
我们最近遇到的一个问题是如何有效地将变更数据捕获(CDC)与 AI 工作负载集成——特别是对于关键的组织知识无法公开访问的场景。为了帮助您利用内部数据,Debezium 3.1 引入了面向 AI 的功能,例如 Embeddings SMT 和 Milvus sink,您可以将它们结合起来为 LLM 提供输入。您可以在 Debezium 3.1 发行说明中阅读有关这些增强功能的更多信息。
引言
在本文中,我们将展示 Debezium、Milvus 和 Ollama 如何协同工作,构成一个检索增强生成 (RAG) 管道。通过捕获关系数据库的变更,并使用向量嵌入进行丰富,以及实现这些向量之间的相似性搜索,您可以构建由最新、特定领域知识驱动的 AI 应用程序。
让我们来看一个示例,说明如何使用 Debezium 来丰富您的 AI 应用程序,使其包含从组织内部专家那里捕获的知识。
假设我们的组织引入了一个由 LLM 支持的新的 AI 驱动应用程序。为了丰富和扩展语言模型,我们希望利用存储在 PostgreSQL 数据库中文档中的内部组织知识。当组织内的用户与 AI 应用程序交互时,我们希望确保其响应能够获得最新的本地知识。由于存储在 PostgreSQL 数据库中的本地知识是不断变化的,文档会被添加、更新或撤回以符合监管要求,因此我们需要一个能够灵活适应这些变化的解决方案。
解决此问题的常见方案是实现检索增强生成 (RAG)。本文演示了如何使用 Debezium 构建一个由 CDC 驱动的 RAG 系统,该系统使用以下组件:
-
用于数据存储的 PostgreSQL 数据库
-
Milvus 向量数据库
-
Debezium Server,用于从 PostgreSQL 向 Milvus 提供数据
-
本地托管的 Ollama LLM
-
一个与 LLM 交互并使用 RAG 提供提示上下文的 Java 应用程序
什么是 RAG (检索增强生成)?
检索增强生成 (RAG) 是一种 AI 技术,它结合了信息检索和生成模型,以产生更准确、更具上下文相关性的响应。RAG 管道不完全依赖模型内部的知识,而是从外部源(如向量数据库)检索相关文档或数据,并利用这些信息来丰富模型的响应。在我们的场景中,Debezium、Milvus 和 Ollama 协同工作,构成一个 RAG 工作流:捕获和向量化数据变更,存储在 Milvus 中,然后检索这些数据以使用最新的、特定领域的信息来增强 LLM 的输出。
什么是 Debezium Server?
Debezium Server 是 Debezium 的一种实现,可用于将变更事件从数据库流式传输到各种接收器,而无需部署 Kafka 集群。它提供了一种轻量级的方法来消费 CDC 事件并将其转发到其他应用程序可以消费的目的地。Debezium Server 还支持在其处理管道中使用 Kafka Connect 单个消息转换。
什么是 Milvus?
Milvus 是一个专门的向量数据库,专为相似性搜索和重度 AI 工作负载而设计。无论是产品推荐、图像搜索还是任何依赖于快速向量检索的其他用例,Milvus 都为此而生。向量数据库和快速向量检索是任何 RAG 解决方案的核心。向量数据库存储所谓的“**嵌入**”——数据的向量表示,可用于相似性搜索或聚类等任务。基于提示与存储数据之间的相似性,AI 应用程序扩展了提示的上下文。
为什么选择 Milvus 作为接收器?
