
Debezium 从项目一开始就提供了一种直接在 Debezium 内部运行连接器的方式。提供这种功能的方式随着时间的推移而改变,并且仍在不断发展。本文将描述在这方面又一次的演进——Debezium 引擎的新实现。
简史
Debezium 连接器直接运行的能力并非从第一个 Debezium commit 开始就存在,而是在 Debezium 开发的早期就作为 DBZ-1 的一部分添加的,当时 真的非常早。这个 EmbeddedEngine 主要用于测试。然而,随着时间的推移,它已经发展成为连接器的完整运行时平台,支持存储偏移量、模式历史记录等。后来,为 DebeziumEngine 定义了一个公共 API(DBZ-234)。该接口将面向用户的 API 与实现分离,并提供了用不同实现替换当前实现的可能性。在引入 Debezium 引擎 API 后不久,作为 DBZ-651 的一部分,创建了一个新的 Debezium Server。虽然 EmbeddedEngine 需要被包装到另一个消耗记录的应用程序中,但 Debezium Server 提供了一种在没有此类包装器的情况下在 Kafka Connect 集群外部运行 Debezium 的方法。Debezium Server 提供了多种 sink,因此用户无需进一步编码即可开箱即用,但 Debezium Server 仍由 Debezium 引擎提供支持。随着 Debezium Server 的流行度不断提高,添加了越来越多的 sink。这导致 Debezium Server 被 单独的 GitHub 项目 分离。Debezium Server 仓库的拆分是最近 (DBZ-6049) 发生的。Debezium Server 演进的最新增添是实现了 Debezium Operator。它允许在 Kubernetes 集群上无缝部署和管理 Debezium Server。您可以查看 这篇博文 获取更多详细信息。
总而言之,目前,如果用户想在 Kafka Connect 集群外部运行 Debezium 连接器,有三种选择。用户可以直接将 Debezium 引擎嵌入到他们的应用程序中,或者用户可以使用独立的 Debezium Server,或者在 Kubernetes 集群上运行时,用户可以通过 Debezium Operator 部署 Debezium Server。然而,无论用户使用哪种部署方法,所有繁重的工作最终都是由 DebeziumEngine 实现完成的。
EmbeddedEngine 的局限性
