
Debezium 项目以一个极其有趣且充满活力的 Debezium 3.1.0.Final 版本开启了 2025 年。此版本在多个连接器中包含大量新功能,支持 WebAssembly 和 Go 的转换,我们发布了首个官方的 Debezium 管理平台,两个全新的 Debezium Server sink 用于向量数据库和大语言模型,一个新的人工智能模块,以及更多!
在本帖中,我们将深入探讨 Debezium 3.1 中的所有变更,讨论新功能,并解释所有可能影响您升级过程的变更。一如既往,我们建议您阅读发布说明,了解所有已修复的错误、更新程序等。
重大变更
任何新软件发布都会带来一些重大变更。本次发布也不例外,因此让我们来讨论在升级到 Debezium 3.1.0.Final 之前需要注意的主要变更。
Debezium Core
本节介绍与 Debezium 核心相关的所有重大变更。这些重大变更通常会影响所有连接器和模块,应仔细审查。
事件 source 块现已版本化
Debezium 更改事件包含一个 source 信息块,用于描述更改事件来源的属性。源信息块是 Kafka Struct 数据类型,并且可以进行版本控制;但是,在旧版本的 Debezium 中,版本属性留空。
source 信息块现已版本化,并将设置为版本 1 (DBZ-8499)。随着未来实现的变更,版本将相应递增。
| 对于使用 Schema Registry 的用户,此更改可能会引入 Schema 兼容性问题。 |
稀疏向量逻辑类型重命名
PostgreSQL 扩展 vector (又名 pgvector) 提供各种向量数据类型的实现,包括一种名为 sparsevec 的数据类型。稀疏向量仅存储向量内已填充的键/值条目,排除设置为零的对,以最大限度地减少数据集的存储需求。
Debezium 3.0 引入了名为 io.debezium.data.SparseVector 的 SparseVector 逻辑类型。在评估其他关系数据库的实现后,我们确定该逻辑名称不足以实现其他稀疏向量类型 (DBZ-8585)。
为了解决此问题,我们将 PostgreSQL 连接器中的 io.debezium.data.SparseVector 类重新打包到 Debezium 的核心包中。我们还已将类重命名为 SparseDoubleVector,并将逻辑名称更改为 io.debezium.data.SparseDoubleVector,以与类名更改保持一致。
| 对于那些可能曾经使用过 |
Schema 历史配置默认值更改
schema.history.internal.store.only.captured.databases.ddl 的文档使用了不正确的默认值。虽然这不是代码层面的重大变更,但您应该花点时间重新评估您的部署配置是否依赖于不同的默认值 (DBZ-8558)。
Debezium 存储模块
JDBC 存储配置命名约定更改
JDBC 存储配置使用的配置属性名称不符合其他存储模块使用的约定。在 Debezium 3.1 中,我们调整了命名约定,同时在过渡期内保留了旧名称 (DBZ-8573)。以下显示了旧的配置属性名称以及您应计划迁移到的新命名。
| 旧属性名称 | 新属性名称 |
|---|---|
|
|
|
|
|
|
|
|
Debezium for Oracle
删除了几个 Oracle LogMiner JMX 指标
Debezium 2.6 中已弃用了多个 Oracle LogMiner JMX 指标,并用新指标替换。下表显示了已替换或删除的 JMX 指标。
| 已删除的 JMX 指标 | 替换项 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 已删除,无替换项。 |
请务必审查您的监控和可观察性基础架构,如果您仍依赖任何已弃用的指标,请相应调整 (DBZ-8647)。
Reselect column 后处理器行为已更改
ReselectColumnsPostProcessor 将重新选择 Oracle LOB 列,即使 lob.enabled 配置属性的值未启用。此更改使用户无需为 LOB 列启用流式传输,但仍可以通过列重新选择过程作为替代方案来填充 LOB 列 (DBZ-8653)。
查询超时现已应用于 Oracle LogMiner 查询
当 Oracle 连接器执行其初始查询以从 LogMiner 获取数据时,database.query.timeout.ms 连接器配置属性将控制查询的持续时间,直至查询被取消 (DBZ-8830)。升级时,请检查连接器指标 MaxDurationOfFetchQueryInMilliseconds 以确定此新属性是否可能需要调整。默认超时时间为 10 分钟,但设置为 0 时可以禁用。
Debezium for Vitess
潜在数据丢失
Debezium for Vitess 连接器存在一个罕见但关键的数据丢失 bug,自五年前首次引入以来一直存在。如果主键更新是事务中的最后一次操作,则可能丢失记录。此 bug 影响所有先前版本。强烈建议用户立即更新到 3.1 或更高版本以修复此潜在的数据丢失问题 (DBZ-8594)。
新功能和改进
以下描述了 Debezium 3.1.0.Final 中所有值得注意的新功能和改进。有关完整的列表,请务必阅读发布说明以获取更多详细信息。
Debezium Core
新的自适应时间精度模式
Debezium 一直支持各种 time.precision.mode 类型,例如 adaptive 和 connect。添加了三种新模式,为基于时间的列提供更多的自定义和选择 (DBZ-6387, DBZ-8826)。