对于需要最新数据向量表示的应用程序,将更改从事务数据库推送到 Milvus 是非常有意义的。通过使用 Milvus,您不仅可以使 AI 模型与运营数据保持同步,还可以将相似性搜索卸载到为此而构建的系统中。
Debezium Milvus Sink 如何工作
Milvus Sink 的典型部署使用以下工作流:
-
Debezium 连接器从源数据库捕获变更。
-
如果源数据库不包含带有嵌入的字段,则使用 FieldToEmbedding SMT 来丰富变更事件中的向量嵌入。
-
Milvus Sink 将向量数据写入 Milvus。
-
Milvus 存储和索引向量,以便快速进行相似性搜索。
示例应用程序
这篇博文基于 Debezium ai-rag 示例应用程序。我们将逐步深入探讨应用程序的细节和内部原理,以便您可以轻松构建自己的应用程序。
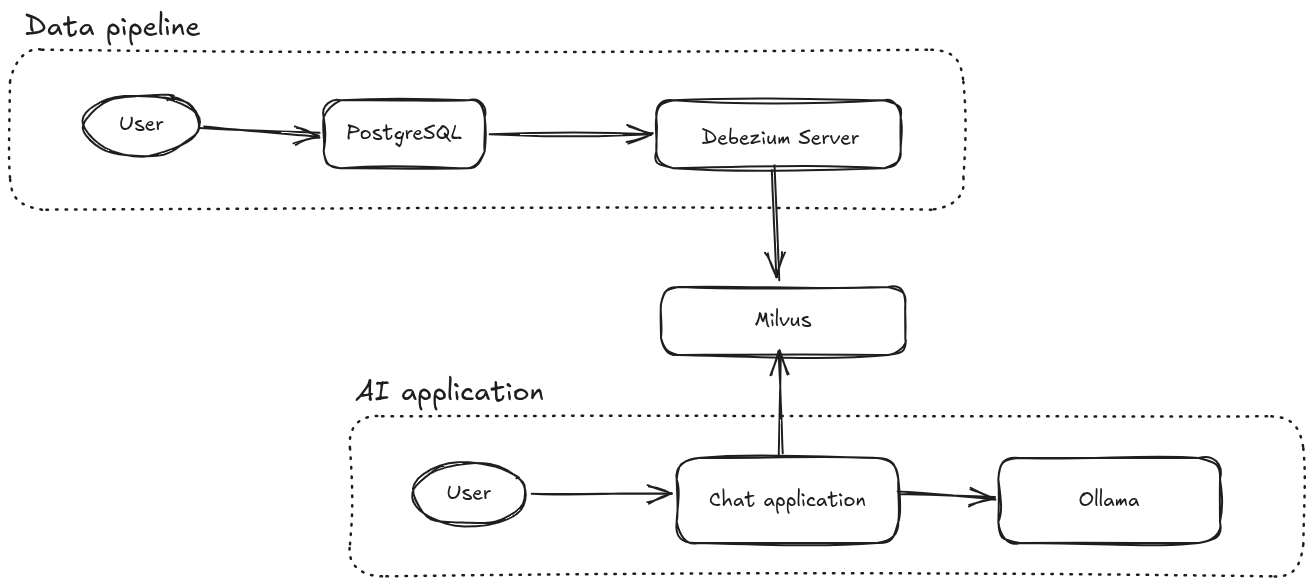
应用程序架构由以下两个流程组成,它们共享一个通用的 Milvus 实例:
-
数据管道
-
AI 应用程序
数据管道将数据摄取到 Milvus,而 AI 应用程序则查询 Milvus 以在数据中查找相似性。
数据管道
我们的组织从 arXiv 服务获取文档,该服务提供各种格式的学术文章供下载。测试应用程序根据文章标识符下载请求的文章,并将其存储在 PostgreSQL 表中。
PostgreSQL 表使用以下 DDL 创建:
CREATE TABLE documents (
id VARCHAR(64) PRIMARY KEY,
metadata JSON,
text TEXT
);
ALTER TABLE documents REPLICA IDENTITY FULL;表的 replica identity 设置为 FULL,因此 Debezium 在更新和删除消息中保留行的原始状态。我们的演示不需要保留原始行状态,但能够回溯原始状态对于某些实现很有用。
收到用户请求后,应用程序会下载文本格式的文档并将其存储在表中。Debezium 在事件的 id 字段中存储文档标识符;在 text 字段中存储文章的文本表示;并在元数据中存储 JSON 元数据 {"id:" "<document id>"}。该表不提供带有嵌入的列,因此 Debezium 必须使用其 FieldToEmbedding SMT(稍后描述)来计算它们。
在我们的环境中,我们运行一个基于 Ollama LLM 框架的本地 LLM。对于模型,我们选择了 granite3.1-dense:2b,这是一种针对 RAG 优化的纯文本模型。我们的模型是大型开源 IBM Granite 模型系列中的一个,但该应用程序不限于此,可以使用任意模型。
Debezium Server 在 PostgreSQL 存储和 Milvus Sink 之间提供了一个接口。由于未提供嵌入,我们可以使用 Debezium FieldToEmbedding SMT 来计算它们并将它们存储在一个名为 vector 的字段中。
在内部,我们的应用程序使用 Milvus 嵌入存储来处理 LangChain4j,因此我们保留以下 默认 Milvus 集合结构:
-
id-VarChar -
metadata-JSON -
text-VarChar -
vector-FloatVector
该模块中存在一个 已知问题,会导致在存储为空时应用程序失败。为了解决此问题,我们将一个占位符文档存储在数据库中(从而也存储在 Milvus 中)。
AI 应用程序
AI 应用程序与 LLM 交互,并根据提示与 Milvus 存储中嵌入的相似性来扩展提示。
演示应用程序是命令行驱动的,并使用 Quarkus 框架编写。对于 AI 功能,该应用程序使用 Quarkus 的 LangChain4j 扩展,特别是开源的 Ollama LLM 和用于 RAG 的 Milvus Store。
AI 服务通过 Debezium Chat 类注册。
package io.debezium.examples.airag;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
@RegisterAiService(retrievalAugmentor = MilvusRetrievalAugmentor.class)
public interface Chat {
@SystemMessage("You are an expert that provides short summaries.")
String chat(@UserMessage String message);
}您可以使用 application.properties 来配置模块。
quarkus.langchain4j.ollama.base-url=https://:11434 quarkus.langchain4j.ollama.chat-model.model-id=granite3.1-dense:2b quarkus.langchain4j.ollama.embedding-model.model-id=granite3.1-dense:2b quarkus.langchain4j.ollama.timeout=120s
RAG 通过 @RegisterAiService 注解上的 retrievalAugmentor 参数启用,并在 MilvusRetrievalAugmentor bean 中实现。
