
Shopify 的工程团队最近改进了 Debezium MySQL 连接器,使其支持对没有连接器写访问权限的数据库进行增量快照,当 Debezium 指向只读副本时需要此功能。此外,Debezium MySQL 连接器现在还允许在增量快照期间进行模式更改。这篇博文解释了这些功能的实现细节。
为何只读?
Netflix 发布了 其变更数据捕获框架 后,Debezium 在 1.6 版本中添加了 增量快照功能。在 Shopify,我们使用 Debezium 进行变更数据捕获 (CDC),并且我们一直期待成为早期采用者。此外,我们希望获得一个不涉及写入和锁定的解决方案。
无写入解决方案允许从只读副本捕获更改,并提供最高的保证,即 CDC 不会在数据库端导致数据损坏。
过去,我们不得不协调快照与迁移,因为模式迁移的阻塞影响了其他项目的开发。解决方案是仅在周末运行快照,因此,我们尽量减少快照的频率。我们也看到了改进此过程一部分的机会。
这篇博文深入探讨了只读增量快照实现的细节,包括 MySQL 连接器在增量快照期间的无锁模式处理模式更改。
Incremental snapshots (增量快照)
《Debezium 中的增量快照》博文详细介绍了默认实现。该算法使用一个信号表来发送两种类型的信号:
-
snapshot-window-open/snapshot-window-close作为水印 -
execute-snapshot作为触发增量快照的方式
对于只读场景,我们需要用替代方案替换这两种类型的信号。
SHOW MASTER STATUS 用于高低水位标记
该解决方案特定于 MySQL,并依赖于 全局事务标识符 (GTIDs)。因此,您需要将 gtid_mode 设置为 ON,并配置数据库以保留 GTID 顺序(如果您正在从只读副本读取)。
先决条件
gtid_mode = ON
enforce_gtid_consistency = ON
if replica_parallel_workers > 0 set replica_preserve_commit_order = ON该算法运行一个 SHOW MASTER STATUS 查询,以在分块选择之前和之后获取已执行的 GTID 集。
low watermark = executed_gtid_set
high watermark = executed_gtid_set - low watermark在只读实现中,水印是 GTID 集合的形式,例如:2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
这些水印不会出现在 binlog 流中。相反,算法会将每个事件的 GTID 与内存中的水印进行比较。该实现确保没有陈旧读取,并且一个分块仅包含不早于低水位标记的事件的更改。
使用只读水印进行去重算法
用伪代码表示,用于对从 binlog 读取的事件和通过快照分块检索的事件进行去重的算法如下:
(1) pause log event processing
(2) GtidSet lwGtidSet := executed_gtid_set from SHOW MASTER STATUS
(3) chunk := select next chunk from table
