
在数据流优化领域,即使是微小的改进也能产生显著的影响。本文重点介绍一项此类改进:在 Debezium 的 JDBC 连接器中引入批处理支持。我们将指导您完成启用批处理的过程,并分享我们的性能测试的实际成果。
配置批处理
由于我们之前的版本主要关注核心功能,因此我们最新的版本致力于解决连接器的一个主要痛点:性能。
目标是提高每秒处理的事件数 (EPS) 的吞吐量。为了实现这一目标,我们重新审视了连接器,以支持处理事件批次。
您现在可以使用一个新属性来微调批处理的大小:batch.size。
batch.size 属性定义了将 **尝试** 批处理到目标表中的记录数量。但是,需要注意的是,实际处理的记录大小取决于 Kafka Connect 工作进程的 consumer.max.poll.records 属性。
请注意,如果您将 Connect 工作进程属性中的 consumer.max.poll.records 设置为低于 batch.size 的值,批处理将受 consumer.max.poll.records 的限制,并且可能无法达到预期的 batch.size。
配置 consumer max poll records
如果您不想在 Connect 工作进程上全局配置 consumer.max.poll.records 属性,您可以在连接器配置中使用 consumer.override.max.poll.records 为特定连接器设置底层使用者 (consumer) 的 max.poll.records。
要启用每个连接器的配置属性并覆盖默认工作进程属性,请在工作进程属性文件中添加以下参数:connector.client.config.override.policy (参见 override-the-worker-configuration)。
此属性定义了哪些配置可以被连接器覆盖。默认实现是 All,但其他可能的策略包括 None 和 Principal。
当 connector.client.config.override.policy=All 时,工作进程的每个连接器都可以覆盖工作进程配置。您现在可以使用以下覆盖前缀用于 sink 连接器配置:consumer.override.<sink-configuration-property>。
值得注意的是,即使您设置了 max.poll.records (默认值为 500),您也可能收到较少的记录。这是因为其他属性会影响从主题/分区获取记录。
名称:fetch.max.bytes
默认值:52428800 (52MB)
名称:max.partition.fetch.bytes
默认值:1048576 (1MB)