@ApplicationScoped
public class MilvusRetrievalAugmentor implements Supplier<RetrievalAugmentor> {
private final RetrievalAugmentor augmentor;
MilvusRetrievalAugmentor(MilvusEmbeddingStore store, EmbeddingModel model) {
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(3)
.build();
augmentor = new RetrievalAugmentorDecorator(DefaultRetrievalAugmentor
.builder()
.contentRetriever(contentRetriever)
.build());
}
@Override
public RetrievalAugmentor get() {
return augmentor;
}
private class RetrievalAugmentorDecorator implements RetrievalAugmentor {
private final RetrievalAugmentor delegate;
public RetrievalAugmentorDecorator(RetrievalAugmentor delegate) {
this.delegate = delegate;
}
@Override
public AugmentationResult augment(AugmentationRequest augmentationRequest) {
Log.infof("Requested augmentation of %s", augmentationRequest.chatMessage());
final var result = delegate.augment(augmentationRequest);
Log.infof("Result of augmentation is %s", result.contents());
return result;
}
}
}EmbeddingStoreContentRetriever 类查询 Milvus 向量数据库,并使用三个最相似的文档来增强提示上下文。该类还提供 RetrievalAugmentorDecorator,用于记录增强操作的详细信息。
您还可以使用 application.properties 来配置 Milvus 嵌入存储,如下例所示:
quarkus.langchain4j.milvus.host=localhost quarkus.langchain4j.milvus.port=19530 quarkus.langchain4j.milvus.create-collection=false quarkus.langchain4j.milvus.collection-name=demo_ai_documents # The following two settings are not supported by the current version of Quarkus Langchain4j extension # Also field with text cannot be overriden and is default text quarkus.langchain4j.milvus.primary-field=id quarkus.langchain4j.milvus.vector-field=vector
演示
该演示由以下两个组件组成:
-
一个 Docker Compose 配置文件,用于启动所有服务。
-
客户端目录中的一个 Java CLI 应用程序,它模拟数据管道和 AI 应用程序。
启动部署
在终端 1中,输入以下命令,然后等待容器启动。
$ docker-compose up --build
上述命令使用 debezium-ai-embeddings-ollama 模块扩展了标准的 Debezium Server 镜像(AI 嵌入模块默认不包含)。该命令还启动了 PostgreSQL (postgres)、Milvus (milvus)、Debezium Server (debezium-server) 和 Ollama (ollama) 容器。
在终端 2中,输入以下命令来启动 Granite LLM 模型:
$ docker exec -it ollama ollama run granite3.1-dense:2b
我们需要确保使用模型不知道的事实来测试应用程序。首先,我们将检查模型的截止日期(模型看到的最新数据是什么)。
>>> What is your cut off date? My knowledge cut off date is April 2024. I can provide information and answer questions based on data up to that point. For more recent events or discoveries, I'm unable to include those details in my responses as they weren't available at the time of my training data. If you have any questions within this timeframe, feel free to ask!