如上一节所述,如果您决定在 Kafka Connect 集群外部运行 Debezium,最重要的部分(在性能、可持续性等方面)是 DebeziumEngine 的实现。直到最近,DebeziumEngine 唯一可用的实现是 EmbeddedEngine。如前所述,EmbeddedEngine 最初被实现为一个测试框架,用于轻松测试连接器,而无需启动整个 Kafka 集群。因此,EmbeddedEngine 的设计并非为了最佳性能,甚至不是为了生产环境使用。期间,进行了各种改进,但一些原始设计和代码结构或多或少保持不变。
EmbeddedEngine 的主要局限性在于它只能运行一个任务。因此,如果您有一个支持多任务执行的连接器(SQL Server 连接器),您无法在 EmbeddedEngine 中使用多个任务,并且仍然必须在一个任务中运行所有内容。此外,所有记录都在单个线程中处理。这意味着单条消息转换(SMT)、序列化以及用户处理器的链式调用都是同步进行的,如下图所示。
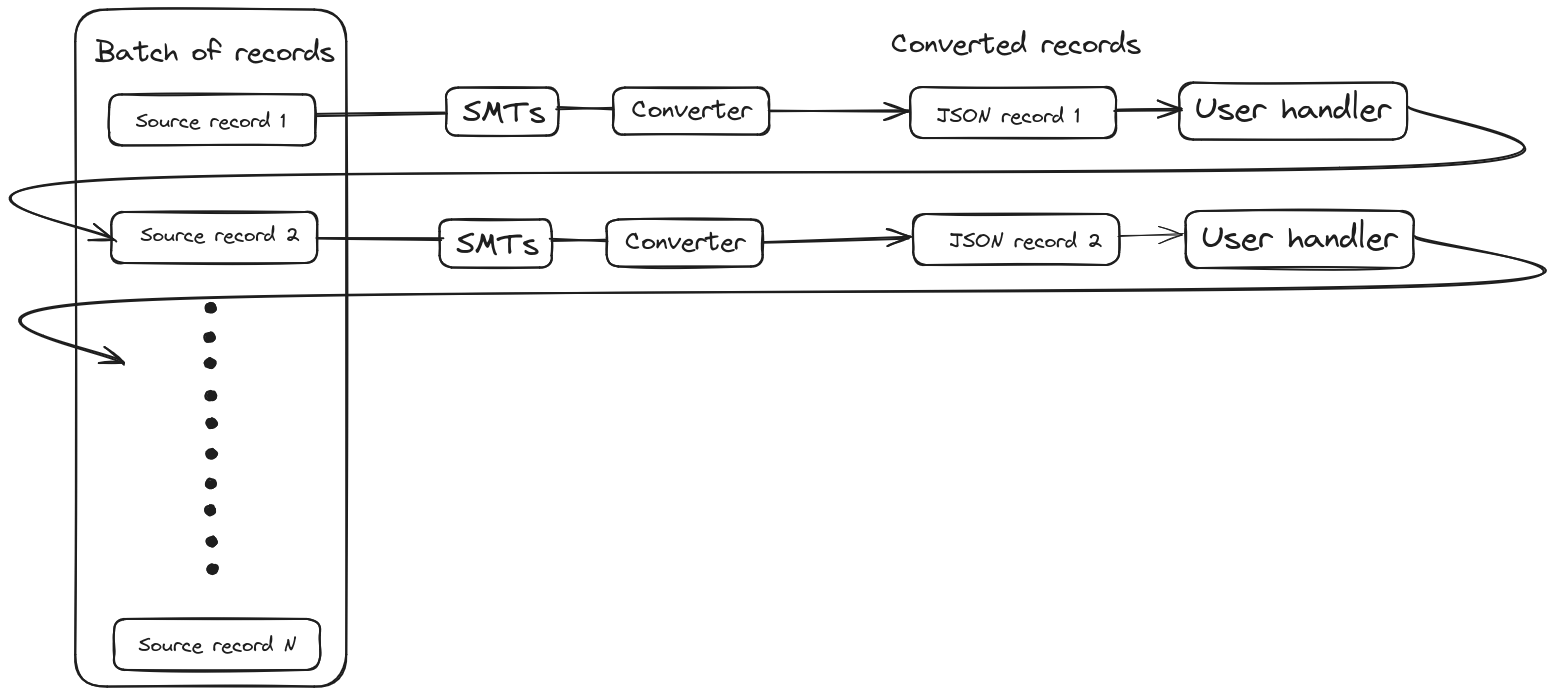
一旦批处理中一条记录的整个管道完成,只有之后才会处理下一条记录。这模仿了 Kafka Connect 的行为,Kafka Connect 也以串行方式处理源记录。
根据我们的性能测试以及用户在 Zulip 聊天中的报告,似乎尤其是序列化经常是性能瓶颈。自然,人们可以立即建议至少并行运行部分工作负载,例如序列化。然而,这需要对 EmbeddedEngine 进行大量更改。EmbeddedEngine 当前的代码结构也远非完美。进行任何更改,例如在重试机制中,都相当具有挑战性且容易出错。这促使我们决定从头开始实现 DebeziumEngine API,并创建一个新的 Debezium 引擎实现。除了在全新起点开始之外,它还让我们能够仅用一小部分测试套件来测试新引擎,并逐步切换到新的引擎实现,始终保留将 EmbeddedEngine 作为后备选项。因此,创建了 AsyncEmbeddedEngine。
异步嵌入式引擎
AsyncEmbeddedEngine 是 DebeziumEngine 接口的新实现。它解决了上一节概述的 EmbeddedEngine 的主要缺点。异步引擎允许连接器执行多个任务。最重要的是,顾名思义,它旨在并行运行记录处理。
架构
从高层次来看,有两个线程池,一个较小的线程池用于管理任务,一个较大的线程池用于处理记录。任务线程池的大小对应于配置的任务数——每个任务都有自己的专用线程。记录处理线程池的大小也是可配置的,但来自此线程池的线程在所有运行的任务之间共享。
