
本教程最初由 QuestDB 发布,特邀贡献者 Yitaek Hwang 在其中展示了如何通过 Debezium 和 Kafka Connect 将数据变更流式传输到 QuestDB。
现代数据架构已很大程度上从 **ETL** (提取-转换-加载) 范式转向 **ELT** (提取-加载-转换),其中原始数据首先加载到数据湖中,然后再进行转换(例如,聚合、连接)以供进一步分析。传统的 ETL 管道难以维护,并且随着业务需求的变化而相对缺乏灵活性。随着新的云技术承诺更低的存储成本和更好的可扩展性,数据管道可以摆脱预先构建的提取和批量上传,转向更流式的架构。
变更数据捕获 (CDC) 非常适合这种范式转变,它可以将一个源头的数据变更流式传输到其他目的地。顾名思义,CDC 会跟踪数据(通常是数据库)中的变更,并提供插件来对这些变更采取行动。对于事件驱动的架构,CDC 作为服务边界之间(例如,Outbox Pattern)的一致数据交付机制尤其有用。在复杂的微服务环境中,CDC 通过将负担转移给 CDC 系统来帮助简化数据交付逻辑。
为了说明这一点,我们以一个将 PostgreSQL 中的股票更新流式传输到 QuestDB 的参考架构为例。一个简单的 Java Spring 应用通过股票代码轮询股票价格,并将当前价格更新到 PostgreSQL 数据库。然后,Debezium 会检测到这些更新,并将其馈送到 Kafka 主题。最后,Kafka Connect QuestDB 连接器会监听该主题,并将更改流式传输到 QuestDB 进行分析。
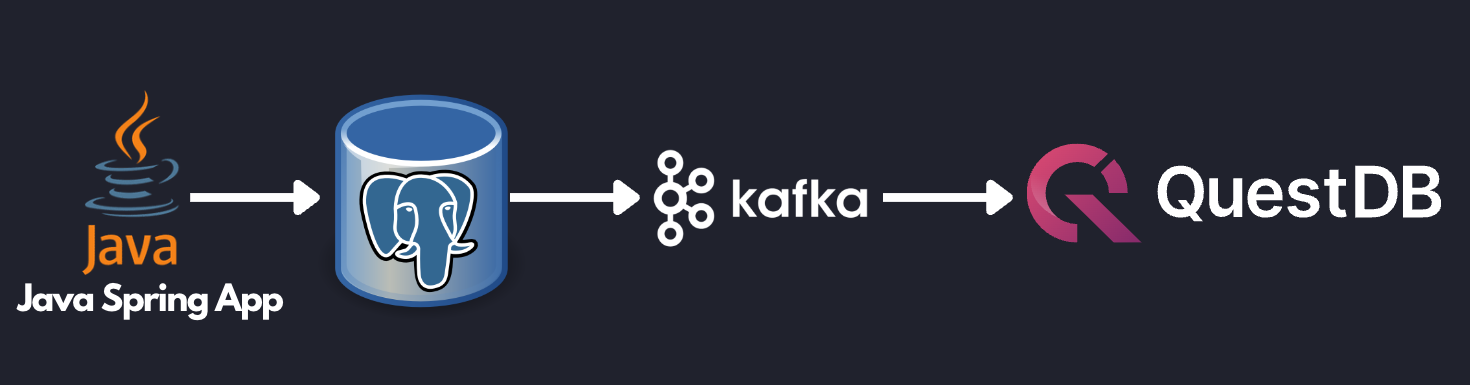
设计概述
以这种方式构建数据管道可以使应用程序保持简单。Java Spring 应用只需获取最新的股票数据并提交到 PostgreSQL。由于 PostgreSQL 是一个出色的 OLTP(事务性)数据库,该应用可以依赖 ACID 合规性来确保下游服务只能看到已提交的数据。应用程序开发人员无需担心复杂的重试逻辑或不同步的数据集。从数据库的角度来看,PostgreSQL 可以针对其最擅长的事情进行优化——事务查询。Kafka 可以被用来可靠地将数据馈送到其他端点,而 QuestDB 可以用来存储历史数据以运行分析查询和可视化。
因此,废话不多说,让我们进入示例
先决条件
-
Git
-
Docker Engine: 20.10+
设置
要在本地运行示例,首先克隆 QuestDG Kafka 连接器仓库
$ git clone https://github.com/questdb/kafka-questdb-connector.git然后,导航到 stocks 示例目录以构建和运行 Docker compose 文件
$ cd kafka-questdb-connector/kafka-questdb-connector-samples/stocks/
$ docker compose build
$ docker compose up| 在 Linux 或旧版本的 Docker 中,`compose` 子命令可能不可用。您可以尝试执行 `docker-compose` 而不是 `docker compose`。如果您的发行版中 `docker-compose` 不可用,您可以 手动安装。 |
这将为 Java Spring 应用/QuestDB 的 Kafka 连接器构建 Dockerfile,并拉取 PostgreSQL(预先配置了 Debezium)、Kafka/Zookeeper、QuestDB 和 Grafana 容器。Kafka 和 Kafka Connect 需要一些时间来初始化。通过检查 connect 容器来等待日志停止。
启动 Debezium 连接器
