_begin_offset 中看出。然而,VLF 的逻辑结构可能不同。VLF 的顺序由 vlf_sequence_number 决定。0 表示 VLF 尚未被使用。
通过运行以下命令,可以使用 DBCC 工具获得与上面查询非常相似的输出
DBCC LOGINFO('TestDB')本文稍后将详细介绍 DBCC 工具。
块、记录和 LSN
每个 VLF 分成块 — 这是日志中最小的物理写入单元。块大小范围为 512 B 到 60 KB,以 512 B 为增量增长,直到达到最大尺寸。块是实际写入磁盘的单位,通常在事务提交或检查点时写入。
块包含实际的事务日志记录。日志记录是对数据库进行的单个原子更改,例如插入、更新、事务提交等。日志记录以它们在数据库中执行的顺序存储在块中。因此,不同事务的记录可能混合在同一块中。此外,当块写入磁盘时,它可能包含未提交事务的记录。
SQL Server 事务日志文件的整体结构在下图中有示意性地描绘。
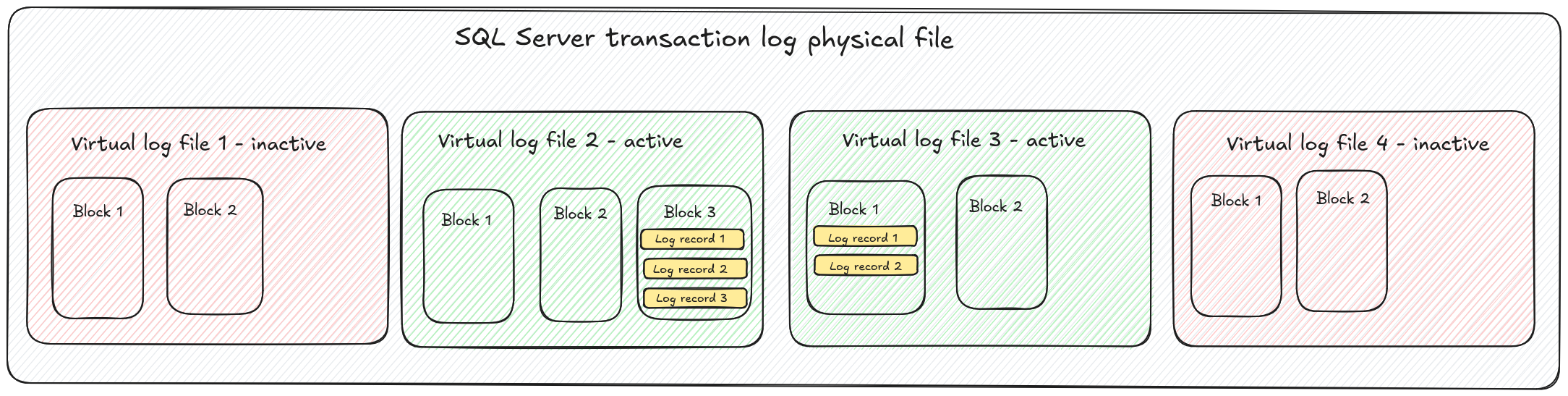
块以及块中的记录都分配有唯一的序列号。块序列号为 4 字节,而记录序列号仅为 2 字节。当我们将 VLF 序列号放在一起时,每个记录都可以由三个数字唯一标识
<VLF sequence number>:<block sequence number>:<record sequence number>这个唯一的记录标识符称为日志序列号,通常缩写为 LSN。Debezium 使用此数字来存储偏移量 — Debezium 看到的最新更改以及 Debezium 处理的最新已提交事务。
SQL Server 数据结构
在前一章中,我们检查了 SQL Server 事务日志的结构。如前所述,事务日志记录了针对数据库执行的所有操作。但是,由于日志最终可能被截断,其中包含的信息可能会丢失。为了确保持久性和性能,实际数据和相关元数据(如索引)会永久存储在磁盘上。让我们仔细看看 SQL Server 如何组织这些数据。
分区和分配单元
每个表或索引存储在一个或多个分区中。每个表或索引的最大分区数为 15,000。存储在单个分区中的表或索引子集称为 hobt,这是 Heap 或 B-tree 的缩写。Heap 称为没有聚集索引的表,其数据未根据索引进行组织。对于带聚集索引的表,表数据是根据索引组织的,实际上是索引行。
分区包含实际行所在的页面。有三种主要类型的数据页面。行内数据页面,存储固定大小的数据或适合单个页面的数据。行溢出数据页面存储可变长度数据类型,例如 varchar 或 nvarchar,当它们不完全适合行内时。LOB 数据页面存储大型对象 (LOB),例如 xml 或大型二进制数据。分区内相同类型的数据页被分组为分配单元。
页面:基本存储单元
页面是 SQL Server 的基本存储单元,存储在我们之前讨论过的 .mdf 文件中。每个 .mdf 文件被划分为 8 KB 的块,每个块就是我们所说的页面。页面以一个 96 字节的头开始,该头存储元数据,例如页面编号、页面类型、页面中剩余的可用空间量、拥有该页面的分配单元编号等。头之后,存储数据行。页面内每行的位置由行偏移量确定。行偏移量是一个 2 字节的值,指示行从页面开始的位置。偏移量以反序存储在页面末尾,形成所谓的行偏移量数组。这种设计使得 SQL Server 能够轻松地在页面内查找、插入或移动行,而无需重写整个页面。页面的结构如下图所示
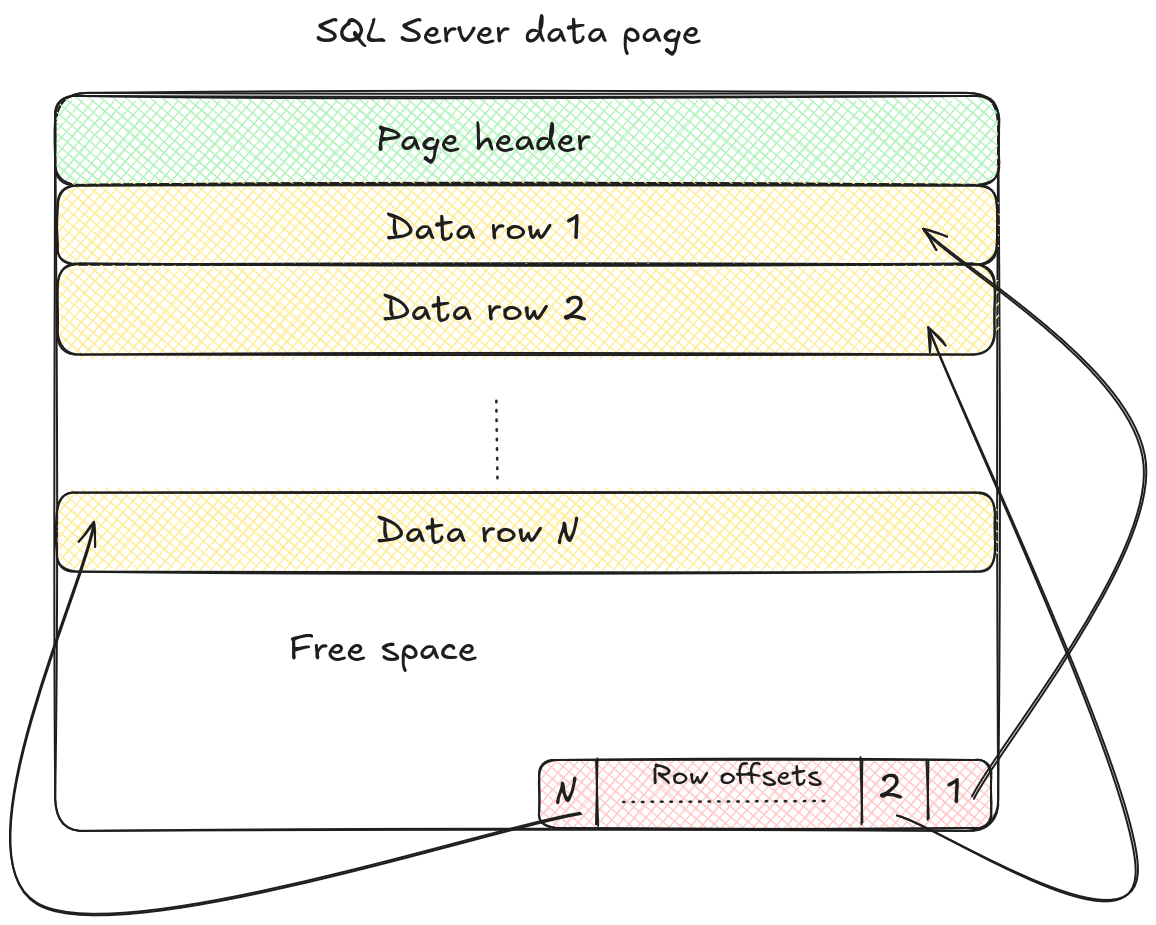
可变长度和 LOB 对象通常无法放入单个页面,并且由于行不能跨越多个页面,因此这些大型值存储在行内数据分配单元之外。相反,它们被放置在由行溢出或 LOB 分配单元管理的页面中。
