
如今的数据格局与过去集中式数据库和简单 ETL 流程已大不相同。当今的组织在多样化的数据源、实时流处理、微服务架构和多云部署的环境中运行。最初从运营系统到报告数据库的简单数据流,已经演变成复杂的互联管道、转换和依赖网络。从 ETL 到 ELT 模式的转变、数据湖的采用以及 Apache Kafka 等流媒体平台的普及,为数据处理带来了前所未有的灵活性。然而,这种灵活性也付出了代价:理解数据如何在这些系统中移动、转换和演变变得越来越具挑战性。
理解数据血缘
数据血缘是指跟踪数据从源头到最终目的地的流动和转换的过程。它本质上映射了数据的“生命周期”,显示了它的来源、如何被改变以及它在数据管道中的去向。这包括记录数据在其旅程中经历的所有转换、连接、拆分和其他操作。
其核心在于,数据血缘回答了关键问题:这些数据来自哪里?它们经历了哪些转换?哪些下游系统依赖于它?当问题出现时,团队应该将调查重点放在哪里?
数据血缘追踪的重要性
- 合规性与治理
-
GDPR、SOX 等现代法规以及特定行业的合规框架要求组织能够全面了解数据是如何被处理的。数据血缘追踪提供了合规性所需的审计追踪,使组织能够准确地展示敏感信息如何在其系统中流动。
- 数据质量与信任
-
当业务用户在报告中遇到意外值或异常时,数据血缘追踪能够实现快速的质量评估。团队可以快速追溯数据在处理链中的来源,从而识别质量问题的根源,增强对数据驱动型决策的信心。