此时,Java 应用正在持续更新 PostgreSQL 中的 stock 表,但连接尚未建立。通过执行以下命令创建 Debezium 连接器(即 PostgreSQL → Debezium → Kafka)
curl -X POST -H "Content-Type: application/json" -d '{"name":"debezium_source","config":{"tasks.max":1,"database.hostname":"postgres","database.port":5432,"database.user":"postgres","database.password":"postgres","connector.class":"io.debezium.connector.postgresql.PostgresConnector","database.dbname":"postgres","database.server.name":"dbserver1"}} ' localhost:8083/connectors启动 QuestDB Kafka Connect sink
通过创建 Kafka Connect 端(即 Kafka → QuestDB sink)完成整个管道的连接
curl -X POST -H "Content-Type: application/json" -d '{"name":"questdb-connect","config":{"topics":"dbserver1.public.stock","table":"stock", "connector.class":"io.questdb.kafka.QuestDBSinkConnector","tasks.max":"1","key.converter":"org.apache.kafka.connect.storage.StringConverter","value.converter":"org.apache.kafka.connect.json.JsonConverter","host":"questdb", "transforms":"unwrap", "transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState", "include.key": "false", "symbols": "symbol", "timestamp.field.name": "last_update"}}' localhost:8083/connectors最终结果
现在,写入 PostgreSQL 表的所有更新都将反映在 QuestDB 中。要验证,请导航到 https://:19000 并从 stock 表中进行选择
SELECT * FROM stock;您还可以运行聚合来进行更复杂的分析
SELECT
timestamp,
symbol,
avg(price),
min(price),
max(price)
FROM stock
WHERE symbol = 'IBM'
SAMPLE BY 1m ALIGN TO CALENDAR;最后,您可以访问 Grafana 仪表板进行可视化,地址是 https://:3000/d/stocks/stocks?orgId=1&refresh=5s&viewPanel=2。
可视化是一个由 Debezium 捕获的变更组成的蜡烛图;每根蜡烛显示给定时间间隔内的开盘价、收盘价、最高价和最低价。可以通过选择左上角的“Interval”选项来更改时间间隔
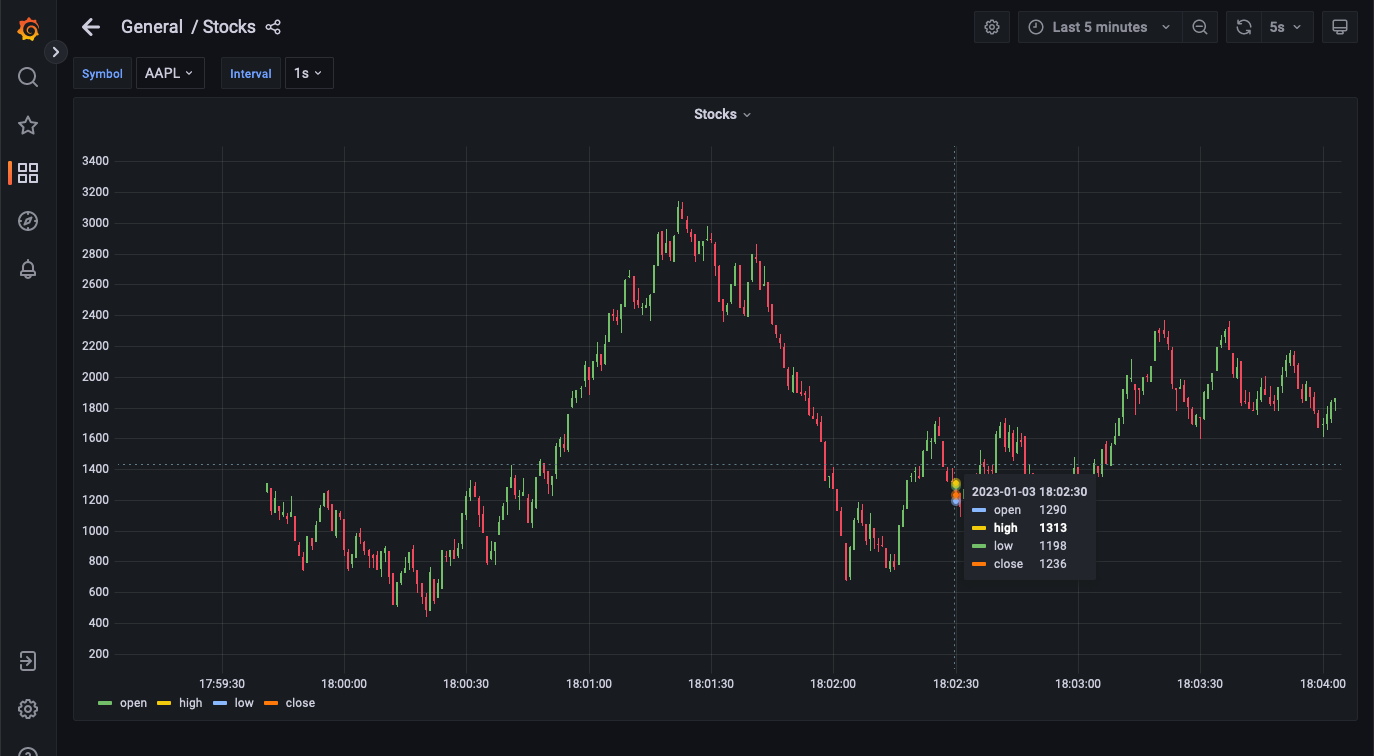
Grafana 蜡烛图
深入了解
既然我们已经成功运行了示例应用程序,让我们深入了解 stocks 示例中的每个文件。
我们将查看以下文件