页面本身被分组为所谓的 区 (extents),这是 SQL Server 用于管理磁盘空间的基本单元。每个区包含 8 个页面,总共覆盖 64 KB。区可以是两种类型。统一区,其中所有 8 个页面属于同一个对象;混合区,其中页面可能属于不同的对象。SQL Server 使用特殊的分配图来跟踪区的用法。全局分配图 (GAM) 记录区是空闲还是已分配。共享全局分配图 (SGAM) 标识仍然包含空闲页面的混合区。
对这些机制的更深入讨论超出了本文的范围,但您可以在官方的 页面和区体系结构指南 中找到更多详细信息。
检查表和页面结构
从实际角度来看,有关索引、表和列的信息可以通过系统视图 sys.indexes、sys.tables 和 sys.columns 进行查询。有关分区和分配单元的详细信息可在 sys.partitions、sys.allocation_units 和最终的 sys.system_internals_allocation_units 中找到。可以使用 OBJECT_ID 函数将这些视图链接起来。例如,要确定我们的 products 表有多少分区,我们可以运行以下查询
SELECT object_id, partition_id, partition_number, hobt_id
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'products');输出可能如下所示
object_id partition_id partition_number hobt_id
----------- -------------------- ---------------- --------------------
901578250 72057594045726720 1 72057594045726720然后可以使用生成的 partition_id 来获取此表的分配信息
SELECT *
FROM sys.allocation_units
WHERE container_id = (
SELECT partition_id
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'products')
);查询结果如下
allocation_unit_id type type_desc container_id data_space_id total_pages used_pages data_pages
-------------------- ---- ------------------------------------------------------------ -------------------- ------------- -------------------- -------------------- --------------------
72057594052476928 1 IN_ROW_DATA 72057594045726720 1 9 2 1通过互联这些系统视图,我们可以收集有关表和索引如何构造的详细信息。但是,这些视图未能公开存储数据的实际页面内容。
使用 DBCC IND 探索页面
要检查单个页面的结构和内容,SQL Server 提供了 DBCC 工具。我们需要的功能很多都是未公开的,但在社区资源中得到了充分描述。
第一个有用的命令是 DBCC IND,它返回给定表的页面信息。该命令的语法如下
DBCC IND ( [ database_name | database_id ], table_name, index_id )index_id 可以从 sys.indexes 中获取,或者 -1 显示所有索引和 IAM(索引分配图),-2 只显示 IAM。
对于我们的 products 表