| 模式 | 描述 |
|---|---|
| 配置连接器将时间值映射为 UTC 中的 ISO-8601 格式字符串。 |
| 配置连接器将时间值映射为微秒精度(如果可用)。 |
| 配置连接器将时间值映射为纳秒精度(如果可用)。 |
使用 microseconds 或 nanoseconds 基于的精度模式时,连接器将根据字段是 DATE、TIME 还是 TIMESTAMP 类型使用不同的语义类型。请查看您具体的连接器文档,了解连接器如何解释这些内容。
CloudEvent traceparent 支持
Debezium 的 CloudEvents 支持已更新,以支持 traceparent 属性,该属性提供了与 OpenTelemetry 集成的能力,以便将跟踪详细信息作为事件的一部分传递 (DBZ-8669)。
通过将 opentelemetry.tracing.attributes.enabled 配置属性设置为 true,并将 traceparent:header 作为 metadata.source 的一部分包含在内,这些信息将可用于 CloudEvents 转换器。
您可以通过更改默认值并指定适当标头中的字段值来定制转换器如何填充字段。例如
{
"value.converter.metadata.source": "value,id:header,type:header,traceparent:header,dataSchemaName:header"
}您可以在 Debezium 的CloudEvents 文档中找到其他示例。
使用 WASM 进行基于内容的路由/过滤
给定以下 Go 语言程序
package main
import (
"github.com/debezium/debezium-smt-go-pdk"
)
func process(proxyPtr uint32) uint32 {
var topicNamePtr = debezium.Get(proxyPtr, "topic")
var topicName = debezium.GetString(topicNamePtr)
return debezium.SetBool(topicName == "theTopic")
}
func main() {}此 Go 程序可以编译为 WebAssembly .wasm 文件,然后由 ContentBasedRouter 或 Filter 转换使用。以下示例显示了如何将其与 Filter 转换一起使用
{
"transforms": "route",
"transforms.route.type": "io.debezium.transforms.Filter",
"transforms.route.condition": "<path-to-compiled-wasm-file>",
"transforms.route.language": "wasm.chicory"
}在此示例中,如果事件的主题与 theTopic 匹配,则通过该事件,否则丢弃该事件。
有关更多信息,您可以查阅Filter SMT 和Content-based Router SMT 的文档。
TinyGo WASM 数据类型改进
Debezium 的脚本转换解决方案能够使用 Go 编写脚本,并将其编译为 WebAssembly。ChicoryEngine 运行时现在包括支持访问和处理 Struct、Map 和 Array Kafka Schema 类型。此外,还包括更具体类型的访问器,例如 Int8、Int16、Int32、Int64、Float32、Float64、Bool 和 Bytes。
package main
import ( "gihub.com/debezium/debezium-smt-go-pdk" )
//export process
func process(proxyPtr uint32) uint32 {
var op = debezium.GetString(debezium.Get(proxyPtr, "value.op"))
var beforeId = debezium.GetInt8(debezium.Get(proxyPtr, "value.before.id")) // Uses new GetInt8
// value.op != 'd' || value.before.id != 2
return debezium.SetBool(op != "d" || beforeId != 2)
}
func main() {}WASM 转换中的 Schema 访问支持
现在,您可以通过 WASM 转换在 TinyGo 程序中访问一些 Schema 详细信息 (DBZ-8737)。现已包含 GetSchemaName 和 GetSchemaType 方法,以支持读取特定的 Schema 详细信息。
package main
import( "githu.com/debezuim/debezium-smt-go-pdk" )
//export process
func process(proxyPtr uint32) uint32 {
var valueSchemaType = debezium.GetSchemaName(debezium.Get(proxyPtr, "valueSchema"))
var opType = debezium.GetSchemType(debezium.Get(proxyPtr, "valueSchema.op"))
// Filter where schema type or opType match