(4) GtidSet hwGtidSet := executed_gtid_set from SHOW MASTER STATUS subtracted by lwGtidSet
(5) resume log event processing
inwindow := false
// other steps of event processing loop
while true do
e := next event from changelog
append e to outputbuffer
if not inwindow then
if not lwGtidSet.contains(e.gtid) //reached the low watermark
inwindow := true
else
if hwGtidSet.contains(e.gtid) //haven't reached the high watermark yet
if chunk contains e.key then
remove e.key from chunk
else //reached the high watermark
for each row in chunk do
append row to outputbuffer
// other steps of event processing loop水印检查
数据库事务可以更改多行。在这种情况下,多个 binlog 事件将具有相同的 GTID。由于 GTID 不是唯一的,这会影响计算分块选择窗口的逻辑。当水印的 GTID 集合不包含其 GTID 时,事件会更新窗口状态。在交易完成和心跳等事件之后,不会再有具有相同 GTID 的 binlog 事件。对于这些事件,达到水印上限就足以触发窗口的打开/关闭。
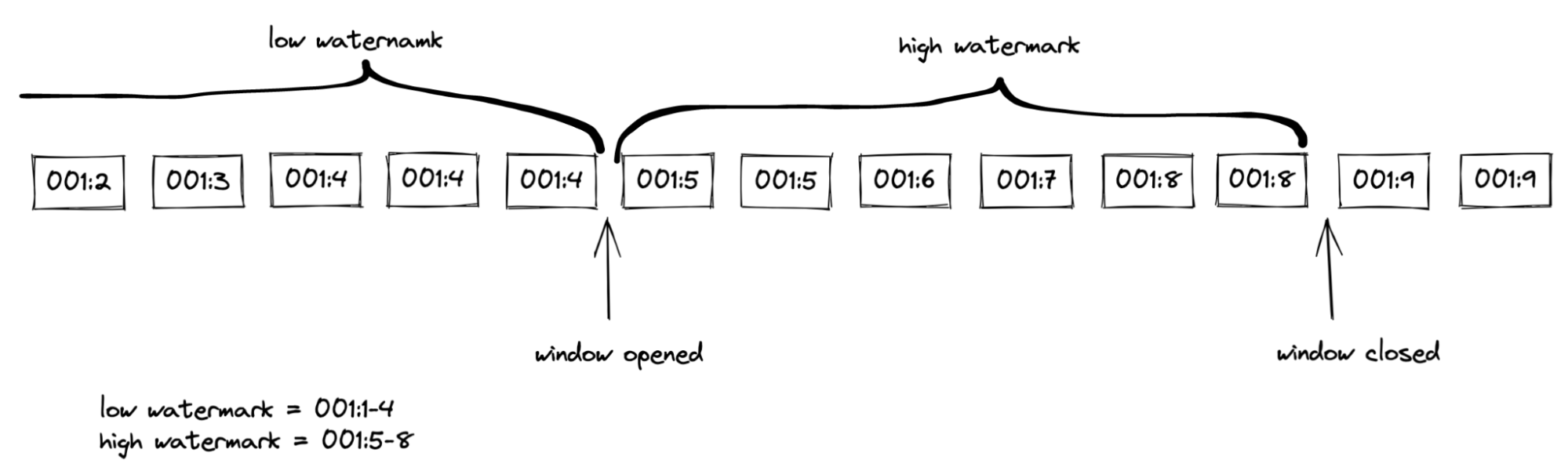
图 1. 分块选择窗口
去重发生在分块选择窗口内,与默认实现相同。最后,算法将在高水位标记之后立即插入去重后的分块。
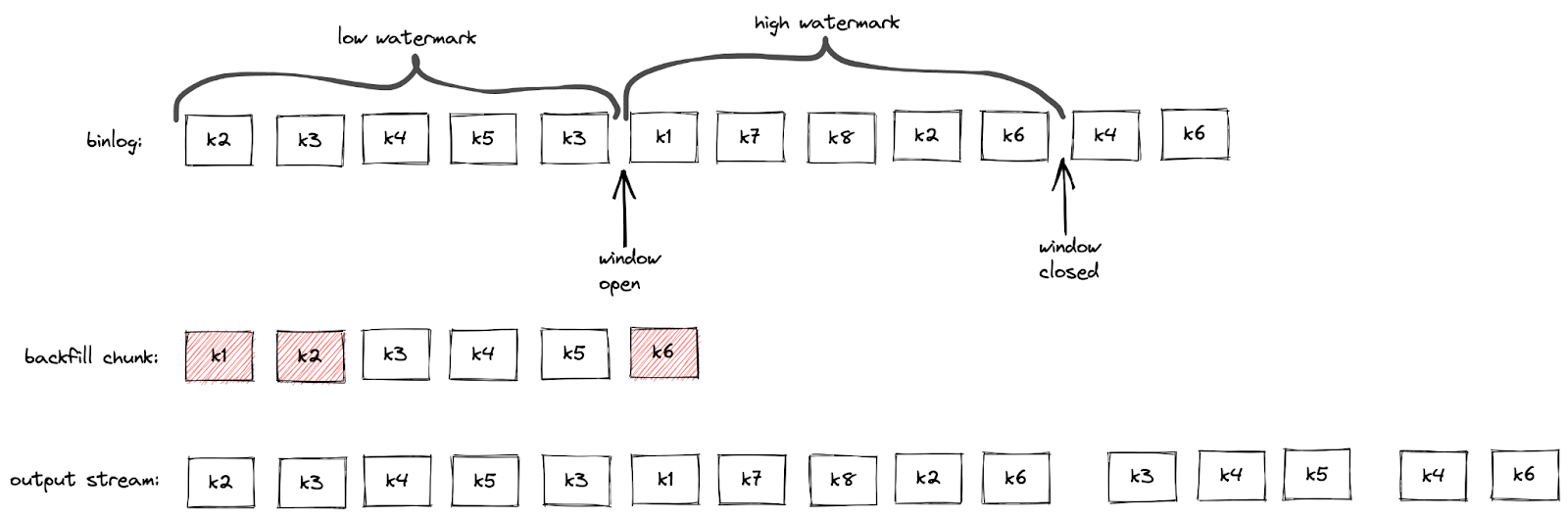
图 2. 分块去重
包含表无更新
为了使快照能够进行,接收 binlog 事件至关重要。因此,该算法会检查所有事件的 GTID 以及未包含的表。
无 binlog 事件
MySQL 服务器会在复制连接空闲 x 秒后发送心跳事件。当 binlog 更新速率较低时,只读实现会利用心跳。
心跳事件具有与最新 binlog 事件相同的 GTID。因此,对于心跳事件,达到高水位标记的上限就足够了。
该算法使用心跳事件 GTID 的 server_uuid 部分来获取高水位标记的最大事务 ID。该实现确保高水位标记包含单个 server_uuid。不变的 server_uuid 可以避免心跳过早关闭窗口的情况。请参见下图示例。
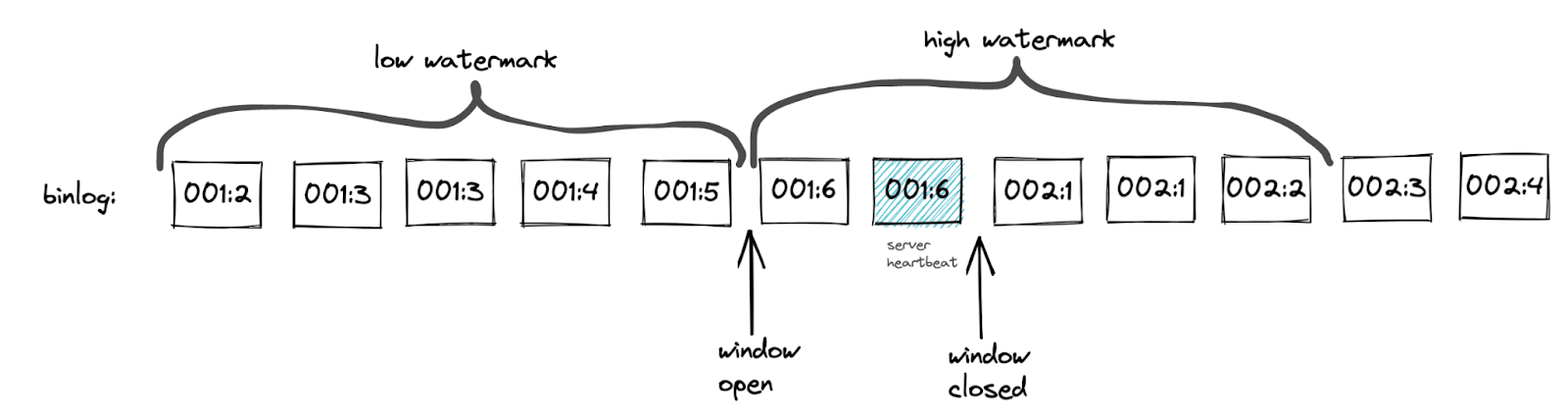
图 3. 心跳过早关闭窗口的场景
由于不需要与低水位标记进行心跳比较,所以无论窗口是否打开都无关紧要。这简化了在高低水位标记之间没有新事件时的检查。
水印之间无更改