├── kafka-questdb-connector/kafka-questdb-connector-samples/stocks/
│ ├── Dockerfile-App
| | -- The Dockerfile to package our Java App
| ├── Dockerfile-Connect
| | -- The Dockerfile to combine the Debezium container
| | -- image the with QuestDB Kafka connector
│ ├── src/main/resources/schema.sql
| | -- The SQL which creates the stock table in PostgreSQL
| | -- and populates it with initial data
│ ├── src/main/java/com/questdb/kafka/connector/samples/StocksApplication.java
| | -- The Java Spring App which updates the stock table in PostgreSQL
| | -- in regular intervals
...生产者(Java 应用)
生产者是一个简单的 Java Spring Boot 应用。它包含两个组件:
-
schema.sql文件。此文件用于在 PostgreSQL 中创建 stock 表并填充初始数据。它会被 Spring Boot 应用拾取并在启动时执行。[source,sql] ---- CREATE TABLE IF NOT EXISTS stock ( id serial primary key, symbol varchar(10) unique, price float8, last_update timestamp ); INSERT INTO stock (symbol, price, last_update) VALUES ('AAPL', 500.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('IBM', 50.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('MSFT', 100.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('GOOG', 1000.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('FB', 200.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('AMZN', 1000.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('TSLA', 500.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('NFLX', 500.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('TWTR', 50.0, now()) ON CONFLICT DO NOTHING; INSERT INTO stock (symbol, price, last_update) VALUES ('SNAP', 10.0, now()) ON CONFLICT DO NOTHING; ----The `ON CONFLICT DO NOTHING` clause is used to avoid duplicate entries in the table when the App is restarted.