return debezium.SetBool(valueSchemaType == "dummy.Envelope" || opType == "string")
}
func main() {}| 我们欢迎您就如何改进 WASM 转换体验提供任何反馈。请通过我们的 Zulip 聊天联系我们,或在 Jira 上提交增强请求。 |
ExtractChangeRecordState 转换始终添加标头
ExtractChangeRecordState 转换用于添加用户配置的事件标头,这些标头描述了事件负载中哪些字段已更改或哪些字段未更改。但是,当此转换与其他需要标头存在的转换配对时,可能会导致意外行为。虽然用户可以通过 Kafka 单个消息转换谓词来规避此限制,但我们认为我们所做的任何努力来帮助最小化配置膨胀都是有益的。
现在,ExtractChangeRecordState 将始终将更改和未更改的标头添加到您的事件中,即使该事件是插入或删除,即使这些字段为空 (DBZ-8855)。
| 如果您的管道依赖于 |
Reselect column 后处理器的错误处理模式
ReselectColumnsPostProcessor 旨在补充流式传输过程,根据连接器配置查询需要重新选择的特定列的当前值。此过程旨在无缝进行,并且如果查询失败,将把流式传输的列数据作为最后手段。
已添加以下配置属性
reselect.error.handling.mode-
指定如何处理重新选择查询失败时的错误。将其设置为
warn,当重新选择查询失败时会记录警告,并按原样传递流式传输的事件数据。将其设置为fail,当重新选择查询失败时连接器将抛出异常。
reselect.error.handling.mode 的默认值为 warn,以保留旧的预期行为 (DBZ-8336)。
集中记录敏感数据
我们理解数据库包含各种信息,并且某些列可能包含敏感信息。我们很自豪能确保信息保持安全。因此,我们通常倾向于避免在 INFO、WARN 或 ERROR 级别记录敏感信息。
但是,存在一些潜在的极端情况,敏感列值可能会在 DEBUG 或 TRACE 级别记录。我们几年前添加了 io.debezium.util.Loggings 类来集中处理此问题,但并非所有实例都使用了此 Loggings 类 (DBZ-8525)。
默认情况下,用户会注意到 Loggings 类将在日志中记录敏感信息,而不是将其包含在后续日志条目中的原始记录器中。如果您希望省略敏感信息,可以使用日志配置为 io.debezium.util.Loggings 设置特定日志级别。
例如,如果您需要将日志提供给某人但希望省略敏感信息,则以下配置可以实现此目标。
log4j.logger.io.debezium=TRACE,stdout
log4j.logger.io.debezium.util.Loggings=ERROR,stdout此配置将在记录所有非敏感信息(以 TRACE 级别)的同时,省略所有敏感信息。
Debezium 存储模块
显式使用 S3 存储的路径样式寻址
S3 SDK 在 2.18+ 中引入了一个小的行为更改,即 URL 是使用虚拟主机样式而不是路径样式构建的,正如在上游 S3 SDK 社区中所讨论的。虽然 S3 存储桶支持这两种 URL 样式,但在某些情况下,包括测试用例,虚拟主机样式可能尚不支持。
我们添加了一个新的配置选项 schema.history.internal.s3.forcePathStyle,其默认值为 false (DBZ-8569)。在您可能需要路径样式 URL 而非虚拟主机样式 URL 的情况下,将其设置为 true 将恢复旧的 URL 行为。
Debezium for MariaDB
SSL 支持
我们为 MariaDB 引入了几种新的特定模式,旨在允许 MariaDB 连接器使用与 MariaDB 驱动程序兼容的 SSL 连接 (DBZ-8482)。下表描述了这些模式以及如果您从旧的 MySQL 连接器部署迁移到新的独立 MariaDB 连接器时的 MySQL 等效项。
| 模式 | 描述 |
|---|---|
| 禁用 SSL/TLS 连接的使用。所有连接都不安全。这相当于 MySQL 的 |
| 使用 SSL/TLS 进行加密,但不执行证书或主机名验证。这相当于 MySQL 的 |
| 使用 SSL/TLS 进行加密并执行证书验证,但不进行主机验证。这相当于 MySQL 的 |
| 使用 SSL/TLS 进行加密并执行证书和主机验证。这相当于 MySQL 的 |
对于 MariaDB,这些属性通过 database.ssl.mode 属性传递。
Debezium for MySQL
Percona 最小化锁定
为 Debezium for MySQL 的 Percona 用户添加了一个新的 snapshot.locking.mode,减少了快照期间发生的锁。新模式 minimal_percona_no_table_locks 提供了与 minimal_percona 相同的语义,但另外省略了表级锁的应用 (DBZ-8717)。这为某些不允许表锁的环境提供了一种替代方案。
改进重复服务器 ID/UUID 的错误处理
对于大多数连接器,Debezium 遵循重试所有 SQLException 或 IOException 相关失败的原则。此策略非常有用,允许用户根据需要利用运行时重试机制。
但是,对于 MySQL,这会带来一个独特的极端情况,即配置的服务器 ID/UUID 存在冲突。MySQL 使用服务器 ID/UUID 来唯一标识集群拓扑中的实例。如果多个服务器使用相同的 ID/UUID,实例将抛出 SQLException 并在启动时进入重试/回退循环。