异步引擎中的记录是并行处理的。处理的并行化程度取决于配置。DebeziumEngine API 提供了两种消费变更的可能性:通过 ChangeConsumer 或通过 java.util.function.Consumer 函数。在第一种情况下,ChangeConsumer 期望整个记录批次,因为我们只能并行运行 SMT 链和序列化。一旦批次中的所有记录都被处理完毕,整个批次就会被传递给用户定义的 ChangeConsumer。
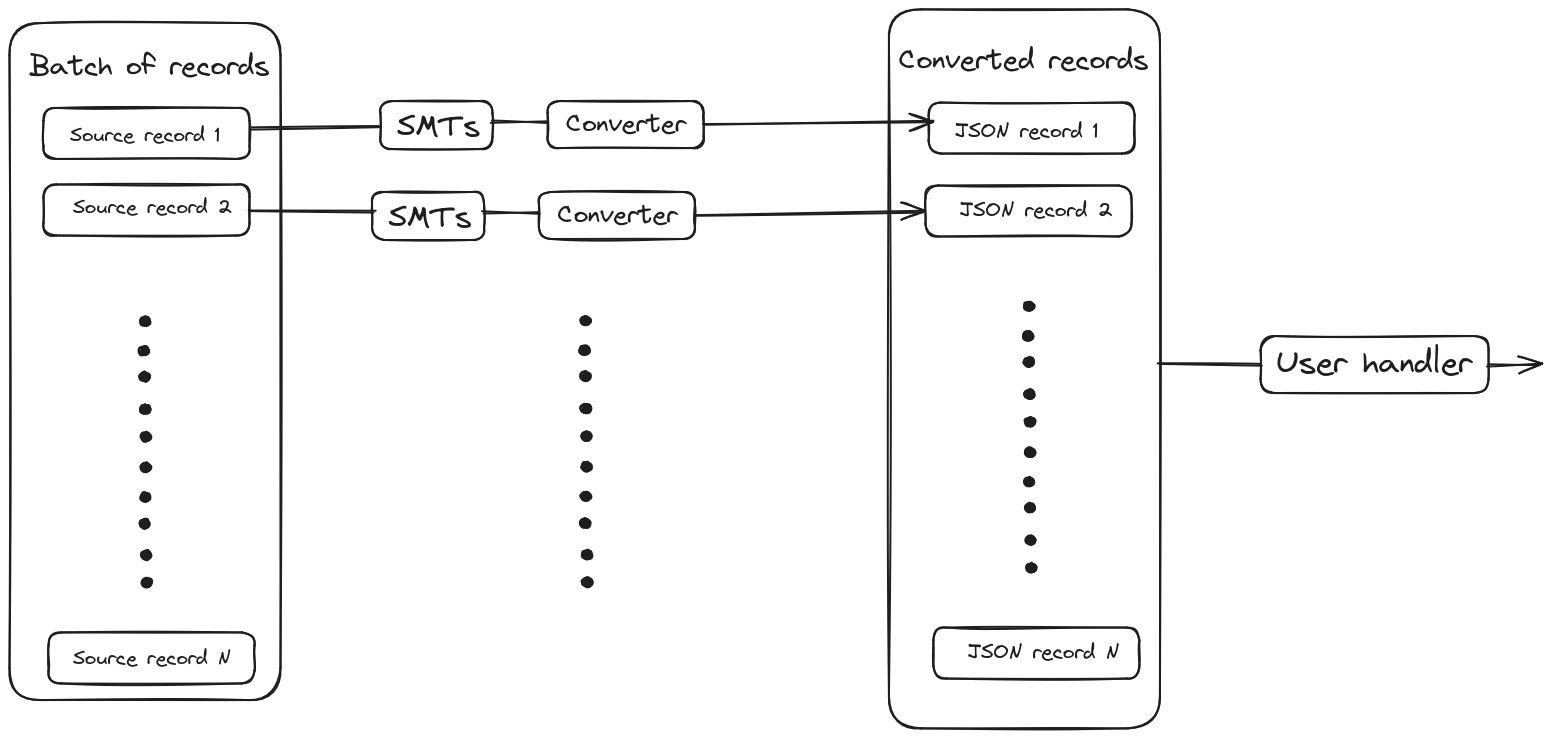
在后一种情况下,当用户只提供处理单个记录的消费函数时,我们可以并行运行整个记录处理管道。
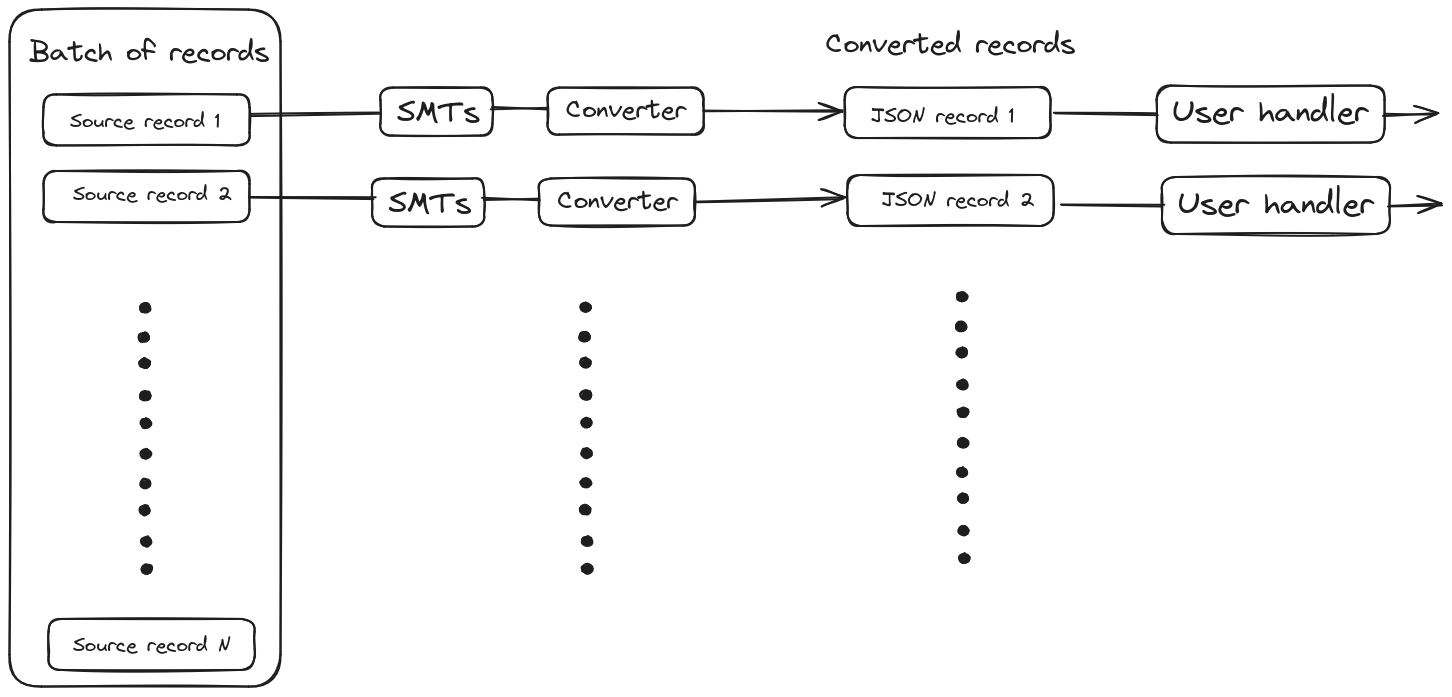
管道可以按照连接器任务提供的原始批次相同的顺序进行处理,也可以完全异步处理。整个管道的异步处理意味着记录可以以与源数据库中发生更改不同的顺序发送到 sink。但是,在某些情况下顺序无关紧要(例如,批量插入不同数据),而重要的是处理速度。此类用例应通过此设置来解决。
用法
由于 AsyncEmbeddedEngine 实现的接口与 EmbeddedEngine 相同,因此用法也相同。
DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine
.create(KeyValueHeaderChangeEventFormat.of(Json.class, Json.class, Json.class), "io.debezium.embedded.async.ConvertingAsyncEngineBuilderFactory")
.using(props)
.notifying(record -> {
System.out.println("Key = '" + record.key() + "' value = '" + record.value() + "'");
}).build();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);如果您想使用 AsyncEmbeddedEngine,目前您必须使用 create(KeyValueHeaderChangeEventFormat<K, V, H> format, String builderFactory) 方法,并将 io.debezium.embedded.async.ConvertingAsyncEngineBuilderFactory 作为 builderFactory。其他快捷 builder 方法仍然指向 EmbeddedEngine。