- 运营效率
-
在复杂的数据生态系统中,故障排除传统上需要耗时的人工调查。数据血缘追踪将这种被动过程转变为系统化运营,使团队能够快速识别受影响的系统,评估影响范围,并实施有针对性的修复。
OpenLineage
OpenLineage 是一个用于数据血缘追踪的开放标准,它提供了一种统一的方式来收集和跟踪跨多个数据系统的血缘元数据。该规范定义了描述数据集、作业和运行的通用模型,使得在异构数据基础设施中构建全面的血缘图变得更加容易。
OpenLineage 的核心是用于捕获血缘事件的标准 API。管道组件(例如调度程序、数据仓库、分析工具和 SQL 引擎)可以使用此 API 将有关运行、作业和数据集的信息发送到兼容的 OpenLineage 后端进行进一步研究。

OpenLineage 对象模型
OpenLineage 定义了一个通用的运行(run)、作业(job)和数据集(dataset)实体模型,这些实体使用一致的命名策略进行标识。核心血缘模型可以通过定义特定的 Facet 来扩展,以丰富这些实体。
核心实体
- 数据集 (Dataset)
-
数据集是数据的一个单位,例如数据库中的表或云存储桶中的对象。当写入数据集的作业完成时,数据集会发生变化。
- 作业 (Job)
-
作业是创建或消耗数据集的数据管道过程。作业可以演变,记录这些变化对于理解管道的机制至关重要。
- 运行 (Run)
-
运行是已执行的作业的一个实例。它包含有关作业的信息,例如开始和完成(或失败)时间。
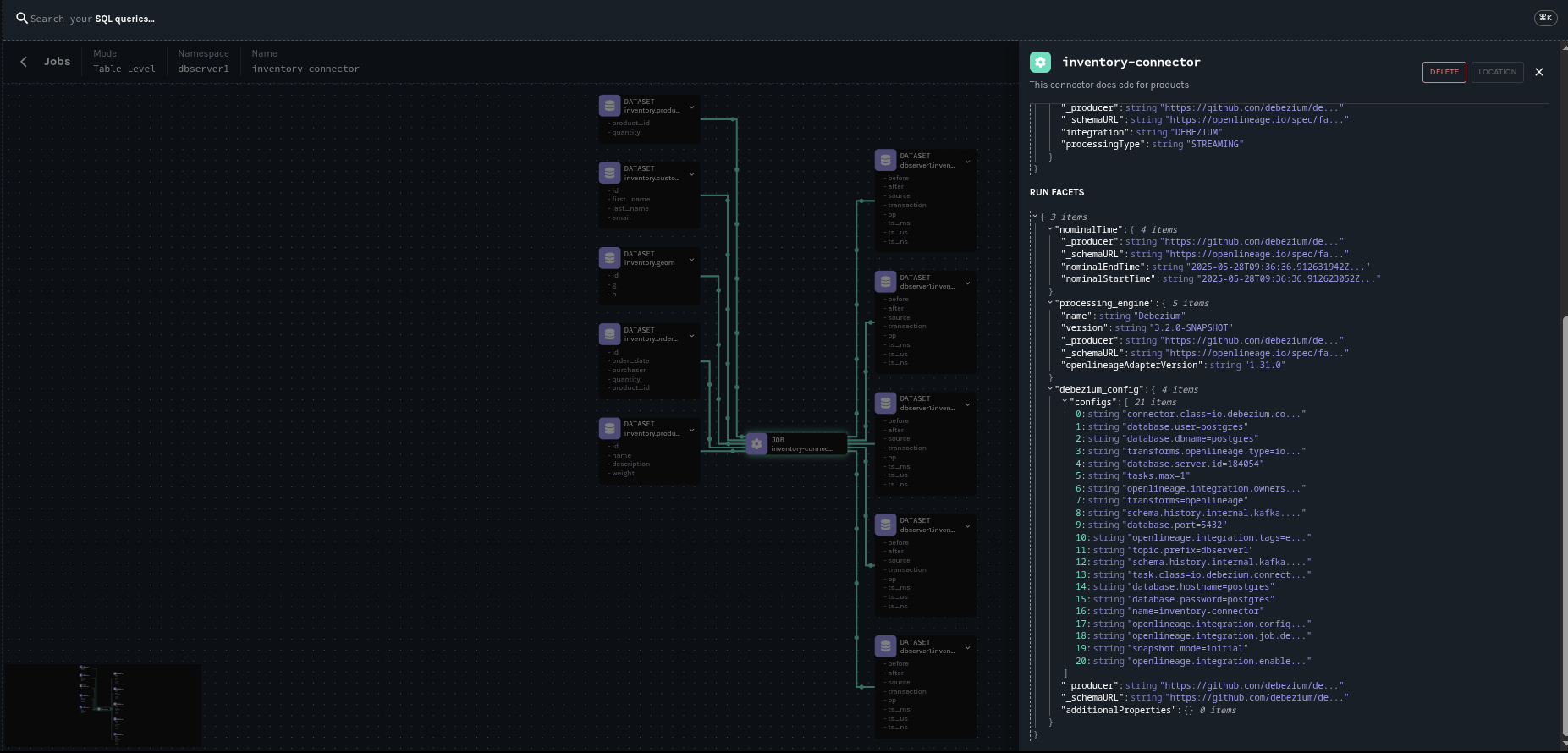
Debezium 如何与 OpenLineage 集成
为了与 OpenLineage 集成,Debezium 使用了 OpenLineage Java SDK。
OpenLineage 作业映射
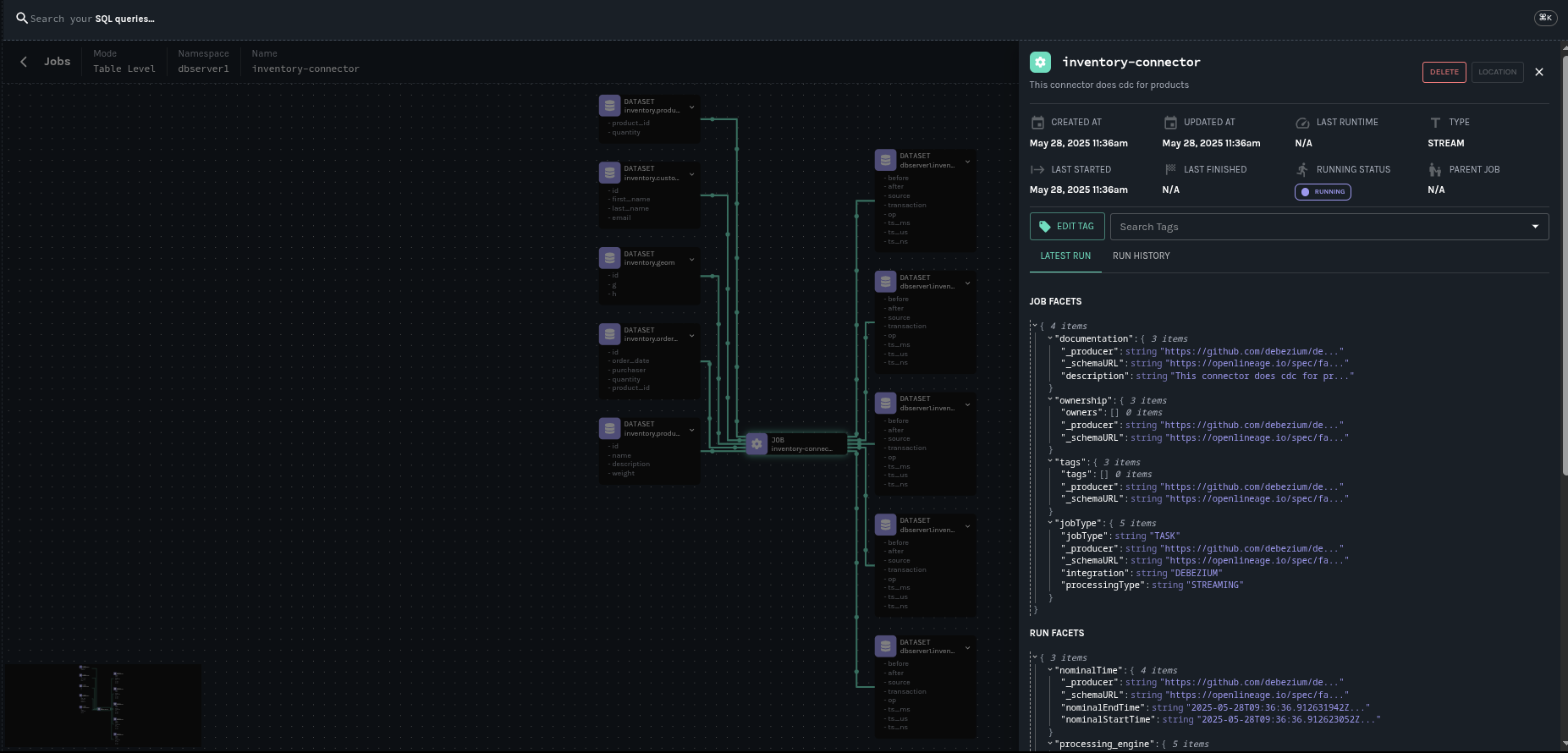
Debezium 连接器被映射到一个 OpenLineage **作业**,该作业包含以下元素
- 名称
-
继承自 Debezium 的
topic.prefix.<taskId>。 - 命名空间
-
继承自
openlineage.integration.job.namespace,如果已指定;否则默认为topic.prefix。 - Debezium 版本信息
-
连接器版本
- 完整的连接器配置
-
连接器使用的整个配置
- 作业元数据
-
作业描述、一组可配置的标签和所有者。
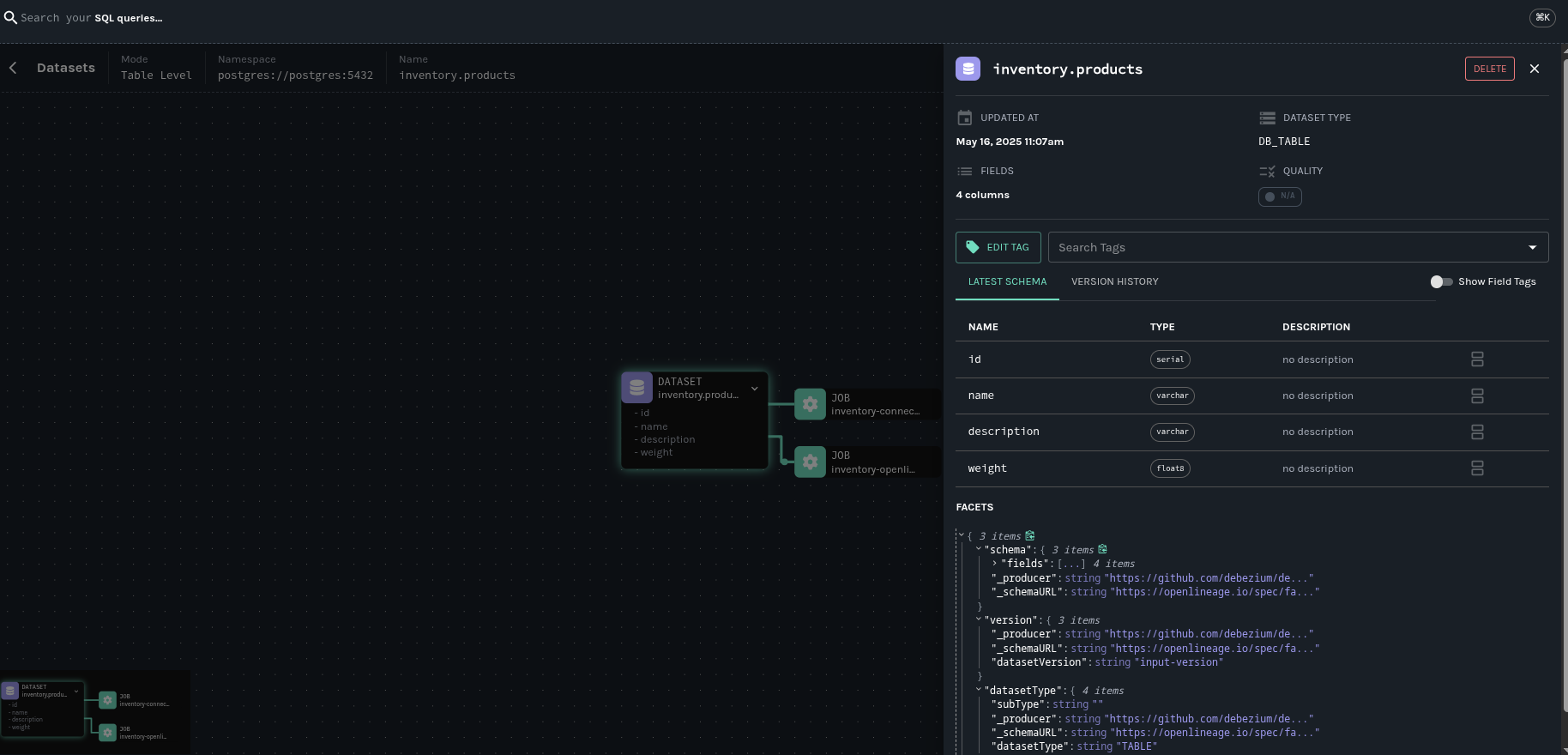