当分块选择期间没有 binlog 事件时,binlog 事件可以立即打开和关闭窗口。在这种情况下,高水位标记将是空集。此时,快照分块将在低水位标记之后立即插入,无需去重。
图 4. 空分块选择窗口
基于 Kafka 的主题信号
Debezium 支持通过向信号表插入来触发的即席增量快照。只读替代方案是通过特定的 Kafka 主题发送信号。消息的格式模仿了信号表结构。execute-snapshot Kafka 消息包含参数:
-
data-collections- 要捕获的表列表 -
type- 设置为 INCREMENTAL
示例
Key: dbserver1
Value: {"type":"execute-snapshot","data": {"data-collections": ["inventory.orders"], "type": "INCREMENTAL"}}MySQL 连接器的配置中有一个新的 signal.kafka.topic 属性。该主题必须有一个分区并采用删除保留策略。
一个单独的线程从 Kafka 主题检索信号消息。Kafka 消息的键需要与 database.server.name 中设置的连接器名称匹配。连接器将跳过与连接器名称不匹配的事件,并记录一条日志。键检查允许为多个连接器重用信号主题。
当增量快照运行时,连接器的偏移量包含增量快照上下文。只读实现将 Kafka 信号偏移量添加到增量快照上下文中。跟踪偏移量可以防止连接器在重启时错过或重复处理信号。
但是,使用 Kafka 来执行只读增量快照不是必需的,并且写入信号表中的默认 execute-snapshot 信号也可以工作。未来,可以设想通过 Debezium Server 暴露的 REST API 来触发即席增量快照,或者将其作为部署到 Kafka Connect 的附加 REST 资源。
增量快照期间的模式更改
Debezium MySQL 连接器 允许在增量快照期间进行模式更改。连接器将在增量快照期间检测到模式更改,并重新选择当前分块以避免锁定 DDL。
请注意,主键的更改不受支持,如果在增量快照期间执行,可能会导致不正确的结果。
像 MySQL 这样的历史化 Debezium 连接器会解析 binlog 流中的数据定义语言 (DDL) 事件,如 ALTER TABLE。连接器会保留内存中每张表的模式表示,并使用这些模式来生成相应的更改事件。
增量快照实现使用 binlog 模式两次:
-
在从数据库选择分块时
-
在将分块插入 binlog 流时
分块的模式必须同时匹配这两个时间点的 binlog 模式。让我们详细探讨该算法如何实现模式匹配。
选择时匹配分块和 binlog 模式
当增量快照查询数据库时,行将具有表的最新模式。如果 binlog 流落后,内存中的模式可能与最新模式不同。解决方案是等待连接器在 binlog 流中接收到 DDL 事件。之后,连接器可以使用缓存的表结构来生成正确的增量快照事件。
使用 JDBC API 选择快照分块。ResultSetMetaData 存储分块的模式。挑战在于 ResultSetMetaData 中的模式和 binlog DDL 中的模式格式不同,这使得确定它们是否相同变得困难。