基于这一事实,我们选择了论文 2504.05309v1(IterQR:用于基于 LLM 的电子商务搜索系统查询重写的迭代框架)来代表应用程序的新知识。这篇论文于 2025 年 2 月发表,在截止日期之后,并且包含非常具体的关键字 IterQR。我们将通过询问该框架来测试模型。
>>> Describe IterQR framework in 20 words. Iterative Quantized Ridge Regression (IterQR), a scalable method for large-scale regression, iteratively refines coefficients via quantization and ridge regression techniques to minimize computational complexity while maintaining accuracy.
答案与该框架完全无关,并表现出幻觉的特征。模型不知道这个事实,所以它会捏造自己的信息,与现实毫无关联。当我们多次向模型提问时,它会提供不同且不相关的回答。
数据管道
我们将在终端 3中使用 Java 应用程序运行演示的其余部分。该应用程序是使用 Maven 构建的,因此我们首先运行以下命令:
$ cd client $ ./mvnw clean install
要启动应用程序,请运行 java -jar target/quarkus-app/quarkus-run.jar。
现在,我们使用集合和一个占位符记录来初始化 Milvus 存储(如前所述的已知问题)。记录不是直接插入的。相反,会在 PostgreSQL 源表中写入新行,然后通过 Debezium 将该行摄取到 Milvus 中。输入以下命令:
$ java -jar target/quarkus-app/quarkus-run.jar init
该命令返回以下输出(为提高可读性和清晰度,已删除部分日志):
... 2025-05-20 06:05:10,712 INFO [io.deb.exa.air.MilvusStore] (main) Created collection 'demo_ai_documents' with schema: CreateCollectionReq.CollectionSchema(fieldSchemaList=[CreateCollectionReq.FieldSchema(name=id, description=, dataType=VarChar, maxLength=64, dimension=null, isPrimaryKey=true, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=false, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null), CreateCollectionReq.FieldSchema(name=metadata, description=, dataType=JSON, maxLength=65535, dimension=null, isPrimaryKey=false, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=true, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null), CreateCollectionReq.FieldSchema(name=text, description=, dataType=VarChar, maxLength=65535, dimension=null, isPrimaryKey=false, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=false, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null), CreateCollectionReq.FieldSchema(name=vector, description=, dataType=FloatVector, maxLength=65535, dimension=2048, isPrimaryKey=false, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=false, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null)], enableDynamicField=false, functionList=[]) ...
接下来,输入以下命令以验证 Milvus 存储是否仅包含一个(占位符)文档。
$ java -jar target/quarkus-app/quarkus-run.jar list-milvus
...
