
大家好,我是 René,一家瑞士保险公司的数据工程师。在过去的四年里,我一直在多个项目中使用 Debezium。由于我不是 Java 开发者,这些年来我一直没有机会为 Debezium 贡献任何代码。尽管如此,或者正是因为如此,我想我至少可以写一些关于一个对我们公司乃至可能不止我们公司都非常重要的话题:快照性能。
初始快照过程的持续时间对我们至关重要。我们的管道(实时 ETL)将数据从各种 Oracle 数据库流式传输到企业数据仓库的登陆区。就最大的数据库而言,我们谈论的是 1.5 TB 的数据量需要泵入数据仓库。这是一个巨大的数据量。但这还不是全部:由于我们从中摄取数据的数据库经常发生结构性变化,我们不得不相当频繁地进行快照(每年 4 到 5 次)。不幸的是,这些快照是不可避免的,因为——除了其他原因——我们也处理 LOB 字段。
我们喜欢挑战。我们的目标是达到与我们替换新实时管道的旧批处理过程相似的快照时间。换句话说,目标设定得很高。
我们的环境概览
在直接进入测试结果之前,我想阐明一些关于我们环境的相关事实
源数据库
-
Oracle 19c,本地部署,CDB
-
DB 主机具有 6 GB/s 的 I/O 带宽,该带宽由运行在该主机上的所有数据库共享
-
临时表空间包含 42 个文件,每个文件 32 GB,由数据库上运行的所有进程共享。
注意:如果并行线程过多且数据量大(例如,在覆盖语句中对大表使用 ORDER BY 子句),可用空间可能会达到极限
Kafka Connect
-
3 个节点,本地 RHEL 虚拟机,每个节点有 12 个 CPU,62 GB RAM,40 GB JVM
-
Kafka CP 7.7.1
-
Debezium 3.0,部署在 KC 上
监控
-
Prometheus 和 Grafana
测试结果
在我的测试中,我主要关注与性能相关的属性。这些是
Debezium 端
snapshot.max.threads
snapshot.fetch.size
max.batch.size
max.queue.size
poll.interval.ms
Kafka Connect 端
batch.size
linger.ms
compression.type
我在测试中尝试了这些属性,并获得了有趣的见解。在此,我已透露在我们案例中被证明最有效的设置
producer.override.batch.size: 1000000,
producer.override.linger.ms: 500,
producer.override.compression.type:lz4,
通过使用这些设置,我们实现了 25% 的优化:从最初的 8 小时,我们将完整快照的时间缩短到 6 小时(参见图 1)。在整个快照过程中,CPU 消耗和 JVM 内存使用量从未超过 80%。
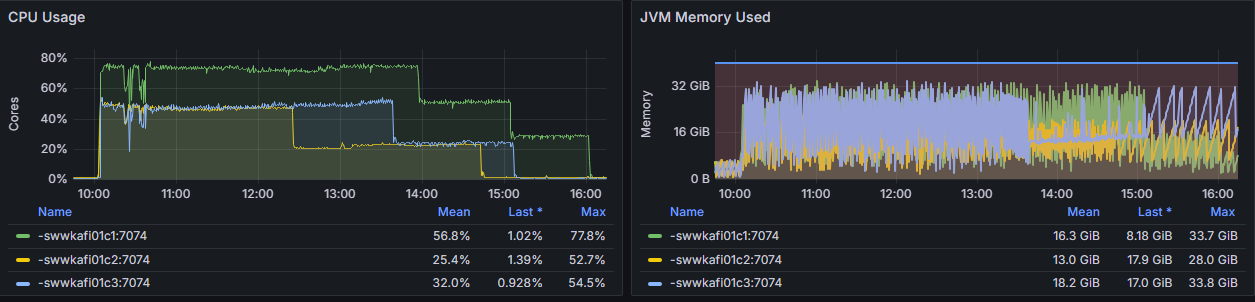