该算法使用两个步骤来获取匹配的基于 ResultSet 和基于 DDL 的模式。首先,连接器查询低水位标记和高水位标记之间的表的模式。一旦连接器检测到窗口关闭,binlog 模式就与 ResultSetMetaData 同步。然后,连接器查询数据库以验证模式是否保持不变。如果模式发生更改,则连接器会重复此过程。
该算法将匹配的 ResultSet 和 binlog 模式保存在内存中,以便连接器可以将每个分块的模式与缓存的 ResultSet 模式进行比较。
当分块的模式与缓存的 ResultSet 模式不匹配时,连接器会丢弃选定的分块。然后,算法会重复验证匹配 ResultSet 和 binlog 模式的过程。之后,连接器会从数据库重新选择相同的分块。
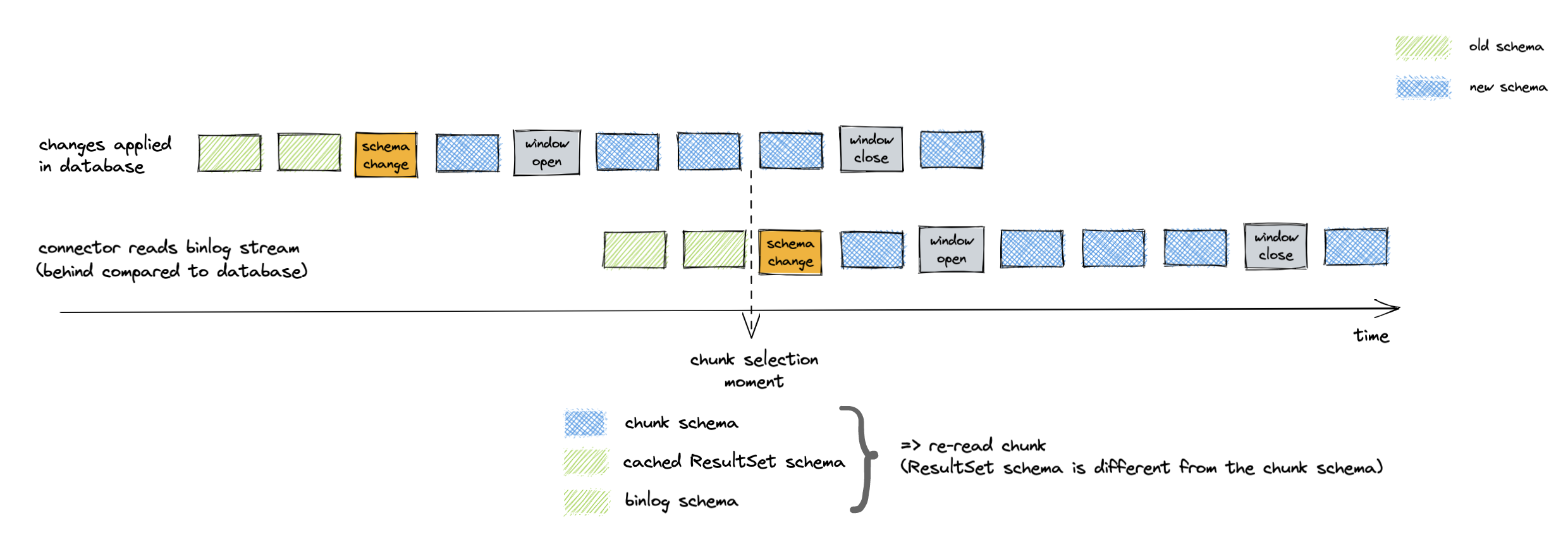
图 5. 在选择分块时,binlog 模式与分块模式不匹配
插入时匹配分块和 binlog 模式
DDL 事件还会触发受影响表的分块重新读取。重新读取可以防止出现窗口关闭时分块模式比 binlog 流旧的场景。例如,下图说明了在模式更改之前选择的分块:
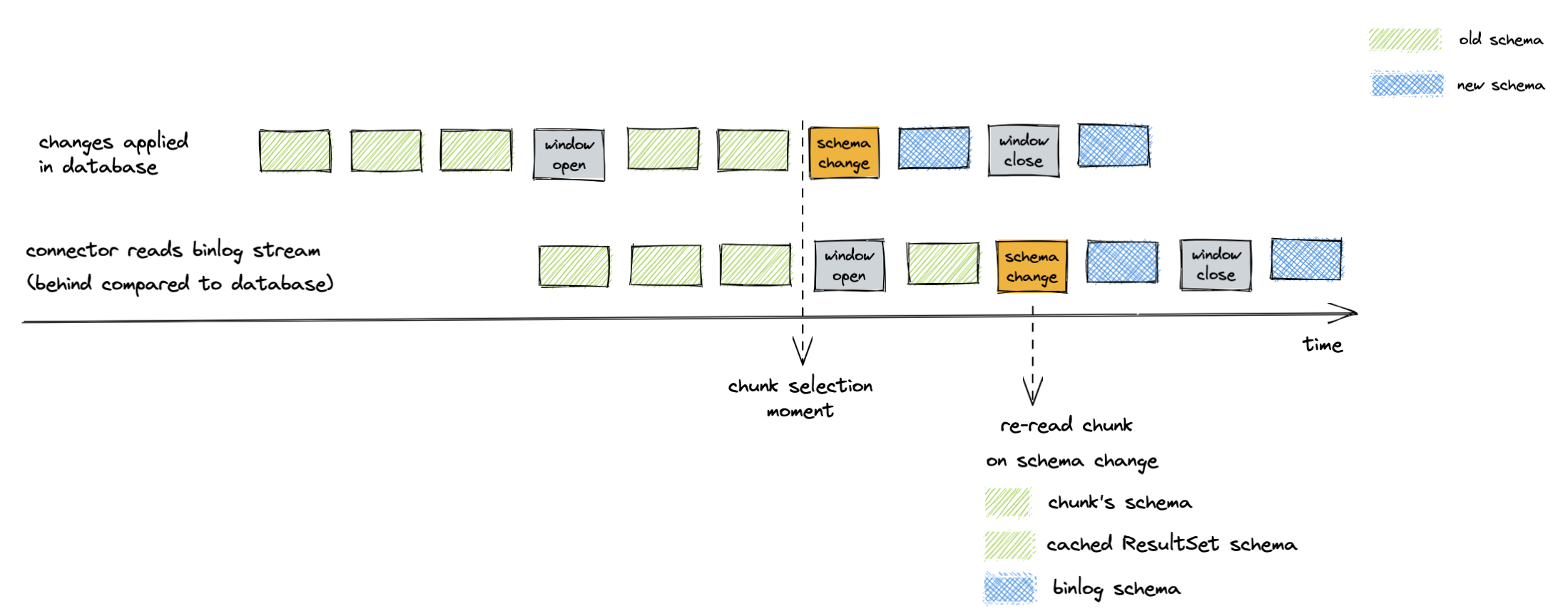
图 6. 在插入分块时,binlog 模式与分块模式不匹配
演示
首先,我们将启动部署,创建信号 Kafka 主题,然后启动连接器。
# Terminal 1 - start the deployment
# Start the deployment
export DEBEZIUM_VERSION=1.9
docker-compose -f docker-compose-mysql.yaml up
# Terminal 2
# Enable enforce_gtid_consistency and gtid_mode
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'mysql -p$MYSQL_ROOT_PASSWORD inventory -e "SET GLOBAL enforce_gtid_consistency=ON; SET GLOBAL gtid_mode=OFF_PERMISSIVE; SET GLOBAL gtid_mode=ON_PERMISSIVE; SET GLOBAL gtid_mode=ON;"'
# Confirm the changes
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'mysql -p$MYSQL_ROOT_PASSWORD inventory -e "show global variables like \"%GTID%\";"'
# Create a signaling topic
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-topics.sh \
--create \
--bootstrap-server kafka:9092 \
--partitions 1 \
--replication-factor 1 \
--topic dbz-signals
