
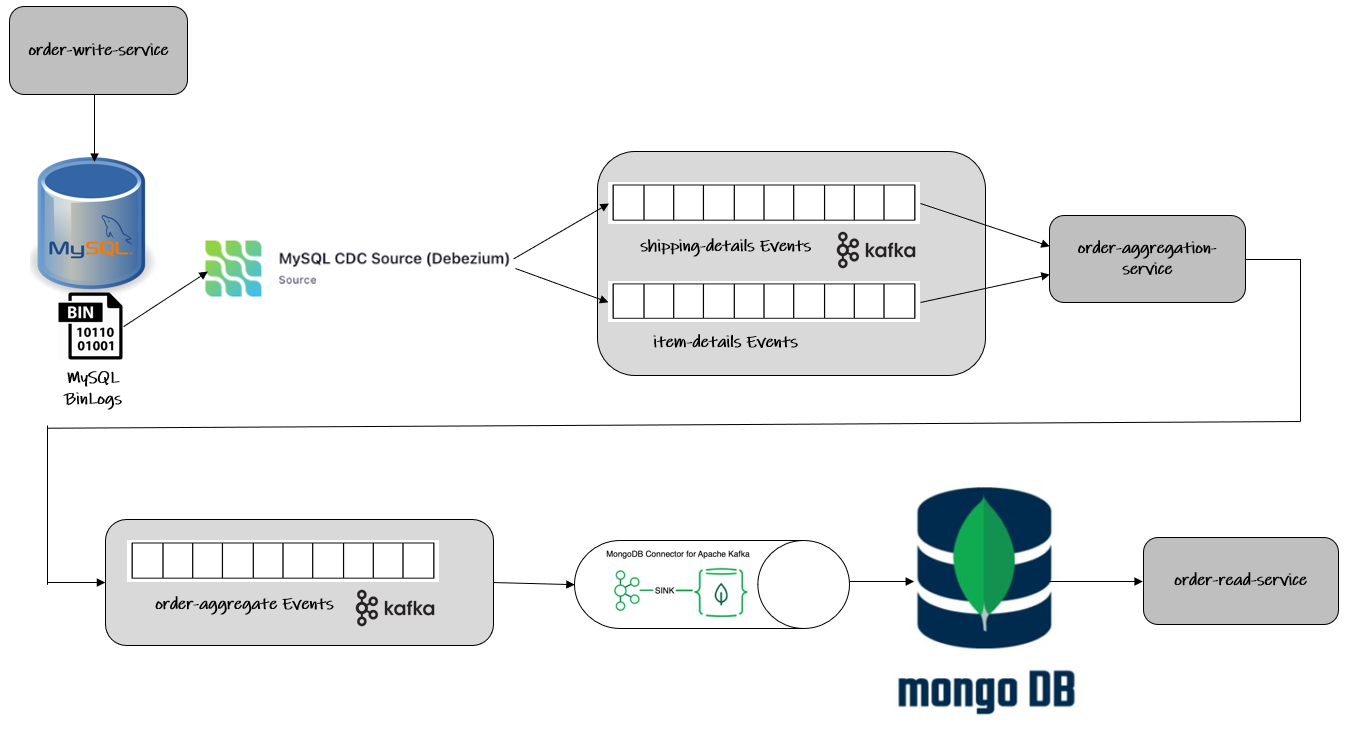
在本篇文章中,我们将讨论一个 CDC-CQRS 管道,它连接了一个规范化的关系型数据库(MySQL)作为命令数据库,以及一个反规范化的 NoSQL 数据库(MongoDB)作为查询数据库,通过 Debezium & Kafka-Streams 实现 DDD Aggregates 的创建。
该示例围绕三个微服务展开:order-write-service、order-aggregation-service 和 order-read-service。这些服务是用 Java 实现的 Spring-Boot 应用程序。
order-write-service 暴露了两个 REST 端点,用于将 shipping-details 和 item-details 持久化到 MySQL 数据库的相应表中。Debezium 会跟踪 MySQL 的 bin logs 以捕获这两个表中的任何事件,并将消息发布到 Kafka 主题。order-aggregation-service 会消费这些主题,它是一个 Kafka-Streams 应用程序,将来自这两个主题的数据连接起来,创建一个 Order-Aggregate 对象,然后将其发布到第三个主题。这个主题会被 MongoDB Sink Connector 消费,数据会被持久化到 MongoDB 中,然后由 order-read-service 提供服务。
解决方案的整体架构可以在下图看到
REST 应用:order-write-service
触发工作流程的第一个组件是 order-write-service。它被实现为一个 Spring-Boot 应用程序,并暴露了两个 REST 端点:
-
POST:
api/shipping-details用于将 shipping details 持久化到 MySQL 数据库 -
POST:
api/item-details用于将 item details 持久化到 MySQL 数据库
这两个端点都将数据持久化到 MySQL 数据库的相应表中。
命令数据库:MySQL
上述 REST 端点的后端处理最终将数据持久化到 MySQL 的相应表中。
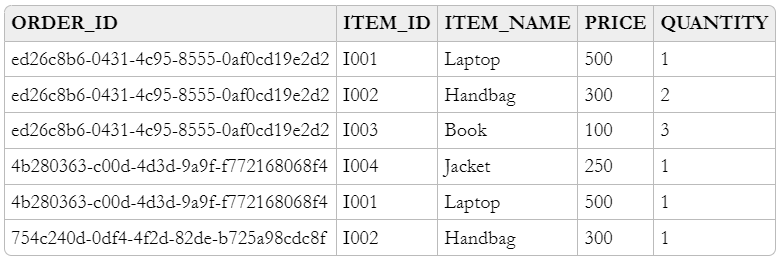
Shipping details 存储在名为 SHIPPING_DETAILS 的表中。Item details 存储在名为 ITEM_DETAILS 的表中。
以下是 SHIPPING_DETAILS 表的数据模型,列 ORDER_ID 是其主键

以下是 ITEM_DETAILS 表的数据模型,列 ORDER_ID + ITEM_ID 是其主键
Kafka Connect Source Connector:MySQL CDC Debezium
变更数据捕获 (CDC) 是一种解决方案,它从数据库事务日志(在 MySQL 的情况下称为 BinLogs)捕获更改事件,并将这些事件转发给下游消费者,例如 Kafka 主题。
Debezium 是一个提供低延迟数据流平台以实现变更数据捕获 (CDC) 的平台,它构建在 Apache Kafka 之上。它允许将数据库行级别的更改捕获为事件并发布到 Apache Kafka 主题。我们设置和配置 Debezium 来监控我们的数据库,然后我们的应用程序会消费数据库中每个行级别更改的事件。
在我们的案例中,我们将使用 Debezium MySQL Source connector 来捕获上述表中的任何新事件,并将它们传递给 Apache Kafka。为了实现这一点,我们将通过向 Kafka Connect 的 REST API 发送 POST 请求来注册我们的连接器。
{
"name": "app-mysql-db-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql_db_server",
"database.port": "3306",
"database.user": "custom_mysql_user",
"database.password": "custom_mysql_user_password",
"database.server.id": "184054",
"database.server.name": "app-mysql-server",
"database.whitelist": "app-mysql-db",
"table.whitelist": "app-mysql-db.shipping_details,app-mysql-db.item_details",
"database.history.kafka.bootstrap.servers": "kafka_server:29092",