完成后,您可以通过调用 engine.close() 来终止引擎,就像 EmbeddedEngine 一样。这里的主要区别是,一旦 AsyncEmbeddedEngine 被关闭,它就不能再次启动,必须重新创建。原因是防止在引擎从不同线程并行停止和启动时可能出现的资源泄漏(您可以在设计文档和 DBZ-2534 中找到更多详细信息)。
配置选项
与 EmbeddedEngine 相比,AsyncEmbeddedEngine 只提供了几个额外的配置选项,主要与线程管理相关。
-
record.processing.threads- 用于记录处理的线程池大小。 -
record.processing.order- 确定记录的生成方式,是ORDERED还是UNORDERED。 -
record.processing.with.serial.consumer- 指定是否从提供的Consumer创建默认的ChangeConsumer。 -
record.processing.shutdown.timeout.ms- 调用任务 shutdown 后等待处理已提交记录的最大毫秒数。 -
task.management.timeout.ms- 引擎等待任务生命周期管理操作(启动和停止)完成的时间限制。
record.processing.threads 非常清晰,它是用于处理记录的共享线程池的大小。您可以使用 AVAILABLE_CORES 占位符来利用给定机器上的所有可用核心。
record.processing.order - 如上所述,记录可以按照数据库中更改发生的顺序处理,也可以完全异步处理,从而导致记录无序地传递到 sink。使用哪种方法由此选项决定。请注意,此选项仅在用户处理程序作为 Consumer 函数提供时才有效。如上一节所述,ChangeConsumer 期望整个记录批次,因此 Debezium 引擎无法确保并行处理单个记录,将其设置为 UNORDERED 处理在这种情况下没有意义。
