
如今,为分析、报告或机器学习需求构建数据湖已是普遍做法。
在这篇博文中,我们将描述一种构建数据湖的简单方法。该解决方案使用基于 Debezium 的实时数据管道,支持 ACID 事务、SQL 更新,并且高度可扩展。而且,无需 Apache Kafka 或 Apache Spark 应用程序即可构建数据源,从而降低了整体解决方案的复杂性。
让我们从数据湖概念的简要描述开始:数据湖是“通常是数据的中心存储,包括源系统数据的原始副本、传感器数据、社交数据等”。您可以按原样存储数据,而无需先处理数据,然后运行不同类型的分析。
Debezium Server Iceberg
由于操作数据通常存储在关系数据库或 NoSQL 数据存储中,因此问题是如何将数据传播到数据湖。这就是 Debezium Server Iceberg 项目的用武之地:基于 Debezium 和 Apache Iceberg,它可以让您处理来自源数据库的实时数据更改事件,并将它们上传到 Iceberg 支持的任何对象存储。因此,让我们仔细看看这两个项目。
Debezium 是一个开源的分布式变更数据捕获平台。Debezium 从数据库的事务日志中提取更改事件,并通过事件流平台将其传递给消费者,使用 JSON、Apache Avro、Google Protocol Buffers 等不同格式。大多数时候,Debezium 与 Apache Kafka 和 Kafka Connect 一起使用。但通过 Debezium Server,其他消息传递基础设施(如 Kinesis、Google Pub/Sub、Pulsar)的用户也可以从 Debezium 的变更数据捕获功能中受益。在这里,您可以查看当前支持的目的地。
Apache Iceberg 是一个“用于海量分析数据集的开放表格式。Iceberg 为 Spark、Trino、PrestoDB、Flink 和 Hive 等计算引擎添加了表,使用高性能的表格式,其工作方式就像 SQL 表一样。” 它支持 ACID 插入以及行级删除和更新。它提供了一个 Java API 来管理表元数据,如模式和分区规范,以及存储表数据的 data files。
Apache Iceberg 具有数据文件和删除文件的概念。Data files 是 Iceberg 在后台用于保存实际数据的文件的集合。Delete files 是不可变的文件,用于编码现有数据文件中已删除的行。这就是 Iceberg 在不重写文件的情况下删除/替换不可变数据文件中的单个行的方式。对于 Debezium Server Iceberg,这些是不可变的Apache Parquet文件,它是一种格式,与 CSV 或 TSV 文件等基于行的文件相比,它是一种“高效且高性能的平面列式数据存储格式”。
Apache Iceberg 消费者
Debezium Server 提供了一个 SPI 来实现新的 sink 适配器,这就是用于创建 Apache Iceberg 消费者的扩展点。
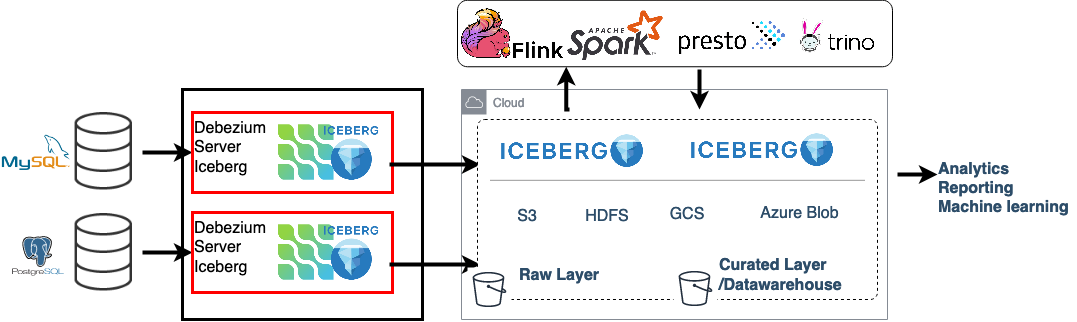
图 1. 架构概述:Debezium Server 和 Apache Iceberg
Iceberg 消费者将 CDC 更改事件转换为 Iceberg data files,并使用 Iceberg Java API 将它们提交到目标表。它将每个 Debezium 源主题映射到一个目标 Iceberg 表。
当给定的 Iceberg 目标表不存在时,消费者会使用更改事件的 schema 来创建它。此外,schema 用于将更改事件本身映射到等效的 Iceberg record。因此,必须设置 debezium.format.value.schemas.enable 配置选项。一旦 Debezium 更改事件被记录到 Iceberg record 中,schema 将从数据中移除。
总的来说,更改事件的处理方式如下。对于每个接收到的事件批次
-
事件按目标 Iceberg 表分组;每个组包含来自单个源表、共享相同数据 schema 的一系列更改事件
-
对于每个目标,事件被转换为 Iceberg records
-
Iceberg records 被保存为 Iceberg data 和 delete files(仅当消费者以 upsert 模式运行时才会创建 delete files)
-
文件被提交到目标 Iceberg 表(即上传到目标存储)
-
已处理的更改事件在 Debezium 中被标记为已处理
以下是使用 Debezium Server 和 Iceberg 适配器的完整配置示例
debezium.sink.type=iceberg