我们调整了错误处理,以便为此特定唯一情况优先采用快速失败方法 (DBZ-8786)。如果您是 MySQL 用户,并且发现您的连接器频繁进入 FAILED 状态,我们建议您检查此用例是否适用于您。如果是,您应该确保您的配置始终使用唯一的服务器 ID/UUID 值。
Debezium for Oracle
新的 Oracle LogMiner JMX 指标
我们添加了一个新的 Debezium Oracle 连接器 JMX 指标 MinedLogFileNames。此指标返回一个字符串数组 (String[]),其中包含当前 LogMiner 会话中正在读取的日志文件名 (DBZ-8644)。
| 当用户报告 Oracle 连接器有延迟时,我们首先检查的是在挖掘会话中有多少日志被读取。当添加异常多的日志时,这可能会在 Oracle LogMiner 读取所有这些日志磁盘数据时造成瓶颈。 此指标提供了对挖掘日志数量的可视性,而无需调整连接器的日志级别。如果您观察到延迟,首先要检查此指标中有多少日志。 大量的日志通常表示您的数据库可能存在高突发活动窗口。 |
新的源信息 scn 和时间戳字段
为 Oracle 更改事件的 source 信息块添加了几个新字段 (DBZ-8740)。这些新源字段包括
commit_ts_ms-
这指定了事件事务提交的时间(以毫秒为单位)。
start_scn-
这指定了事件事务中第一个事件的 SCN。
start_ts_ms-
这指定了事件事务中第一个事件被用户更改的时间(以毫秒为单位)。
这些新字段是可选的,因此 Schema Registry 用户会发现这些更改是向后兼容的。
| Oracle SCN 值不是唯一的,因此多个事件可能具有相同的 SCN 值和时间戳。在使用这些值进行任何类型的事件排序时应小心。 |
Debezium for SQL Server
流式内存改进
Microsoft SQL Server 驱动程序在同一连接上执行多个 SELECT 时无法多路复用。这通常会导致所有数据缓冲到内存中,这可能非常低效或导致内存问题。
Debezium 引入了一个新的配置选项 streaming.fetch.size 来帮助解决此 SQL Server 驱动程序限制 (DBZ-8557)。此配置选项指定在流式传输期间应从每个表中一次读取的最大行数。默认情况下,此值为 0,因此连接器行为保持不变。设置为正值时,这会导致多次与数据库进行数据往返,以根据配置的获取大小分批获取数据。
如果可用,始终使用聚集索引
当 data.query.mode 设置为 direct 时,查询的 ORDER BY 可能经常性能不佳,因为查询没有利用捕获表的聚集索引。这通常需要自定义数据库索引才能获得良好的性能。
我们调整了查询以考虑这一点,现在将 __$command_id 作为结果集 ORDER BY 子句的一部分 (DBZ-8858)。这使得数据库可以使用聚集索引,并大大降低了查询成本,从而在没有任何数据库索引自定义的情况下实现了整体更好的性能。
Debezium for Vitess
将二进制排序字符串数据类型发出为 Kafka 字符串
在早期版本中,作为 DBZ-6748 的一部分,我们将具有二进制排序的 varchar 列类型更改为 Kafka 字符串类型。但是,其他字符驱动的数据类型,如 text、tinytext、mediumtext、longtext、enum 和 set 被忽略了,它们继续被序列化为字节数组。
| 请注意,如果您使用 Schema Registry,具有二进制排序的这些列类型的序列化方式的更改可能会导致 Schema 向后兼容性问题。 |
Epoch/Zero 日期列解析的更改
当日期列为零日期值时,取决于列的可选性,该字段可能被发出为 null 或 Unix Epoch。这导致消费者无法解析,因为当提供 Epoch 值时,它们无法区分它是否代表真实 Epoch 值还是代表源系统中零日期的哨兵。
为了解决此问题,我们添加了 override.datetime.to.nullable 配置属性。当设置为默认值 false 时,此类场景将继续使用旧行为,在列不可为空但包含零日期时发出 Unix Epoch。这意味着消费者将继续无法区分这两种用例。
当设置为 true 时,所有日期和日期时间列都设置为可选,并以 null 序列化,如果列的值代表零日期。这允许消费者轻松区分用例并更恰当地处理它们。
Keyspace 心跳支持
在 Vitess 版本 21 中,为 VStream 引入了一种新的 binlog 水位线策略。此新功能发送一个“心跳”事件,表示直到提供的时间戳的 shard binlog 事件已被 VStream 客户端接收。
一个新的配置选项 vitess.stream.keyspace.heartbeats 可以设置为 true,以包含写入 keyspace 心跳表的心跳事件 (DBZ-8775)。table.include.list 还应包含心跳表,格式为 <keyspace>.heartbeat。
改进的入队速度
在对连接器进行性能测试时,确定了几个在每次事件分发时都会不必要地执行的操作,浪费了宝贵的 CPU 周期。这导致内部队列经常为空的情况,限制了连接器的整体吞吐量。
这些代码热点现在使用缓存值来最大限度地减少浪费的 CPU 周期。缓冲区现在在负载下保持满载,并且性能是先前观察到的两倍 (DBZ-8757)。
查询指定工作负载标签
大多数查询现在都包含 SQL 提示/注释 /*vt+ WORKLOAD_NAME=debezium */,以标识该查询是由 Debezium 连接器执行的 (DBZ-8861)。