2025-05-20 06:08:08,213 INFO [io.deb.exa.air.MilvusStore] (main) Milvus list results size: 1
2025-05-20 06:08:08,217 INFO [io.deb.exa.air.MilvusStore] (main) Document: {metadata={"id":"permanent"}, vector=[...], text=permanent, id=permanent}
... 应用程序管道
数据管道已建立,但尚未提供特定于域的知识。我们可以输入以下命令来检查模型是否仍在产生幻觉:
$ java -jar target/quarkus-app/quarkus-run.jar query-chat Describe IterQR framework in 20 words
模型显示以下输出:
2025-05-20 06:15:13,140 INFO [io.deb.exa.air.RagCommand] (main) Sending query: Describe IterQR framework in 20 words
2025-05-20 06:15:13,465 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Requested augmentation of UserMessage { name = null contents = [TextContent { text = "Describe IterQR framework in 20 words" }] }
2025-05-20 06:15:21,521 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Result of augmentation is [DefaultContent { textSegment = TextSegment { text = "permanent" metadata = {id=permanent} }, metadata = {SCORE=0.5046951323747635, EMBEDDING_ID=permanent} }]
2025-05-20 06:15:30,117 INFO [io.deb.exa.air.RagCommand] (main) Chat reply: Iterative QR factorization, a permanent matrix method, breaks down data into orthogonal matrices for efficient computations. 模型的回复显然与真实框架无关。RetrievalAugmentorDecorator 的日志显示了增强对发送到聊天消息的影响。文档 permanent 已添加到消息中。它是存储中的占位符记录,因此如果它在前三名匹配文档中,它将始终被添加。
数据管道现在处理新的域事实(arXiv 文档)。文档以文本形式从服务器下载并插入到 PostgreSQL 表中。Debezium Server 应将文档传播到 Milvus 存储。
$ java -jar target/quarkus-app/quarkus-run.jar insert-document 2504.05309v1
$ java -jar target/quarkus-app/quarkus-run.jar list-milvus
...
2025-05-20 06:25:00,203 INFO [io.deb.exa.air.MilvusStore] (main) Milvus list results size: 2
2025-05-20 06:25:00,206 INFO [io.deb.exa.air.MilvusStore] (main) Document: {metadata={"id":"2504.05309v1"}, vector=[...], id=2504.05309v1, text=# Title
IterQR: An Iterative Framework for LLM-based Query Rewrite in
e-Commercial Search System
# Authors
Shangyu Chen, Xinyu Jia, Yingfei Zhang, Shuai Zhang, Xiang Li, Wei Lin
# Abstract
The essence of modern e-Commercial search system lies in matching user's
intent and available candidates depending on user's query, providing
personalized and precise service. However, user's query may be incorrect due to
ambiguous input and typo, leading to inaccurate search. These cases may be
released by query rewr}
2025-05-20 06:25:00,240 INFO [io.deb.exa.air.MilvusStore] (main) Document: {metadata={"id":"permanent"}, vector=[...], id=permanent, text=permanent}... Milvus 存储现在包含关于 IterQR 框架的文档。请注意,默认情况下,我们将文档截断为 512 个字符,以便可以在没有 GPU 的计算机上使用演示。此行为由 DocumentDatabase 类和配置属性 debezium.rag.demo.document.truncate 控制。
现在,如果您重复查询,答案应该与真实描述相关。
$ java -jar target/quarkus-app/quarkus-run.jar query-chat Describe IterQR framework in 20 words
2025-05-20 06:30:36,703 INFO [io.deb.exa.air.RagCommand] (main) Sending query: Describe IterQR framework in 20 words
2025-05-20 06:30:37,014 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Requested augmentation of UserMessage { name = null contents = [TextContent { text = "Describe IterQR framework in 20 words" }] }
2025-05-20 06:30:44,775 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Result of augmentation is [DefaultContent { textSegment = TextSegment { text = "# Title
IterQR: An Iterative Framework for LLM-based Query Rewrite in