record.processing.with.serial.consumer 决定是否从用户提供的 Consumer 函数创建默认的 ChangeConsumer。这基本上是为了向后兼容 EmbeddedEngine。对于 EmbeddedEngine,总是使用 ChangeConsumer,如果用户提供了感兴趣的 Consumer 函数,EmbeddedEngine 会创建默认的 ChangeConsumer。当启用此选项时,AsyncEmbeddedEngine 也会这样做,并创建与 EmbeddedEngine 相同的 ChangeConsumer,因此您可以获得与 EmbeddedEngine 完全相同的行为。
record.processing.shutdown.timeout.ms 指定引擎应等待多久来处理已提交的记录。调用 shutdown 后,不会再提交其他记录进行处理,但您可能希望等待已经正在处理的记录。由于记录的处理通常应该很快,因此这可以是一个较小的值(从几十毫秒到几秒钟)。
task.management.timeout.ms 确定任务启动或停止的超时时间。如果超过超时时间,运行任务的线程将被强制终止。如果在启动过程中超过此超时时间且任务被终止,则所有其他任务也将被终止。要么所有任务都必须启动,要么没有任务启动。与 record.processing.shutdown.timeout.ms 相比,任务启动可能非常耗时(创建数据库连接等),因此在这种情况下,超时时间应远高于记录处理的超时时间(可能以分钟为单位)。
Debezium Server 用法
从 Debezium 2.6.0.Alpha2 开始,Debezium Server 已切换 使用 AsyncEmbeddedEngine。因此,如果您使用 Debezium Server 2.6.0.Alpha2 或更高版本,您已经在异步使用引擎了。由于 Debezium 引擎目前仅使用 ChangeConsumer 处理 CDC 记录,因此上面提到的与使用 ChangeConsumer 相关的所有约束(无法按顺序处理记录)也适用于 Debezium Server。这将来可能会改变,但目前我们看不到任何需求。
EmbeddedEngine 的弃用
从 Debezium 2.7.0.Final 开始,EmbeddedEngine 已被弃用(DBZ-7976)。我们将在接下来的大约 6 个月内保留它。在此期间,我们将把剩余的测试套件迁移到异步引擎(DBZ-7977),然后在 Debezium 3.1.0.Final 中删除 EmbeddedEngine(DBZ-8029)。如果您使用 DebeziumEngine API,迁移应该非常直接。如果您使用转换包装器,您唯一需要做的是将 ConvertingEngineBuilderFactory 切换到 ConvertingAsyncEngineBuilderFactory,如上一章所述。然而,我们强烈建议尽早切换到异步引擎,并最终让我们知道您是否发现任何问题,以便我们在最终移除 EmbeddedEngine 之前有足够的时间修复任何此类问题。