Debezium JDBC Sink
支持 MySQL/PostgreSQL 向量数据类型
我们在 Debezium 3.0 中引入了各种向量数据类型(2024 年底),其中包括 MySQL/PostgreSQL 的 vector 和 PostgreSQL 的 halfvec/sparsevec。通过 Debezium 3.1,我们将这些数据类型的支持扩展到了 JDBC Sink 连接器 (DBZ-8571)。
此新映射包含几条规则
-
MySQL 到 MySQL 或 MySQL 到 PostgreSQL,
vector数据类型会自动映射。 -
PostgreSQL
vector到 PostgreSQL 或 MySQL,vector数据类型会自动映射。 -
如果目标是 PostgreSQL,则会自动映射
halfvec和sparsevec的复制。
对于没有向量数据类型原生映射或不支持此类类型的目标数据库,无法将该字段原生写入目标系统。对于这些用例,您可以使用 io.debezium.transforms.VectorToJsonConverter 转换来在飞行中将事件负载更改为 JSON 表示形式,大多数数据库普遍支持 JSON。目标数据库中的目标列类型将是 json、clob 或基于文本的列类型,具体取决于数据库供应商。
随着对更多源数据库向量类型的支持,我们将继续在未来扩展这一点。
性能改进
我们收到多个社区报告,称在高峰时期,一些数据库经历了异常高的 CPU 利用率。经过调查,我们发现执行了过多的 SQL 查询,导致 CPU 过高并降低了连接器的写入吞吐量 (DBZ-8570)。用户现在应该发现 JDBC Sink 的写入吞吐量更高,CPU 利用率应比以前更合理。
连接错误自动重试
对于 Kafka Connect producer,如果连接器抛出 RetriableException 并且 Kafka Connect 配置为支持错误重试,则运行时将自动停止并重新启动连接器。这提供了一种处理资源拆卸和重新创建(如数据库连接)的有用方法。
但是,对于 Kafka Connect consumer (sink),连接器的生命周期工作方式不同。当连接器抛出错误时,生命周期不会停止并重新启动连接器,而是再次调用 put 方法。在某些连接错误的情况下,这可能会有问题,因为某些资源不会自动重新创建。
从 Debezium 3.1 开始,一个新的 JDBC Sink 连接器属性 connection.restart.on.errors 将允许 JDBC Sink 重试连接失败 (DBZ-8727)。
为 SQL Server 目标处理 BYTES 作为 VARBINARY
已添加一个新的 JDBC Sink 映射,用于将 Kafka BYTES 字段转换为 VARBINARY 列数据类型 (DBZ-8790)。这允许将未知或二进制数据序列化为 Kafka BYTES 字段的源连接器正确映射到具有 VARBINARY 列数据类型的 SQL Server 目标。
Debezium 服务器
新的 Milvus Sink
Milvus 是一个开源向量数据库,专为搜索和检索高维数据(如机器学习模型的嵌入)而设计。您可以使用 Milvus 处理从源数据库捕获的向量数据类型,或将其与转换结合使用以从消息字段计算向量,然后将它们用作嵌入。
Milvus Sink 会摄取传入的消息,并将 Debezium 更改事件的 after 部分 upsert 到集合中。当观察到 Debezium 删除更改事件时,会从集合中删除匹配的记录 (DBZ-8634)。
要开始使用此新 Sink,可以指定以下配置
debezium.sink.type=milvus
debezium.sink.milvus.url=https://:19530
debezium.sink.milvus.database=default此外,您还可以通过应用自定义逻辑来修改 Milvus Sink 的行为,该逻辑为特定函数提供替代实现。这些扩展点包括
io.milvus.v2.client.MilvusClientV2.MilvusClientV2-
一个自定义 MilvusClientV2 客户端实例,该实例配置为访问目标集合。
io.debezium.server.StreamNameMapper-
自定义实现,用于映射目标主题的名称到 Milvus 集合。默认情况下,名称中的点将被替换为下划线。
您可以在 Milvus 文档或 Debezium 文档中找到更多信息。
新的 Instructlab Sink
InstructLab 是一个开源项目,旨在通过社区驱动的方法来增强大型语言模型 (LLM) 的技能和知识培训,从而实现生成式 AI 的民主化。这使用了称为 LAB(大规模聊天机器人对齐)的技术。
InstructLab Sink 会摄取传入的消息,并根据对负载字段的映射生成一系列问题和答案,以及可选的上下文值,然后近乎实时地更新您的分类技能和知识领域 (DBZ-8637)。
要开始使用此新 Sink,必须指定几个关键类型的配置。
{
"debezium.sink.type": "instructlab",
"debezium.sink.instructlab.taxonomy.base.path": "/mnt/ilab/taxonomy",
"debezium.sink.instructlab.taxonomies": "domainA,domainB",
"debezium.sink.instructlab.taxonomy.domainA.topic": ".*",