DBCC IND ('TestDB', 'products', -1)结果为
PageFID PagePID IAMFID IAMPID ObjectID IndexID PartitionNumber PartitionID iam_chain_type PageType IndexLevel NextPageFID NextPagePID PrevPageFID PrevPagePID
------- ----------- ------ ----------- ----------- ----------- --------------- -------------------- -------------------- -------- ---------- ----------- ----------- ----------- -----------
1 231 NULL NULL 901578250 1 1 72057594045726720 In-row data 10 NULL 0 0 0 0
1 336 1 231 901578250 1 1 72057594045726720 In-row data 1 0 0 0 0 0第一个记录代表 IAM 页面,第二个记录对应包含表行的实际数据页面。这里的关键值是 PageFID 和 PagePID,我们将在下一个命令 DBCC PAGE 中使用它们。
使用 DBCC PAGE 读取页面
DBCC 工具的另一个未公开功能是 DBCC PAGE,它转储请求页面的内容。在运行 DBCC PAGE 之前,必须启用跟踪标志 3604,将输出发送到客户端
DBCC TRACEON(3604);DBCC PAGE 命令的语法是
DBCC PAGE ( [ database_name | database_id ], file_number, page_number, print_option )其中 file_number 和 page_number 是 DBCC IND 中的 PageFID 和 PagePID。print_option 控制详细程度,可以取值 0-3。添加 WITH TABLERESULTS 可以将输出格式化为表格形式。
对于我们的数据页面表
DBCC PAGE ('TestDB', 1, 336, 0)我们得到
PAGE: (1:336)
BUFFER:
BUF @0x00000009000FDA40
bpage = 0x000000101A8B0000 bPmmpage = 0x0000000000000000 bsort_r_nextbP = 0x0000000000000000
bsort_r_prevbP = 0x0000000000000000 bhash = 0x0000000000000000 bpageno = (1:336)
bpart = 4 bstat = 0x10b breferences = 0
berrcode = 0 bUse1 = 22094 bstat2 = 0x0
blog = 0x1cc bsampleCount = 0 bIoCount = 0
resPoolId = 0 bcputicks = 0 bReadMicroSec = 294
bDirtyPendingCount = 0 bDirtyContext = 0x000000100C4947A0 bDbPageBroker = 0x0000000000000000
bdbid = 5 bpru = 0x00000010047A0040
PAGE HEADER:
Page @0x000000101A8B0000
m_pageId = (1:336) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000