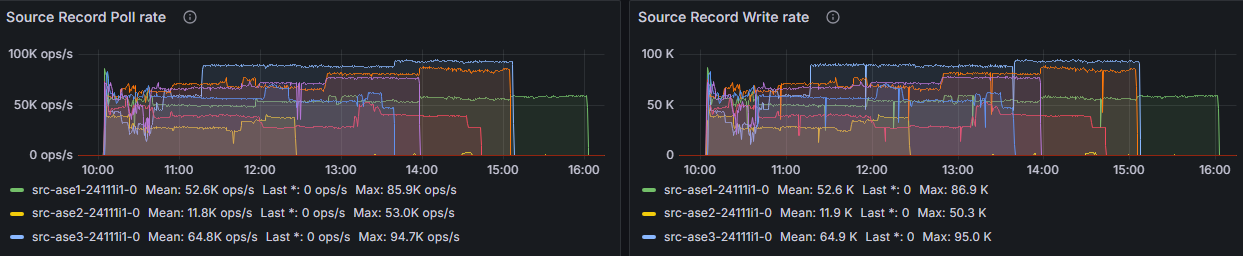
我特别观察的一个指标是*源记录轮询率*。在我的测试中,这个指标作为性能好坏的有用初步指示器。如图 2 所示,高达 90k 次/秒的速率被证明是极限。无论如何,我都无法达到更高的速率。同样重要的是查看其相邻指标*源记录写入率*,它应该显示几乎相同的图表
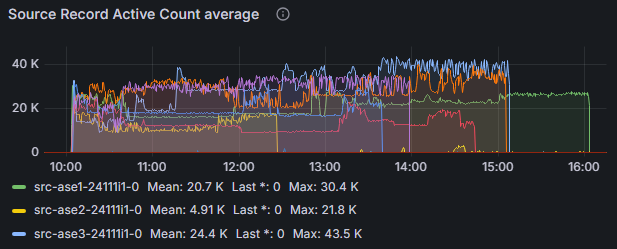
如果轮询正常但推送到 Kafka 不够快,那么指标*源记录活动计数*可以作为识别该问题的标识。图 3 显示,在我们的案例中,我们不必担心任何阻塞
理所当然,我们试图做得更快,并测试了一些额外的设置及其组合。以下是结果
-
将
snapshot.fetch.size更改为 5000、50000 或 200000:无改善 -
将
batch.size更改为 800000 或 2000000:无改善 -
将
linger.ms更改为 10 或 100:无改善 -
将
linger.ms增加到 750 或 1000:导致 GC 时间增加 -
将
max.batch.size更改为 4000 或 8000:无改善 -
将
max.batch.size更改为 8000,max.queue.size更改为 16000,snapshot.fetch.size和query.fetch.size更改为 50000:无改善,GC 时间增加,CPU 消耗增加 -
将
poll.interval.ms更改为 100:无改善
正如您所见,这些尝试都没有带来任何改善,大多数都变得更慢了。将 snapshot.max.threads 的值设置为我们从中提取数据的总表数并没有加速过程,而且由于对共享数据库资源的巨大负载,操作非常棘手。使用过多的并行线程,我们甚至遇到了连接器因“ORA-12801: error signaled in parallel query server”而崩溃的情况。
结论
尽管我们未能完全达到我们的目标(我们仍然比目标快照时间慢 2 小时),但我们完成的性能优化对我们来说已经足够好了。我们清楚,性能优化是一个迭代过程,我们需要不断监控、分析和调整我们的整个系统以获得最佳性能。
性能优化绝对不是一件容易的事,需要坚持不懈。为了获得最佳性能,有必要找到正确的参数或属性,并在它们之间取得理想的平衡。如果您考虑更改压缩类型,请不要忘记考虑此更改可能对所有下游流程产生的影响。为了更好的端到端性能,我们决定在 ksqlDB 的默认值配置中定义相同的压缩类型。
最后,我想强调一个有趣的现象:在我们的测试中,我们不必更改 Debezium 任何与性能相关的属性的默认值,这有点令人欣慰。我们取得的所有改进都是通过修改 Kafka Connect 生产者属性实现的。
如果您有任何问题或建议,请随时在 zulipchat 上与我联系。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。