"debezium.sink.instructlab.taxonomy.domainA.question": "header:question",
"debezium.sink.instructlab.taxonomy.domainA.answer": "header:answer",
"debezium.sink.instructlab.taxonomy.domainA.domain": "a/subdir-a/subpath-a2/",
"debezium.sink.instructlab.taxonomy.domainB.topic": "my_topic",
"debezium.sink.instructlab.taxonomy.domainB.question": "value:field",
"debezium.sink.instructlab.taxonomy.domainB.answer": "value:field",
"debezium.sink.instructlab.taxonomy.domainB.context": "value:context",
"debezium.sink.instructlab.taxonomy.domainB.domain": "b/subdir-b/"
}分类映射都使用 debezium.sink.instructlab.taxonomy.* 命名空间定义。这些映射使用命名键,就像转换一样,为给定的分类定义一组配置映射。每个分类映射定义一个 question、一个 answer 以及一个可选的 context 配置,该配置定义了值将在事件中的哪个位置用于分类映射的该部分。
每个分类域映射可以应用于一个或多个事件,具体取决于域的 topic 配置属性。这定义了一个用于匹配事件主题的正则表达式。默认值为 .*,因此如果您省略 topic 配置属性,该映射将始终应用于所有传入事件。
最后,domain 配置属性指定了一个以 / 分隔的目录列表,该列表将附加到 taxonomy.base.path 属性,该属性唯一标识 Sink 将创建或更新 qna.yml 文件(使用源映射值)的目录。
您可以在 InstructLab 文档或 Debezium 文档中找到更多信息。
Pulsar 基于键的批处理支持
我们为使用 Apache Pulsar 的 KeyShared 订阅添加了一种新的、改进的吞吐量选项。配置选项 debezium.sink.pulsar.producer.batchBuilder 可以设置为 KEY_BASED,但默认为 DEFAULT (DBZ-8563)。
当设置为使用 KEY_BASED 时,此订阅模型会将具有相同键的消息按顺序仅传递给一个消费者。有关 Key_Shared 订阅模型的更多信息,请参阅Apache Pulsar 文档。
PubSub Sink 支持并发和压缩
为了提高 Google PubSub 的吞吐量和容量,我们引入了指定多个新配置属性的能力,以支持并发和压缩 (DBZ-8715)。这些新配置属性可用于任何现有的 PubSub 配置。
pubsub.concurrency.threads-
这指定了用于将消息发布到 Google PubSub 的线程数。这可用于扩展或限制 Google PubSub 客户端库创建的 PubSub 线程数。默认情况下,PubSink 使用客户端库的默认行为。
pubsub.compression.threshold.bytes-
当设置为
0或更高值时,PubSub Sink 会启用可选的压缩功能,用于将事件批次传输到 PubSub 端点。是否使用压缩由提供的阈值定义。如果批次的总字节数小于阈值,则不使用压缩。如果批次的总字节数等于或大于阈值,则使用压缩。
PubSub Sink 支持本地化端点
在使用 PubSub Sink 时,pubsub.address 通常不足以满足生产系统,在这些系统中,您可能需要与特定位置(又称区域)的端点进行交互。为了解决此问题,我们引入了一个新的配置属性 pubsub.region (DBZ-8735)。
新的 pubsub.region 属性允许指定要连接的 Google Cloud 区域,例如 us-central1 或 asia-northeast1。指定后,Debezium 将使用 PubSub 的本地化端点,格式为 <region>-pubsub.googleapis.com:443。这允许连接到本地化端点而不是全局端点。
|
|
RabbitMQ Sink 支持基于键的路由
我们改变了您通过配置路由事件的方式。这种新方法使用基于策略的设计,该设计保留了旧行为并引入了新的基于键的路由机制 (DBZ-8752)。
首先,rabbitmq.routingKeyFromTopicName 已弃用,将在未来版本中删除。此功能已合并到新的 rabbitmq.routingKey.source 配置属性中,可以设置为以下值之一
static-
当使用静态路由源时,RabbitMQ Sink 将使用您在 Sink 配置中指定的
rabbitmq.routingKey静态值。由于此值在配置中设置,并且仅在 Sink 启动期间读取,因此该值是静态的,在 Sink 运行时不会改变。 topic-
当使用主题路由源时,RabbitMQ Sink 将根据目标主题名称源化路由键。此模式取代了旧的
rabbitmq.routingKeyFromTopicName配置属性行为,该属性现已弃用。 key-
当使用新的键路由源时,RabbitMQ Sink 将根据事件的记录键源化路由键。这提供了灵活性,可以通过使用自定义转换在将事件发送到 RabbitMQ 之前更改事件键,来控制 RabbitMQ 的路由机制,使用原始 Debezium 更改事件的键。