# Start MySQL connector, capture only customers table and enable signaling
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" https://:8083/connectors/ -d @- <<EOF
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"table.include.list": "inventory.customers",
"read.only": "true",
"incremental.snapshot.allow.schema.changes": "true",
"incremental.snapshot.chunk.size": "5000",
"signal.kafka.topic": "dbz-signals",
"signal.kafka.bootstrap.servers": "kafka:9092"
}
}
EOF从日志中可以看出,根据 table.include.list 设置,只有一个表被快照,即 customers。
tutorial-connect-1 | 2022-02-21 04:30:03,936 INFO MySQL|dbserver1|snapshot Snapshotting contents of 1 tables while still in transaction [io.debezium.relational.RelationalSnapshotChangeEventSource]
下一步,我们将模拟数据库中的连续活动。
# Terminal 3
# Continuously consume messages from Debezium topic for customers table
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.customers
# Terminal 4
# Modify records in the database via MySQL client
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'i=0; while true; do mysql -u $MYSQL_USER -p$MYSQL_PASSWORD inventory -e "INSERT INTO customers VALUES(default, \"name$i\", \"surname$i\", \"email$i\");"; ((i++)); done'主题 dbserver1.inventory.customers 接收连续的消息流。现在,连接器将被重新配置为也捕获 orders 表。
# Terminal 5
# Add orders table among the captured
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" https://:8083/connectors/inventory-connector/config -d @- <<EOF
{