"database.history.kafka.topic": "dbhistory.app-mysql-db",
"include.schema.changes": "true",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}| 上述配置基于 Debezium 1.9.5.Final。请注意,如果您尝试使用 Debezium 2.0+ 来运行此演示,上述配置属性中的许多名称已更改,并且配置需要进行一些调整。 |
这会设置一个 io.debezium.connector.mysql.MySqlConnector 实例,捕获指定 MySQL 实例的更改。请注意,通过表包含列表,仅捕获 SHIPPING_DETAILS 和 ITEM_DETAILS 表中的更改。它还应用了一个名为 ExtractNewRecordState 的单消息转换 (SMT),它从 Kafka 记录中的 Debezium 更改事件中提取 after 字段。SMT 会用其 after 字段替换原始更改事件,以创建简单的 Kafka 记录。
默认情况下,Kafka 主题名称是“serverName.schemaName.tableName”,根据我们的连接器配置,它将转换为:
-
app-mysql-server.app-mysql-db.item_details -
app-mysql-server.app-mysql-db.shipping_details
Kafka Streams 应用:order-aggregation-service
名为 order-aggregation-service 的 Kafka Streams 应用程序将处理来自两个 Kafka cdc 主题的数据。这些主题接收基于 MySQL 中 shipping-details 和 item-details 关系的 CDC 事件。
有了这些基础,就可以构建 KStreams 拓扑来动态地创建和维护 DDD order-aggregates。
该应用程序从 shipping-details-cdc-topic 读取数据。由于 Kafka 主题记录是 Debezium JSON 格式,带有解包的信封,我们需要从中解析 order-id 和 shipping-details,以创建一个以 order-id 为键、shipping-details 为值的 KTable。
// Shipping Details Read
KStream<String, String> shippingDetailsSourceInputKStream = streamsBuilder.stream(shippingDetailsTopicName, Consumed.with(STRING_SERDE, STRING_SERDE));
// Change the Json value of the message to ShippingDetailsDto
KStream<String, ShippingDetailsDto> shippingDetailsDtoWithKeyAsOrderIdKStream = shippingDetailsSourceInputKStream
.map((orderIdJson, shippingDetailsJson) -> new KeyValue<>(parseOrderId(orderIdJson), parseShippingDetails(shippingDetailsJson)));
// Convert KStream to KTable
KTable<String, ShippingDetailsDto> shippingDetailsDtoWithKeyAsOrderIdKTable = shippingDetailsDtoWithKeyAsOrderIdKStream.toTable(
Materialized.<String, ShippingDetailsDto, KeyValueStore<Bytes, byte[]>>as(SHIPPING_DETAILS_DTO_STATE_STORE).withKeySerde(STRING_SERDE).withValueSerde(SHIPPING_DETAILS_DTO_SERDE));类似地,应用程序从 item-details-cdc-topic 读取数据,并解析每个消息中的 order-id 和 item,以将同一 order-id 的所有 item 分组到一个列表中,然后聚合到一个以 order-id 为键、属于该特定 order-id 的 item 列表为值的 KTable 中。
// Item Details Read
KStream<String, String> itemDetailsSourceInputKStream = streamsBuilder.stream(itemDetailsTopicName, Consumed.with(STRING_SERDE, STRING_SERDE));