源连接器的数据集映射
以下数据集映射是可能的
- 输入数据集
-
自动为 Debezium 配置捕获其更改的数据库表创建。以下特征会影响映射:
-
每个被监控的表都成为一个输入数据集。
-
捕获表的模式信息,包括列名和类型。
-
在 DDL 更改后,数据集模式会动态更新。
-
- 输出数据集
-
表示应用 OpenLineage 转换后产生的 Kafka 主题。映射是根据以下原则创建的:
-
连接器生成的每个 Kafka 主题都成为一个输出数据集。
-
输出数据集捕获完整的 CDC 事件结构,包括元数据字段。
-
数据集的名称基于连接器的 topic prefix 配置。
-
| 此映射对于源连接器有效。我们将在后续版本中增加对 sink 的支持。 |
作业状态
每次 Debezium 连接器启动、在正常关闭或失败后,都会将新的运行事件与作业关联起来。因此,作业状态将发生如下变化:
- START
-
在连接器初始化期间发出。
- RUNNING
-
在正常流式操作期间和处理单个表期间定期发出。这些定期事件确保了长时间运行的流式 CDC 操作的连续血缘跟踪。
- COMPLETE
-
在连接器正常关闭时发出。
- FAIL
-
在连接器遇到错误时发出。
那么,我们实际可以用这些血缘元数据做什么呢?