名称:message.max.bytes
默认值:1048588 (1MB)
名称:max.message.bytes
默认值:1048588 (1MB)
因此,请根据您预期的负载大小进行调整,以达到所需的轮询记录数。
性能测试结果
性能测试的目的是为了说明批处理支持如何提高 EPS。因此,这些数字并不反映任何真实场景,而是展示了与旧版 JDBC 相比的相对改进。
测试使用的配置
所有测试均在 ThinkPad T14s Gen 2i 上执行
CPU:Intel® Core™ i7-1185G7 @ 3.00GHz (8 核)
内存:32GB
硬盘:512GB NVMe
所有必需组件 (Kafka、Connect、Zookeeper 等) 均在 Docker 容器内运行。
测试使用的表结构如下
CREATE TABLE `aviation` (
`id` int NOT NULL,
`aircraft` longtext,
`airline` longtext,
`passengers` int DEFAULT NULL,
`airport` longtext,
`flight` longtext,
`metar` longtext,
`flight_distance` double DEFAULT NULL
)测试计划
我们计划执行这些测试
-
单个表 100,000 个事件
-
MySQL 启用批处理 vs. 未启用批处理
-
-
三个不同表的 100,000 个事件
-
MySQL 启用批处理 vs. 未启用批处理
-
-
单个表 1,000,000 个事件
-
MySQL 批处理大小:500、1000、5000、10000 vs. 未启用批处理
-
MySQL 批处理大小:500、1000、5000、10000,使用 JSONConverter
-
MySQL 批处理大小:500、1000、5000、10000,使用 Avro
-
MySQL 批处理大小:500、1000、5000、10000,使用 Avro 且目标表无索引
-
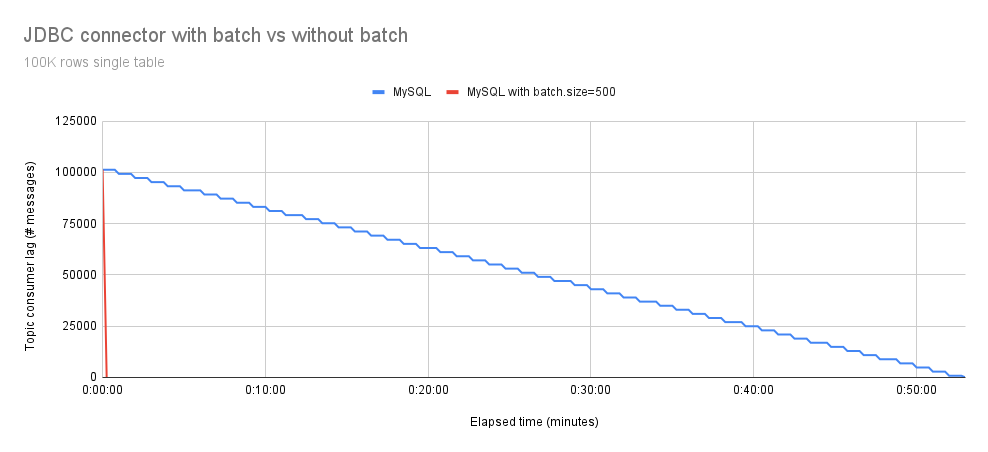
图 1 显示了处理单个表 100,000 个事件所需的总执行时间,比较了启用批处理和未启用批处理的 MySQL 连接器。
| 尽管 |
正如预期,我们可以看到,启用批处理的 Debezium JDBC 连接器速度更快。
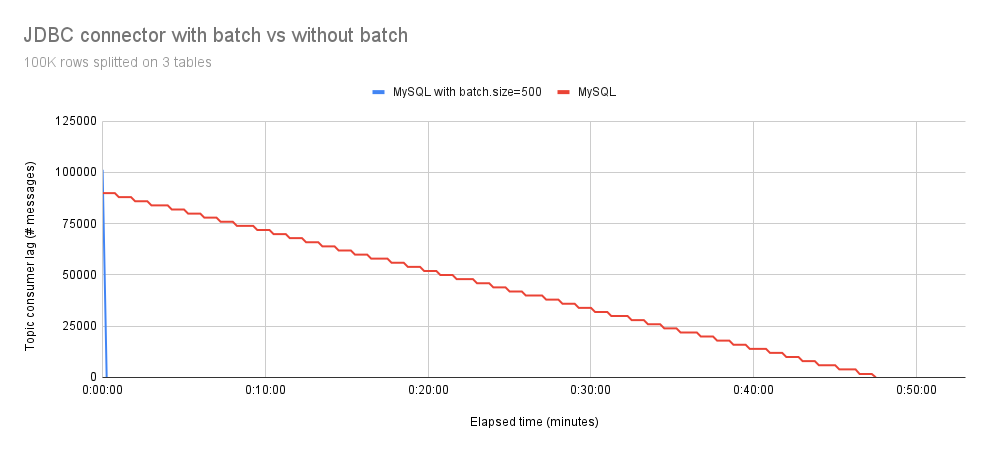
在图 2 中,我们观察到将 100,000 个事件拆分到三个表中并不会影响结果。启用批处理的 Debezium JDBC 连接器仍然比未启用批处理的版本更快。