// Change the Key of the message from ItemId + OrderId to only OrderId and parse the Json value to ItemDto
KStream<String, ItemDto> itemDtoWithKeyAsOrderIdKStream = itemDetailsSourceInputKStream
.map((itemIdOrderIdJson, itemDetailsJson) -> new KeyValue<>(parseOrderId(itemIdOrderIdJson), parseItemDetails(itemDetailsJson)));
// Group all the ItemDtos for each OrderId
KGroupedStream<String, ItemDto> itemDtoWithKeyAsOrderIdKGroupedStream = itemDtoWithKeyAsOrderIdKStream.groupByKey(Grouped.with(STRING_SERDE, ITEM_DTO_SERDE));
// Aggregate all the ItemDtos pertaining to each OrderId in a list
KTable<String, ArrayList<ItemDto>> itemDtoListWithKeyAsOrderIdKTable = itemDtoWithKeyAsOrderIdKGroupedStream.aggregate(
(Initializer<ArrayList<ItemDto>>) ArrayList::new,
(orderId, itemDto, itemDtoList) -> addItemToList(itemDtoList, itemDto),
Materialized.<String, ArrayList<ItemDto>, KeyValueStore<Bytes, byte[]>>as(ITEM_DTO_STATE_STORE).withKeySerde(STRING_SERDE).withValueSerde(ITEM_DTO_ARRAYLIST_SERDE));由于两个 KTable 都以 order-id 作为键,因此很容易通过 order-id 将它们连接起来,创建一个名为 Order-Aggregate 的聚合。Order-Aggregate 是一个复合对象,通过整合 shipping-details 和 item-details 的数据创建而成。然后,该 Order-Aggregate 被写入一个 order-aggregate Kafka 主题。
// Joining the two tables: shippingDetailsDtoWithKeyAsOrderIdKTable and itemDtoListWithKeyAsOrderIdKTable
ValueJoiner<ShippingDetailsDto, ArrayList<ItemDto>, OrderAggregate> shippingDetailsAndItemListJoiner = (shippingDetailsDto, itemDtoList) -> instantiateOrderAggregate(shippingDetailsDto, itemDtoList);
KTable<String, OrderAggregate> orderAggregateKTable = shippingDetailsDtoWithKeyAsOrderIdKTable.join(itemDtoListWithKeyAsOrderIdKTable, shippingDetailsAndItemListJoiner);
// Outputting to Kafka Topic
orderAggregateKTable.toStream().to(orderAggregateTopicName, Produced.with(STRING_SERDE, ORDER_AGGREGATE_SERDE));Kafka Connect Sink Connector:MongoDB Connector
Sink Connector 是一个 Kafka Connect 连接器,它从 Apache Kafka 读取数据并将数据写入某个数据存储。使用 MongoDB sink connector,可以轻松地将 DDD aggregates 写入 MongoDB。它只需要一个配置,该配置可以发布到 Kafka Connect 的 REST API 以运行连接器。
{