Debezium 平台
什么是 Debezium Platform?
一年前,我们开始了非凡的旅程,为 Debezium Server 创建了一个新的、现代化的用户界面,旨在简化 Debezium 在 Kubernetes 上的部署。我们很高兴 Debezium 3.1 是这项多年努力的第一个正式版本。
新的 Debezium Platform 提供了一种现代化的基于管道的方法,可在几秒钟内设计源和 Sink 配置、转换链等。您可以使用 helm 如下安装 Debezium Platform
helm install debezium-platform --set domain.url=<your-domain> --version 3.1.0-final oci://quay.io/debezium-charts/debezium-platform有关如何使用 helm 进行部署的更多详细信息,请参阅README.md。
此外,本次发布特别为用户界面添加了一些收尾工作,包括新的搜索/列表视图切换、显示应用的转换和连接器管道的编辑,以及在配置管道期间的经验丰富用户智能编辑器。
以下视频展示了如何使用这些新功能
转换 UI 中的谓词支持
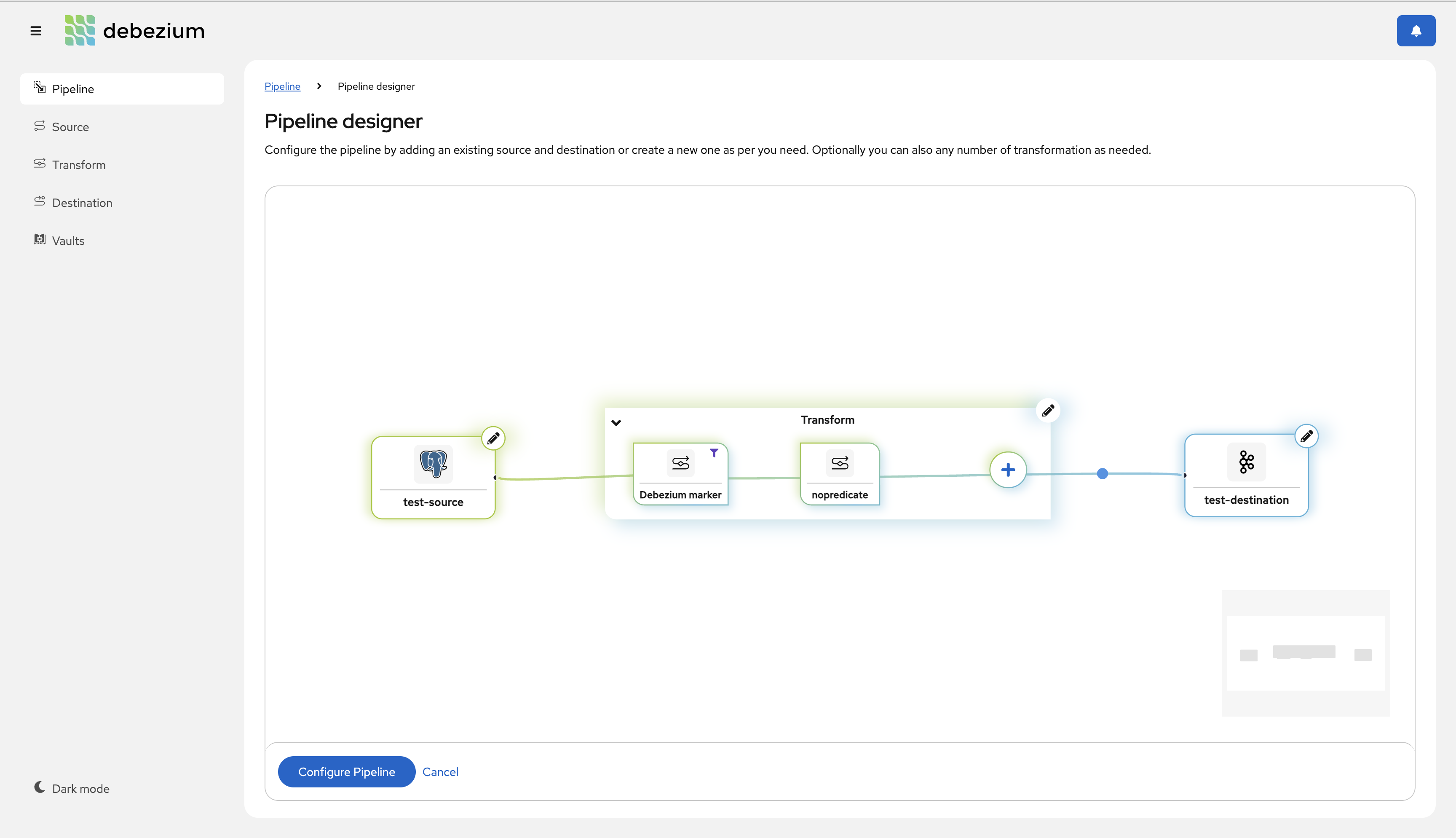
团队一直在努力改进新的和即将推出的 Debezium Management Platform,这是一个用于 Kubernetes 上 Debezium 部署的现代化管理界面。
在此版本中,我们很高兴地宣布,我们已在单个消息转换接口中添加了对定义谓词的支持。下面是这个新接口的快速预览 (DBZ-8590)。
夜间容器镜像
我们已开始发布 Debezium Management Platform 的夜间镜像,这是一个用于 Kubernetes 上 Debezium 部署的现代化管理界面 (DBZ-8603)。
quay.io/debezium/platform-conductor:nightly-
提供管理 API 的后端服务,用于编排和控制 Kubernetes 上的 Debezium 部署。可以使用
docker pull quay.io/debezium/platform-conductor:nightly获取该镜像。 quay.io/debezium/platform-stage:nightly-
提供用户界面以与基于 conductor 的后端进行交互的前端。可以使用
docker pull quay.io/debezium/platform-stage:nightly获取该镜像。
有关更多信息,请参阅README.md。
| 虽然这些容器不适合生产使用,但它们是探索 Debezium Management Platform 的绝佳方式。我们对这个新组件非常兴奋,并希望听到您的反馈。 |
Debezium AI
引言
Debezium AI 模块是 Debezium 3.1 的全新组件。该模块的目标是包含 Debezium 产品组合中的所有 AI 相关行为、实用程序等。
如果您有兴趣在自己的项目中使用 Debezium Embedded 来包含 Debezium AI 模块,该模块可通过将以下 POM 导入您的项目来获得
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-ai</artifactId>
<version>3.1.0.Final</version>
<type>pom</type>
</dependency>基于 LangChain4j 的 Embeddings 转换
作为 Debezium AI 模块的第一个功能之一,是基于 Langchain4j 的 Embeddings 转换。此 SMT 使用基于配置的方法来定义提供给您选择的大型语言模型 (LLM) 的输入值,并将生成的 embeddings 字段附加到事件的负载中 (DBZ-8702)。
- MiniLM
-
all-MiniLM-L6-v2模型是一个 sentence-transformer,它将句子和段落映射到一个 384 维的稠密向量。这些向量可用于聚类、语义搜索或比较等任务。
要将 MiniLM 的 embeddings 转换添加到您的转换链中,只需添加以下内容{ ..., "transforms": "minilm", "transforms.minilm.type": "io.debezium.ai.embeddings.FieldToEmbedding", "transforms.minilm.field.source": "after.documentation", "transforms.minilm.field.embedding": "after.embedded_documentation" }在此示例中,
after.documentation字段将提供给 MiniLM 模型,向量结果将添加到事件的after.embedded_documentation字段中。embeddings 字段将使用 Debezium 语义类型io.debezium.data.vector.FloatVector,其中包含一系列 32 位浮点值。 - Ollama
-
Ollama 是一个开源解决方案,允许在本地运行、创建和共享大型语言模型 (LLM),提供了一种经济高效的云端 AI 服务替代方案。