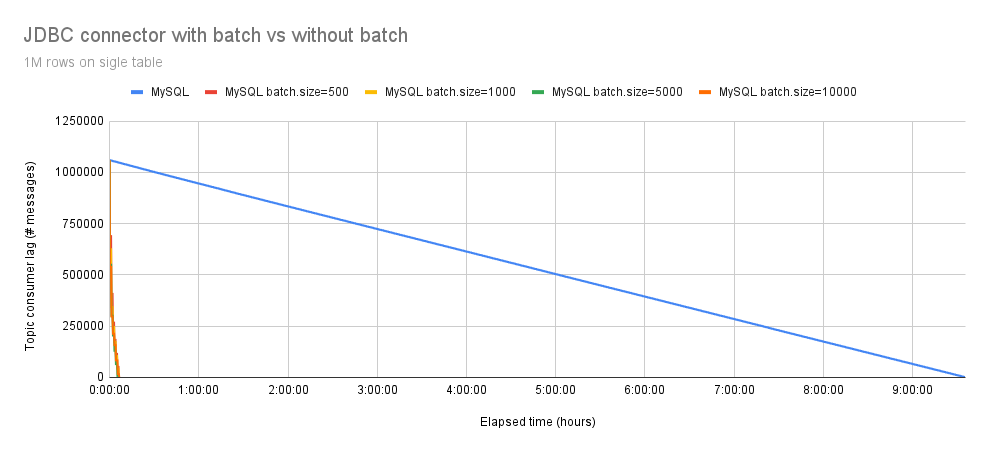
在图 3 中,很明显,性能提升随着 1,000,000 个事件的增加而更加显著。启用批处理的 Debezium JDBC 连接器花费了大约 7 分钟插入所有事件,平均吞吐量为 2300 eps,而未启用批处理的版本则花费了 570 分钟 (9.5 小时)。因此,启用批处理的 Debezium JDBC 连接器比未启用批处理的版本快 79 倍。
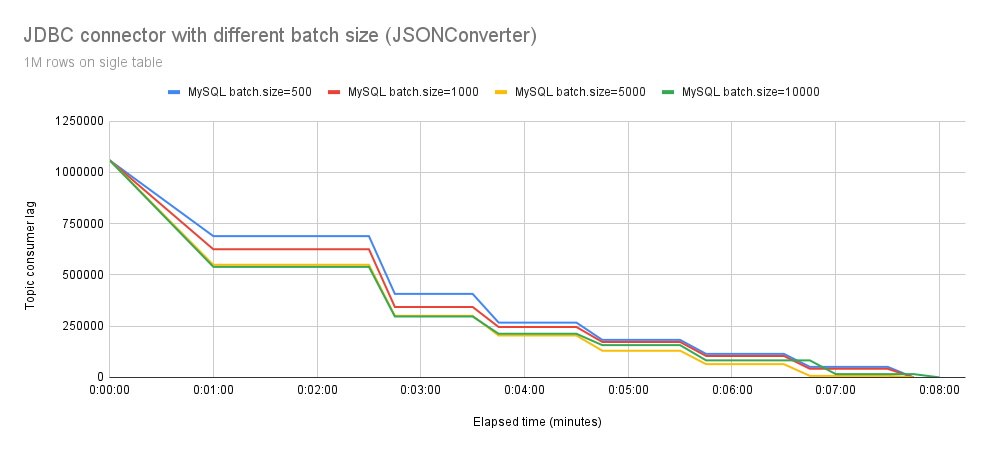
在图 4 中,我们观察了使用 org.apache.kafka.connect.json.JsonConverter 转换器并将数据写入 MySQL 的 Debezium JDBC 连接器的行为,并尝试了不同的 batch.size 设置。虽然最初的差异是明显的,但吞吐量却持续下降。平均而言,所有 batch.size 配置都需要大约 7 分钟来处理所有事件。
这引起了我们的担忧。经过彻底的分析 (剖析),我们确定了另一个问题:事件反序列化。极有可能,这是 batch.size 设置无法扩展的原因。
尽管序列化改进了可扩展性,但我们仍然没有找到 EPS 在测试运行期间减慢的原因。一种假设可能涉及某种类型的缓冲区。
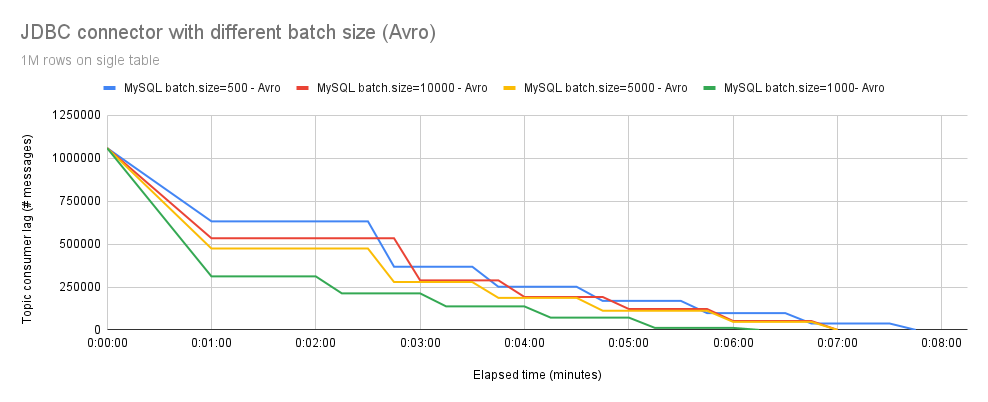
然后我们进行了 Avro 实验,正如图 5 所示,结果显示有显著改进。不出所料,处理 1,000,000 个事件时,batch.size=500 比 batch.size=10000 慢。值得注意的是,在我们的测试配置中,batch.size 的最佳值为 1000,可实现最快的处理时间。
尽管结果比 JSON 好,但仍然存在一些性能下降。
为了确定代码中潜在的瓶颈,我们添加了一些指标,发现大部分时间都花在了数据库上的批量语句执行上。
进一步调查发现,我们的表在主键上定义了一个索引,这减慢了插入速度。
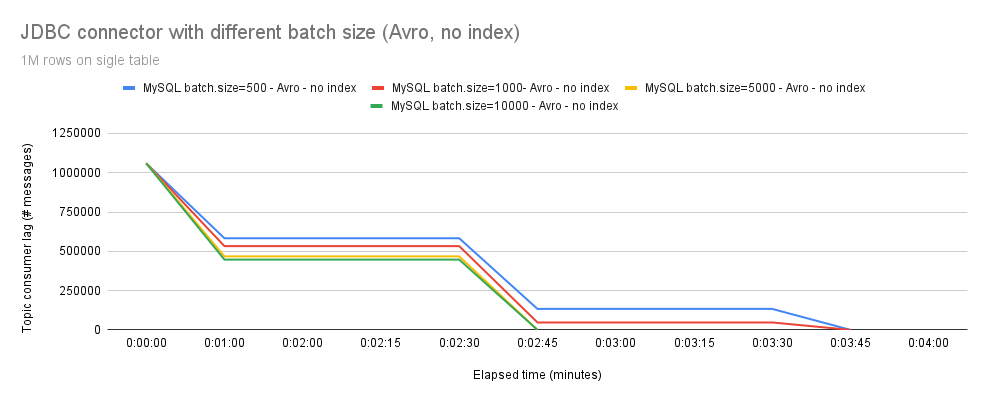
在图 6 中,您可以看到使用 Avro 且没有主键索引时的性能改进。同时,高 batch.size 值带来的性能提升也显而易见。
结论
我们探讨了如何调整 batch.size 可以提高 Debezium JDBC 连接器的性能,并讨论了最大化其优势的正确配置。同样重要的是,遵循针对数据库的高效插入的性能技巧和通用指南。
这里有几个例子
虽然有些设置可能特定于某些数据库,但许多通用原则适用于大多数数据库。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。