e-Commercial Search System
# Authors
Shangyu Chen, Xinyu Jia, Yingfei Zhang, Shuai Zhang, Xiang Li, Wei Lin
# Abstract
The essence of modern e-Commercial search system lies in matching user's
intent and available candidates depending on user's query, providing
personalized and precise service. However, user's query may be incorrect due to
ambiguous input and typo, leading to inaccurate search. These cases may be
released by query rewr" metadata = {id=2504.05309v1} }, metadata = {SCORE=0.5339204333722591, EMBEDDING_ID=2504.05309v1} }, DefaultContent { textSegment = TextSegment { text = "permanent" metadata = {id=permanent} }, metadata = {SCORE=0.5046951323747635, EMBEDDING_ID=permanent} }]
2025-05-20 06:31:08,067 INFO [io.deb.exa.air.RagCommand] (main) Chat reply: IterQR is an iterative framework for enhancing e-Commercial search system precision, addressing user query errors via continuous iterations of candidate selection based on language model outputs. 前面的日志显示了以下更改:
-
响应已使用 arXiv 文档进行增强。
-
答案与新事实相符。
但是,如果您在终端 2中再次查询模型,您将收到幻觉答案,因为它无法访问增强事实。
>>> Describe IterQR framework in 20 words. Iterative Quantized Ridge Regression (IterQR) is an efficient, iterative algorithm for large-scale linear regression that leverages quantization and ridge regression to reduce computational complexity while maintaining accuracy, offering a scalable approach for managing extensive datasets.
最后一步,让我们测试一下知识是否可以被遗忘。数据管道从 PostgreSQL 数据库中删除该文档。
$ java -jar target/quarkus-app/quarkus-run.jar delete-document 2504.05309v1
$ java -jar target/quarkus-app/quarkus-run.jar list-milvus
...
2025-05-20 06:40:02,797 INFO [io.deb.exa.air.MilvusStore] (main) Milvus list results size: 1
...
$ java -jar target/quarkus-app/quarkus-run.jar query-chat Describe IterQR framework in 20 words
...
2025-05-20 06:40:44,373 INFO [io.deb.exa.air.RagCommand] (main) Sending query: Describe IterQR framework in 20 words
2025-05-20 06:40:44,665 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Requested augmentation of UserMessage { name = null contents = [TextContent { text = "Describe IterQR framework in 20 words" }] }
2025-05-20 06:40:51,957 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Result of augmentation is [DefaultContent { textSegment = TextSegment { text = "permanent" metadata = {id=permanent} }, metadata = {SCORE=0.5046951323747635, EMBEDDING_ID=permanent} }]
2025-05-20 06:41:01,424 INFO [io.deb.exa.air.RagCommand] (main) Chat reply: Iterative QR (iterQR) is an algorithm for approximate singular value decomposition, efficiently computing sparse solutions to linear systems through iterative updates of the matrix representation.
... 删除文档后,我们观察到以下结果:
-
Debezium Server 捕获删除操作并将文档从 Milvus 存储中移除。
-
聊天查询未被增强。
-
回复再次出现幻觉。
停止演示
要结束演示部署,请输入以下命令:
$ docker-compose down
上述命令会终止所有终端中的容器。
结论
Debezium 使组织能够将其现有数据库直接插入现代检索增强生成 (RAG) 管道——无需修改源应用程序。这意味着所有的创新、实验和 AI 开发都可以并行进行,而不会干扰既定流程、合规控制或遗留架构。
这篇博文描述了如何将 Debezium 3.1 集成到 AI 工作流中,特别是使用检索增强生成 (RAG) 的工作流。Debezium 捕获数据库的实时变更,并将它们馈送到向量数据库。这些更新对于使 AI 系统保持最新、包含新鲜的特定领域数据至关重要。示例设置包括 PostgreSQL、Debezium Server、Milvus 和 Granite LLM(带有嵌入)。这种架构使您能够部署智能应用程序,这些应用程序能够提供准确、最新的信息。
将您公司的数据转化为竞争优势——无需重写一行生产代码。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。