-
Java 代码,用于使用随机值更新价格和时间戳。更新不是完全随机的,应用程序使用一个非常简单的算法来生成更新,该更新非常粗略地模拟了股票价格的变动。在实际场景中,应用程序会从某个外部源获取价格。
生产者被打包到一个最小的 Dockerfile 中,Dockerfile-App,并链接到 PostgreSQL
FROM maven:3.8-jdk-11-slim AS builder COPY ./pom.xml /opt/stocks/pom.xml COPY ./src ./opt/stocks/src WORKDIR /opt/stocks RUN mvn clean install -DskipTest FROM azul/zulu-openjdk:11-latest COPY --from=builder /opt/stocks/target/kafka-samples-stocks-*.jar /stocks.jar CMD ["java", "-jar", "/stocks.jar"]
Kafka Connect, Debezium, 和 QuestDB Kafka 连接器
在我们深入了解 Kafka Connect、Debezium 和 QuestDB Kafka 连接器配置之前,让我们先看看它们之间的关系。
Kafka Connect 是一个用于构建连接器的框架,用于在 Kafka 和其他系统之间移动数据。它支持两类连接器:
-
Source 连接器 - 从源系统读取数据并将其写入 Kafka
-
Sink 连接器 - 从 Kafka 读取数据并将其写入目标系统
Debezium 是一个用于 Kafka Connect 的 Source 连接器,它可以监视和捕获数据库中的行级更改。这意味着什么?每当在数据库中插入、更新或删除一行时,Debezium 都会捕获更改并将其作为事件写入 Kafka。
从技术层面讲,Debezium 是一个运行在 Kafka Connect 框架内的 Kafka Connect 连接器。这反映在 Debezium 容器镜像 中,该镜像打包了预装了 Debezium 连接器的 Kafka Connect。
QuestDB Kafka 连接器也是一个 Kafka Connect 连接器。它是一个 Sink 连接器,用于从 Kafka 读取数据并将其写入 QuestDB。我们将 QuestDB Kafka 连接器添加到 Debezium 容器镜像中,我们就得到了一个同时安装了 Debezium 和 QuestDB Kafka 连接器的 Kafka Connect 镜像!
这是我们用来构建镜像的 Dockerfile
FROM ubuntu:latest AS builder WORKDIR /opt RUN apt-get update && apt-get install -y curl wget unzip jq RUN curl -s https://api.github.com/repos/questdb/kafka-questdb-connector/releases/latest | jq -r '.assets[]|select(.content_type == "application/zip")|.browser_download_url'|wget -qi - RUN unzip kafka-questdb-connector-*-bin.zip FROM debezium/connect:1.9.6.Final COPY --from=builder /opt/kafka-questdb-connector/*.jar /kafka/connect/questdb-connector/
Dockerfile 下载 QuestDB Kafka 连接器的最新版本,解压后复制到 Debezium 容器镜像中。生成的镜像同时安装了 Debezium 和 QuestDB Kafka 连接器。

Dockerfile-Connect 添加 QuestDB Kafka 连接器层
整体 Kafka 连接器由一个 Source 连接器和一个 Sink 连接器完成
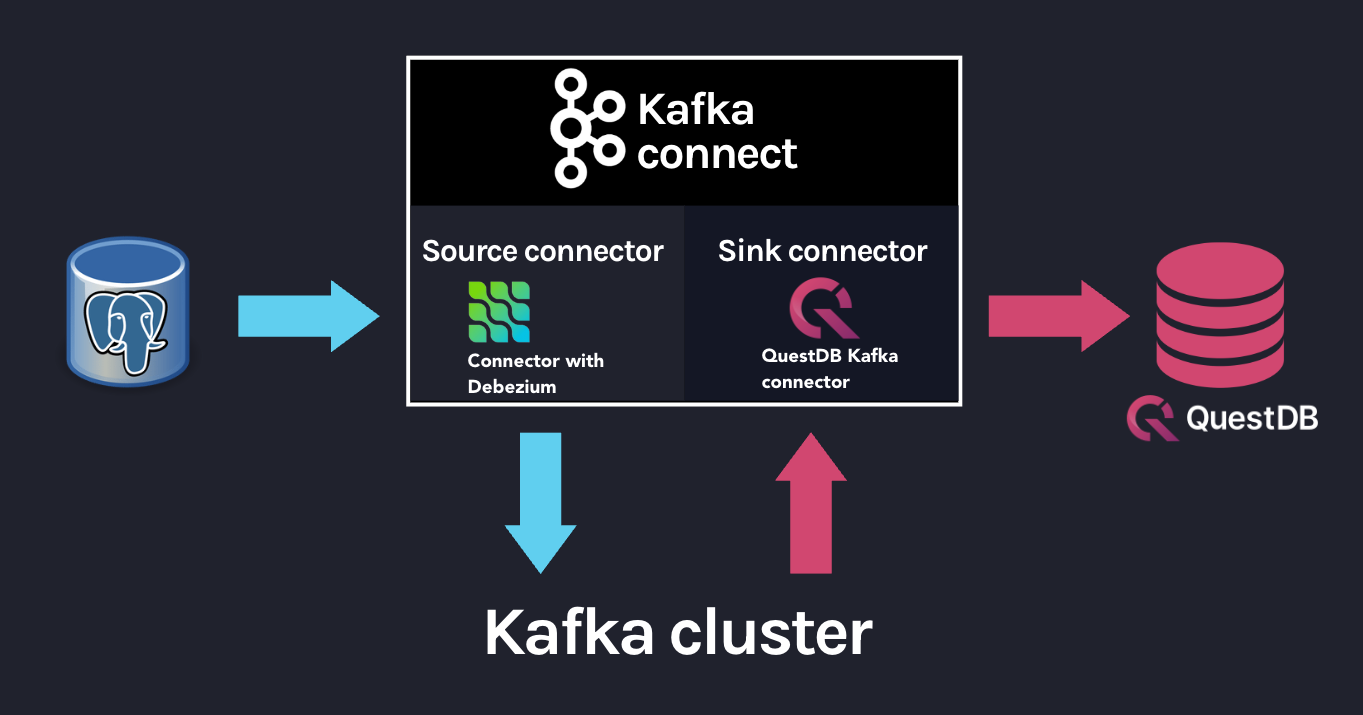
Source 和 Sink 连接器如何与 Kafka 集群和数据库协同工作
Debezium 连接器
我们已经知道 Debezium 是一个 Kafka Connect 连接器,它可以监视和捕获数据库中的行级更改。我们还有一个同时安装了 Debezium 和 QuestDB Kafka 连接器的 Docker 镜像。但是,此时两个连接器都没有运行。我们需要配置并启动它们。这通过 CURL 命令完成,该命令向 Kafka Connect REST API 发送 POST 请求。