它是一个开源元数据服务,用于收集、聚合和可视化数据生态系统的元数据。它维护数据集是如何被消费和产生的出处,提供对作业运行和数据集访问频率的全局可见性,实现数据集生命周期的集中管理,等等。
下图显示了由 Debezium Postgres 连接器与我们的示例数据库 inventory 生成的血缘图。
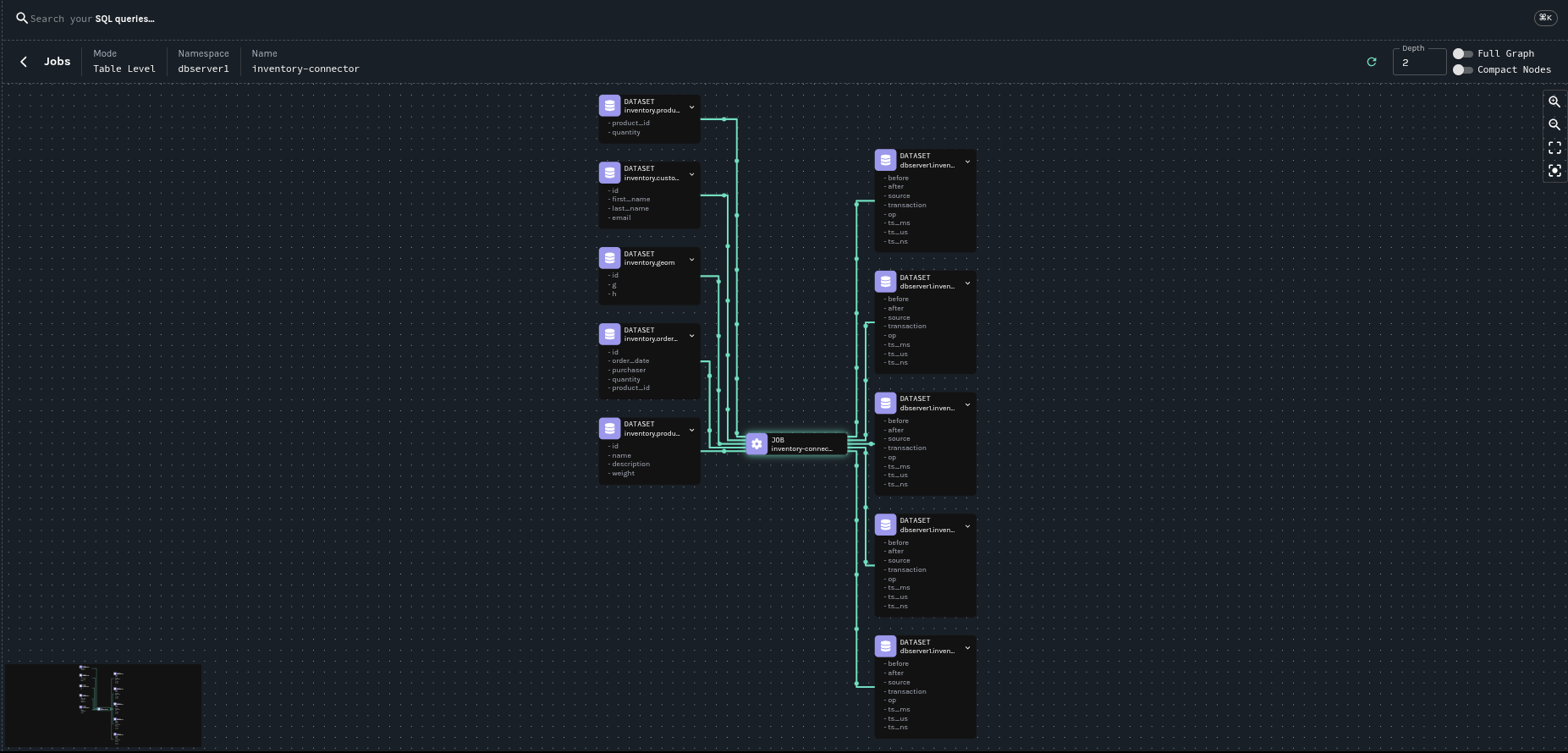
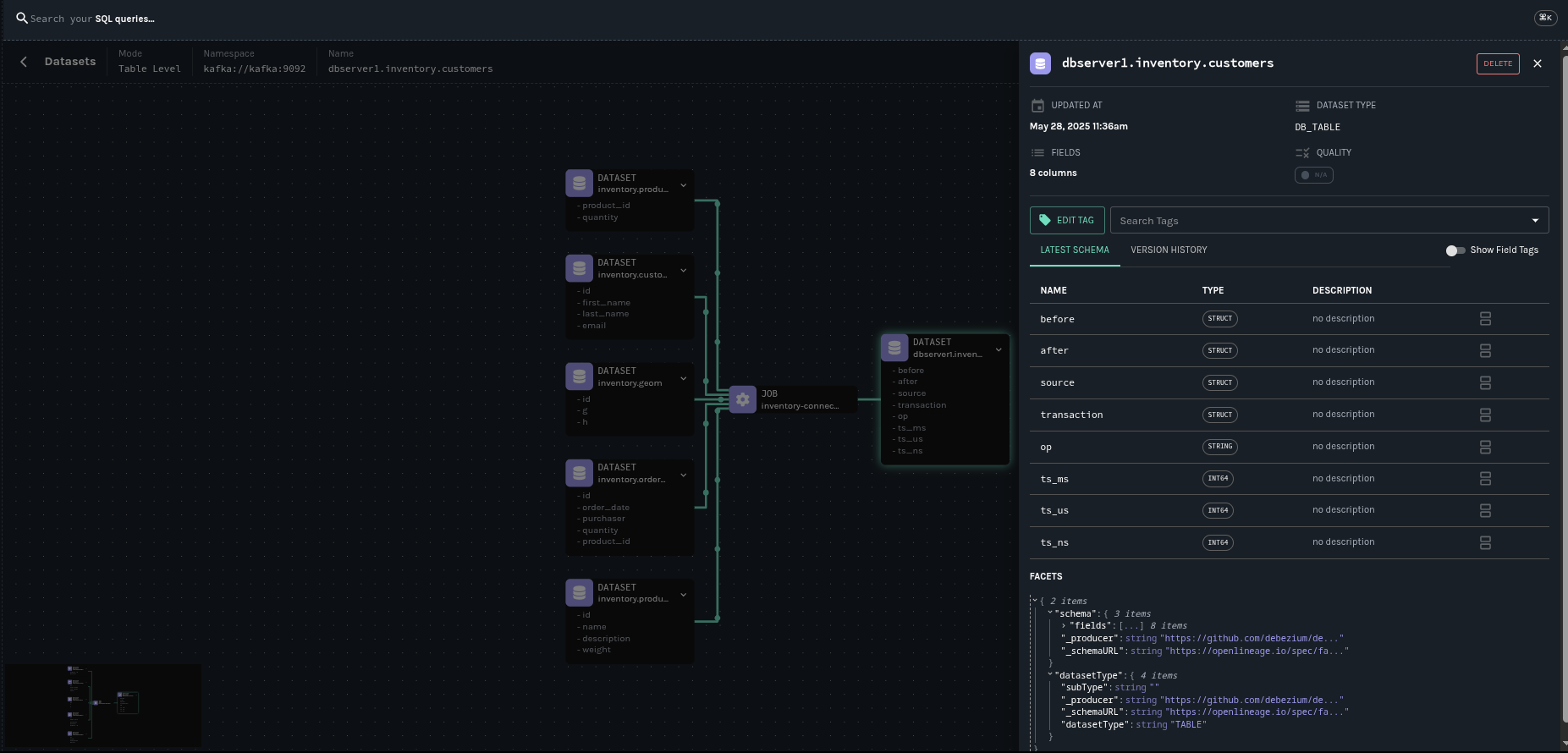
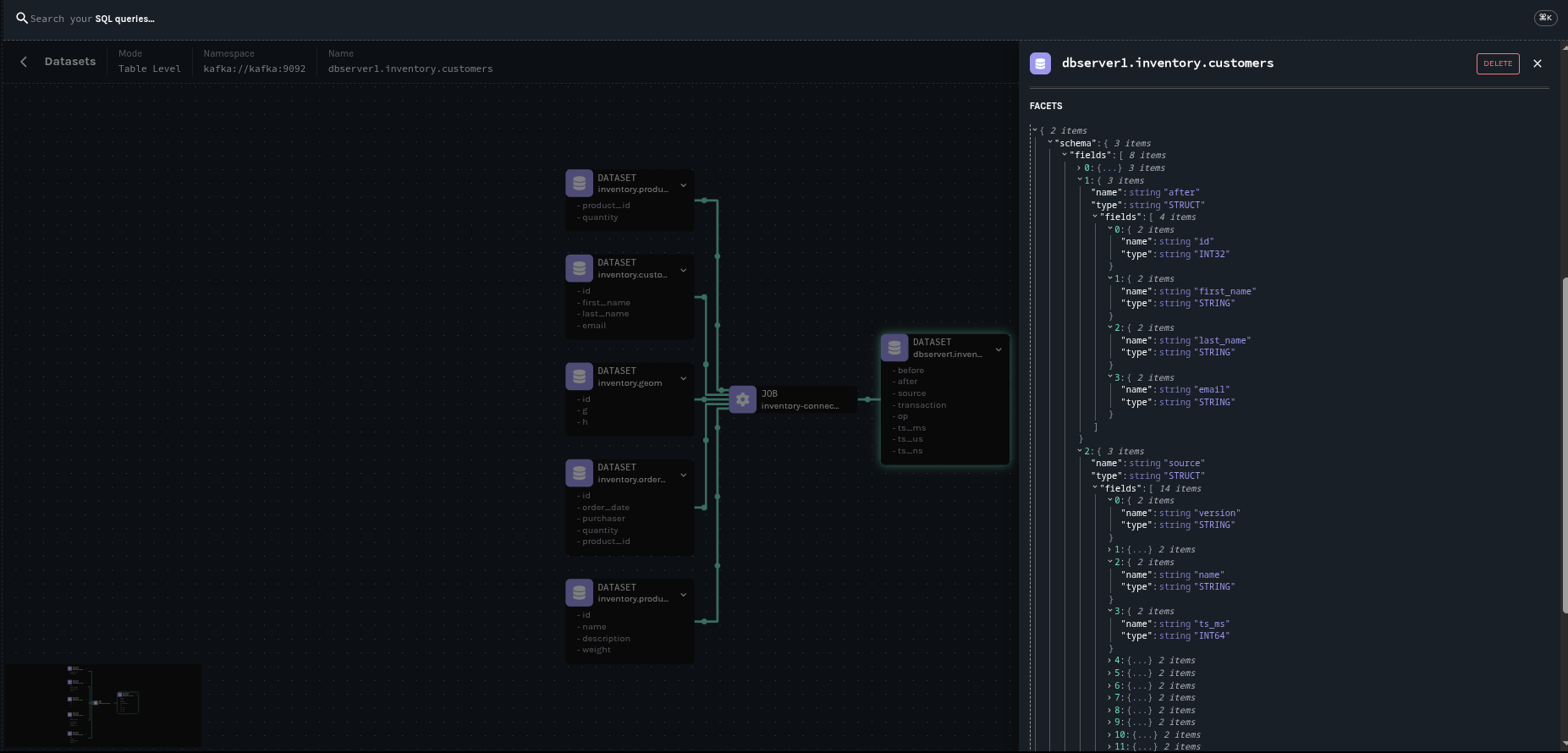
本文是关于 OpenLinage 集成的入门介绍。后续将有一篇文章进行完整的演示。同时,您可以参考我们的文档开始尝试。
我们还建议您阅读 通过 Marquez API 探索血缘历史。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。