要将 Ollama 的 embeddings 转换添加到您的转换链中,只需添加以下内容{ .... "transforms": "ollama", "transforms.ollama.type": "io.debezium.ai.embeddings.FieldToEmbedding", "transforms.ollama.embeddings.ollama.url": "<url-to-ollama>", "transforms.ollama.embeddings.ollama.model.name": "<model-name>", "transforms.ollama.embeddings.field.source": "after.documentation", "transforms.ollama.embeddings.field.embedding": "after.embedded_documentation" }在此示例中,
after.documentation字段将提供给 Ollama 模型,向量结果将添加到事件的after.embedded_documentation字段中。embeddings 字段将使用 Debezium 语义类型io.debezium.data.vector.FloatVector,其中包含一系列 32 位浮点值。
| Debezium AI Embeddings 实现使用 Java ServiceLoader 从类路径加载特定的实现。您应该确保类路径上只有一个 Embeddings 依赖项,以保证转换使用正确的实现。 |
容器镜像
在 connect-base 镜像中条件性包含组件
Debezium 的 kafka 和 connect 镜像均源自一个名为 connect-base 的通用镜像。默认情况下,此基础镜像安装 Apicurio、Jolkia 和 OpenTelemetry 依赖项。这对于测试目的来说很棒,但如果您希望使用 Debezium 的镜像作为您自己镜像的基础,您可能希望省略这些不必要的依赖项。
connect-base 镜像现在可以根据条件性地省略这些依赖项中的任何一个 (DBZ-8709)。可以通过将 OTL_ENABLED、APICURIO_ENABLED 和 JOLOKIA_ENABLED 环境变量设置为 no 来在构建镜像时省略这些依赖项,从而减小镜像的占用空间。
|
|
Debezium 示例
Debezium 针对 GraalVM 进行了优化
Change Data Capture (CDC) 在各种场景中得到广泛应用,例如微服务通信、遗留系统现代化和缓存失效。此模式的核心思想是检测和跟踪数据源(例如数据库)中的更改,并近乎实时地将它们传播到其他系统。Debezium 是一个 CDC 平台,为大多数数据源提供了广泛的连接器。除了捕获更改外,它还通过直观的 UI 提供转换功能,用于定义 Debezium 实例。
请查看我们最近的博文Superfast Debezium,其中介绍了使用 GraalVM 的 Debezium 的最新示例!
总结
非常感谢社区中所有辛勤工作的贡献者为这个版本付出的努力
Yevhenii Lopatenko, Alvar Viana, Andrea Peruffo, Andrei Leibovski, Anisha Mohanty, Bhagyashree Goyal, Kunal Bhatnagar, Chris Cranford, Christian Seki, Dongwook Chan, Enzo Cappa, Eric Xiao, Fan Yang, Franz Emberger, Gaurav Miglani, Giovanni Panice, Guangnan Shi, Gunnar Morling, Gustavo Lira, Henk van Dyk, Hossein Torabi, Indra Shukla, Jakub Cechacek, James Johnston, Jean Vintache, Jiri Pechanec, Jon Bruno, Jonas Thelemann, Jose Carvajal Hilario, Juanma Barea, Julien Roy, Katerina Galieva, Katsumi Miyajima, Kavya Ramaiah, Krzysztof Grzechnik, Lars M. Johansson, Mario Fiore Vitale, Markus Kull, Martin Vlk, Martin Walsh, Michael Cambria, Minjae Lee, Minjae Lee, Naresh Gandi, Nathan Smit, Ole-Martin Bratteng, Ondrej Babec, P. Aum, Philippe Labat, Rajendra Dangwal, René Kerner, Robert Roldan, Rodolphe Quiedeville, Roman Kudryashov, Sergey Seroshtan, Stanislav Deviatov, Stefan Miklosovic, Thomas Thornton, Timo Schmidt, Vadzim Ramanenka, Victor Castaño, Vojtěch Juránek, Yannick Eisenschmidt, Yuriy Vikulov, Zakariae Ben Allal, Zhongqiang Gong, dario, ismail simsek, kesompochy, and حمود سمبول!
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。