curl -X POST -H "Content-Type: application/json" -d '{"name":"debezium_source","config":{"tasks.max":1,"database.hostname":"postgres","database.port":5432,"database.user":"postgres","database.password":"postgres","connector.class":"io.debezium.connector.postgresql.PostgresConnector","database.dbname":"postgres","database.server.name":"dbserver1"}} ' localhost:8083/connectors请求体包含 Debezium 连接器的配置,我们来分解一下:
{
"name": "debezium_source",
"config": {
"tasks.max": 1,
"database.hostname": "postgres",
"database.port": 5432,
"database.user": "postgres",
"database.password": "postgres",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.dbname": "postgres",
"database.server.name": "dbserver1"
}
}它会监听 PostgreSQL 数据库中的更改,并根据上述配置发布到 Kafka。主题名称默认为 `<server-name>.<schema>.<table>`。在我们的示例中,它是 `dbserver1.public.stock`。为什么?因为数据库服务器名称是 `dbserver1`,模式是 `public`,而我们唯一拥有的表是 `stock`。
因此,在我们发送请求后,Debezium 将开始监听 `stock` 表中的更改,并将它们发布到 `dbserver1.public.stock` 主题。
QuestDB Kafka 连接器
此时,我们有一个填充了随机股票价格的 PostgreSQL 表 `stock`,以及一个包含更改的 Kafka 主题 `dbserver1.public.stock`。下一步是配置 QuestDB Kafka 连接器以从 `dbserver1.public.stock` 主题读取数据并将其写入 QuestDB。
让我们更详细地看看 启动 QuestDB Kafka Connect sink 中的配置
{
"name": "questdb-connect",
"config": {
"topics": "dbserver1.public.stock",
"table": "stock",
"connector.class": "io.questdb.kafka.QuestDBSinkConnector",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"host": "questdb",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"include.key": "false",
"symbols": "symbol",
"timestamp.field.name": "last_update"
}
}这里需要注意的重要事项是:
-
`table` 和 `topics`:QuestDB Kafka 连接器将创建一个名为 `stock` 的 QuestDB 表,并将 `dbserver1.public.stock` 主题中的数据写入其中。
-
`host`:QuestDB Kafka 连接器将连接到运行在 `questdb` 主机上的 QuestDB。这是 QuestDB 容器的名称。
-
`connector.class`:QuestDB Kafka 连接器类的名称。这告诉 Kafka Connect 使用 QuestDB Kafka 连接器。
-
`value.converter`:Debezium 连接器以 JSON 格式生成数据。这就是为什么我们需要配置 QuestDB 连接器使用 JSON 转换器来读取数据:`org.apache.kafka.connect.json.JsonConverter`。
-
`symbols`:股票符号被转换为 QuestDB symbol 类型,用于低基数(例如,枚举)的字符串值。
-
`timestamp.field.name`:由于 QuestDB 对时间戳和基于时间戳的分区有很好的支持,我们可以指定指定的时间戳列。
-
`transforms`:unwrap 字段使用 `io.debezium.transforms.ExtractNewRecordState` 类型来仅提取新数据,而不是 Debezium 发出的元数据。换句话说,这是一个过滤器,基本上是为了获取 Kafka 主题上 Debezium 数据的 `payload.after` 部分。有关更多详细信息,请参阅其 文档。