未来的步骤和展望
除了前面提到的删除 EmbeddedEngine 之外,我们是否完成了更改,还是计划进行任何进一步的更改?当然,我们计划继续改进!那么您有什么可以期待的呢?
随着 Debezium 3.0,我们将切换到 Java 21 来构建 Debezium,并且在未来的版本中,Java 21 将成为 Debezium 的基线。通过这一点,我们希望切换到 Java 虚拟线程。这可能会带来更多的加速,并最终稍微简化代码。我们将根据内部性能测试的结果来评估此选项。
谈到性能测试,人们可能会问为什么这篇博文没有包含至少一些性能比较。我们当然进行了一些性能测试,我们有一些 JMH 基准测试(欢迎提交改进的 PR!)并且还进行了一些端到端的性能测试。您可以在 此 pull request 下找到一些 JMH 结果,它还将结果与 EmbeddedEngine 进行了比较。另一方面,我们完全意识到性能测试的复杂性和棘手之处,并认为拥有一些可靠的结果还需要更多的工作。无论如何,这本身就值得一篇博客文章。毕竟,即使有非常可靠的性能结果,您的部署的实际情况可能仍然不同,因此真正重要的是您在您的硬件、您的生产网络设置等上进行的性能测试。如果您这样做,我们很乐意听到结果。
至于其他方面,我们可能会添加更多 RecordProcessor 的实现,例如 Jeremy Ford 在异步引擎 DDD 的 讨论 中建议的一个。
从长远来看,我们希望添加对 gRPC 和 Protocol Buffers 的支持。这应该给我们带来双重优势:Debezium 引擎将能够协调多台机器上的多个任务的执行,并且还能够以统一的格式从它们接收 CDC 记录。能够(对于允许它的连接器)在单独的机器/容器上运行多个任务,在 Kubernetes 等环境中尤其重要,在这些环境中,您理想情况下希望每个任务都在单独的容器中运行。定义 Protocol Buffers 格式将允许 Debezium 与各种连接器协同工作,即使是用不同语言编写的连接器,并且可以在各种设备上运行,包括边缘设备,从而使 Debezium 引擎成为任何 CDC 解决方案的核心。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。