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"table.include.list": "inventory.customers,inventory.orders",
"read.only": "true",
"incremental.snapshot.allow.schema.changes": "true",
"incremental.snapshot.chunk.size": "5000",
"signal.kafka.topic": "dbz-signals",
"signal.kafka.bootstrap.servers": "kafka:9092"
}
EOF 正如预期的那样,没有 orders 表的消息。
# Terminal 5
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.orders现在,让我们通过发送信号来启动一个增量即席快照。orders 表的快照消息被传递到 dbserver1.inventory.orders 主题。customers 表的消息则不间断地传递。
# Terminal 5
# Send the signal
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-producer.sh \
--broker-list kafka:9092 \
--property "parse.key=true" \
--property "key.serializer=org.apache.kafka.common.serialization.StringSerializer" \
--property "value.serializer=custom.class.serialization.JsonSerializer" \
--property "key.separator=;" \
--topic dbz-signals
dbserver1;{"type":"execute-snapshot","data": {"data-collections": ["inventory.orders"], "type": "INCREMENTAL"}}
# Check messages for orders table
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.orders如果您在快照运行时修改 orders 表中的任何记录,根据确切的时间和事件顺序,它将被发出为 read 事件或 update 事件。
最后一步,我们将终止部署的系统并关闭所有终端。
# Shut down the cluster
docker-compose -f docker-compose-mysql.yaml down结论
Debezium 是一个出色的变更数据捕获工具,正在积极开发中,很高兴能成为其社区的一员。我们非常高兴在 Shopify 生产环境中使用增量快照。如果您有类似的数据库使用限制,请查看只读增量快照功能。非常感谢我的团队和 Debezium 团队,没有他们,这个项目就不会实现。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。