`ExtractNewRecordState` 转换可能是配置中最不直观的部分。让我们仔细看看:简而言之,对于 PostgreSQL 表中的每一个更改,Debezium 都会向 Kafka 主题发出一个 JSON 消息,如下所示:
{
"schema": "This JSON key contains Debezium message schema. It's not very relevant for this sample. Omitted for brevity.",
"payload": {
"before": null,
"after": {
"id": 8,
"symbol": "NFLX",
"price": 1544.3357414199545,
"last_update": 1666172978269856
}
},
"source": {
"version": "1.9.6.Final",
"connector": "postgresql",
"name": "dbserver1",
"ts_ms": 1666172978272,
"snapshot": "false",
"db": "postgres",
"sequence": "[\"87397208\",\"87397208\"]",
"schema": "public",
"table": "stock",
"txId": 402087,
"lsn": 87397208,
"xmin": null
},
"op": "u",
"ts_ms": 1666172978637,
"transaction": null
}如果您觉得消息的庞大体积让您不知所措,请不要害怕。大多数字段都是元数据,与本示例无关。有关更多详细信息,请参阅 Debezium 文档。重要的是,我们不能将整个 JSON 消息推送到 QuestDB,而且我们也不希望所有元数据都存在于 QuestDB 中。我们需要提取消息的 `payload.after` 部分,然后再将其推送到 QuestDB。这正是 `ExtractNewRecordState` 转换的作用:它将大消息转换为只包含消息 `payload.after` 部分的小消息。因此,这就像消息看起来是这样的:
{
"id": 8,
"symbol": "NFLX",
"price": 1544.3357414199545,
"last_update": 1666172978269856
}这是我们可以推送到 QuestDB 的消息。QuestDB Kafka 连接器将读取此消息并将其写入 QuestDB 表。QuestDB Kafka 连接器还将在 QuestDB 表不存在时创建它。QuestDB 表将具有与 JSON 消息相同的架构 - 其中每个 JSON 字段将成为 QuestDB 表中的一个列。
QuestDB 和 Grafana
一旦数据被写入 QuestDB 表,我们就可以更轻松地处理时间序列数据。由于 QuestDB 与 PostgreSQL 线协议兼容,我们可以在 Grafana 中使用 PostgreSQL 数据源来可视化数据。预配置的仪表板使用了以下查询:
SELECT
$__time(timestamp),
min(price) as low,
max(price) as high,
first(price) as open,
last(price) as close
FROM
stock
WHERE
$__timeFilter(timestamp)
and symbol = '$Symbol'
SAMPLE BY $Interval ALIGN TO CALENDAR;我们创建了一个系统,该系统持续跟踪并存储 PostgreSQL 表中多个股票的最新价格。这些价格通过 Debezium 作为事件馈送到 Kafka,Debezium 捕获了每一次价格变化。QuestDB Kafka 连接器从 Kafka 读取这些事件,并将每个更改作为新行存储在 QuestDB 中,从而使我们能够保留股票价格的完整历史记录。然后可以使用 Grafana 等工具分析和可视化此历史记录,如蜡烛图所示。
后续步骤
此示例项目是用于将数据从关系数据库流式传输到优化的时间序列数据库的基础参考架构。对于已经在使用 PostgreSQL 的现有项目,可以将 Debezium 配置为开始将数据流式传输到 QuestDB,并利用时间序列查询和分区。对于也存储原始历史数据的数据库,采用 Debezium 可能需要一些架构更改。然而,这是有益的,因为它是一个改进性能并建立事务性数据库与分析性时间序列数据库之间服务边界的机会。
此参考架构还可以扩展,以便将 Kafka Connect 配置为也流式传输到其他数据仓库以进行长期存储。在检查数据后,QuestDB 还可以配置为对数据进行降采样以进行更长时间的存储,甚至 分离分区以节省空间。
您可以尝试此 示例应用程序,如果您有任何问题,请加入 QuestDB Slack 社区。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。