"name": "app-mongo-sink-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"topics": "order_aggregate",
"connection.uri": "mongodb://root_mongo_user:root_mongo_user_password@mongodb_server:27017",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"database": "order_db",
"collection": "order",
"document.id.strategy.overwrite.existing": "true",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy",
"transforms": "hk,hv",
"transforms.hk.type": "org.apache.kafka.connect.transforms.HoistField$Key",
"transforms.hk.field": "_id",
"transforms.hv.type": "org.apache.kafka.connect.transforms.HoistField$Value",
"transforms.hv.field": "order"
}
}查询数据库:MongoDB
DDD aggregate 被写入 MongoDB 的 order_db 数据库的 order 集合中。order-id 成为表的 _id,而 order 列以 JSON 格式存储 order-aggregate。
REST 应用:order-read-service
持久化到 MongoDB 的 Order Aggregate 通过 order-read-service 中的 REST 端点提供服务。
-
GET:
api/order/{order-id}用于从 MongoDB 数据库检索订单
执行说明
本文博客的完整源代码已在 Github 的 此处 提供。首先克隆此仓库并进入 cdc-cqrs-pipeline 目录。该项目提供了包含所有组件服务的 Docker Compose 文件:
-
MySQL
-
Adminer(以前称为 phpMinAdmin),用于通过浏览器管理 MySQL
-
MongoDB
-
Mongo Express,用于通过浏览器管理 MongoDB
-
Zookeeper
-
Confluent Kafka
-
Kafka Connect
所有服务启动后,通过执行 cdc-cqrs-pipeline.postman_collection.json 中的 Create-MySQL-Debezium-Connector 和 Create-MongoDB-Sink-Connector 请求分别注册 Debezium MySQL 连接器和 MongoDB 连接器的实例。执行 Get-All-Connectors 请求以验证连接器是否已正确创建。
进入各个目录并启动三个 Spring-Boot 应用程序:
-
order-write-service:运行在端口8070 -
order-aggregation-service:运行在端口8071 -
order-read-service:运行在端口8072
至此,我们的设置完成。
要测试应用程序,请在 Postman 集合中执行 Post-Shipping-Details 请求以插入 shipping-details,以及 Post-Item-Details 请求以插入特定 order id 的 item-details。
最后,执行 Postman 集合中的 Get-Order-By-Order-Id 请求以检索完整的 Order Aggregate。
总结
Apache Kafka 作为服务之间消息传递的高可扩展性和可靠的骨干。将 Apache Kafka 置于整体架构的中心还可以确保所涉及服务的解耦。例如,如果解决方案的单个组件发生故障或在一段时间内不可用,事件将稍后处理:重启后,Debezium 连接器将从停止之前的位置继续跟踪相关表。类似地,任何消费者都将从其先前的偏移量继续处理主题。通过跟踪已成功处理的消息,可以检测并排除重复处理。
自然,不同服务之间的这种事件管道最终会是一致的,即消费者(如 order-read-service)可能会比生产者(如 order-write-service)稍微滞后。通常情况下,这没问题,并且可以通过应用程序的业务逻辑来处理。此外,得益于基于日志的变更数据捕获,可以近实时地发出事件,因此解决方案的端到端延迟通常很低(几秒甚至亚秒级)。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。