m_objId (AllocUnitId.idObj) = 222 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057594052476928
Metadata: PartitionId = 72057594045726720 Metadata: IndexId = 1
Metadata: ObjectId = 901578250 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 16 m_slotCnt = 3 m_freeCnt = 7761
m_freeData = 425 m_reservedCnt = 0 m_lsn = (42:208:29)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0 DB Frag ID = 1
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:1) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGEDPage Header 部分显示了有用的元数据,例如
-
m_lsn— 此页面最后一次更改的日志序列号,在恢复过程中很有用 -
m_slotCnt— 页面上的行数(槽数) -
pminlen— 固定长度数据的尺寸 -
m_freeData— 免费空间开始的偏移量 -
m_prevPage/m_nextPage— 指向相邻页面的指针(此处为空,因为我们的数据太少,不足以跨越多个页面)
当 print_option 设置为 1 或 3 时,DBCC PAGE 还在 DATA 部分显示行内容的字节表示。您可以轻松地在此处识别可变字符串列。为简洁起见,此处仅显示第一行
Slot 0, Offset 0x60, Length 81, DumpStyle BYTE
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 81
Memory Dump @0x000000096A026060
0000000000000000: 30001000 01000000 1f85eb51 b81e0940 04000002 0........ëQ¸. @....
0000000000000014: 00270051 00730063 006f006f 00740065 00720053 .'.Q.s.c.o.o.t.e.r.S
0000000000000028: 006d0061 006c006c 00200032 002d0077 00680065 .m.a.l.l. .2.-.w.h.e
000000000000003C: 0065006c 00200073 0063006f 006f0074 00650072 .e.l. .s.c.o.o.t.e.r
0000000000000050: 00在输出末尾,您还可以看到偏移量映射,按照写入磁盘的顺序(反序)显示
OFFSET TABLE:
Row - Offset
2 (0x2) - 254 (0xfe)
1 (0x1) - 177 (0xb1)
0 (0x0) - 96 (0x60)结论
在本博文中,我们探讨了 SQL Server 事务日志的基本结构,并检查了表如何在磁盘上物理存储。理论辅以实践示例 — 从安装 SQL Server 到转储数据页面的内容。
这些见解为下一篇文章奠定了坚实的基础,在下一篇文章中,我们将探讨以编程方式解析 SQL Server 事务日志的方法。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。