# run with append mode
debezium.sink.iceberg.upsert=false
debezium.sink.iceberg.upsert-keep-deletes=true
debezium.sink.iceberg.table-prefix=debeziumcdc_
debezium.sink.iceberg.table-namespace=debeziumevents
debezium.sink.iceberg.fs.defaultFS=s3a://S3_BUCKET);
debezium.sink.iceberg.warehouse=s3a://S3_BUCKET/iceberg_warehouse
debezium.sink.iceberg.type=hadoop
debezium.sink.iceberg.catalog-name=mycatalog
debezium.sink.iceberg.catalog-impl=org.apache.iceberg.hadoop.HadoopCatalog
# enable event schemas
debezium.format.value.schemas.enable=true
debezium.format.value=json
# complex nested data types are not supported, do event flattening. unwrap message!
debezium.transforms=unwrap
debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
debezium.transforms.unwrap.add.fields=op,table,source.ts_ms,db
debezium.transforms.unwrap.delete.handling.mode=rewrite
debezium.transforms.unwrap.drop.tombstones=trueUpsert 和 Append 模式
默认情况下,Iceberg 消费者以 upsert 模式运行(debezium.sink.iceberg.upsert 设置为 true)。这意味着当源表中的某一行被更新时,目标中的对应行将被新更新的版本替换。当源中的某一行被删除时,它也会从目标中删除。使用 upsert 模式时,目标中的数据与源数据保持一致。upsert 模式使用 Iceberg 上的相等性删除功能,并使用 Debezium 更改数据事件的键(源表主键派生而来)来创建 delete files。为避免重复数据,会针对每个批次进行去重,并只保留记录的最新版本。例如,在单个事件批次中,同一记录可能会出现两次:一次在插入时,另一次在更新时。使用 upsert 模式,始终将记录的最新提取版本存储在 Iceberg 中。
请注意,当源表未定义主键,并且无法通过其他方式(例如,在 Debezium 中定义的唯一键或自定义消息键)获得键信息时,消费者将对此表使用 append 模式(见下文)。
使用 Upsert 模式保留已删除的记录
对于某些用例,保留已删除的记录作为软删除很有用。这可以通过将 debezium.sink.iceberg.upsert-keep-deletes 选项设置为 true 来实现。此设置将保留已删除记录的最新版本在目标 Iceberg 表中。将其设置为 false 将从目标表中删除已删除的记录。
Append 模式
这是最直接的操作模式,通过将 debezium.sink.iceberg.upsert 设置为 false 来启用。当使用 Debezium Server Iceberg 的 append 模式时,所有接收到的记录都会被追加到目标表中。不会进行数据去重或记录删除。使用 append 模式可以分析记录的整个更改历史。
| 还可以消耗实时事件,然后稍后使用单独的 compaction 作业进行数据压缩。Iceberg 支持压缩数据和元数据文件以提高性能。 |
优化批次大小
Debezium 实时提取和传递数据库事件,这可能导致对 Iceberg 表的提交过于频繁,产生过多的小文件。这对于批处理来说不是最优的,特别是当近实时数据馈送足够时。为了避免此问题,可以增加每次提交的批次大小。
启用 MaxBatchSizeWait 模式后,Iceberg 消费者使用 Debezium 指标来优化批次大小。它会定期检索 Debezium 内部事件队列的当前大小,并等待直到达到 max.batch.size。在等待期间,Debezium 事件会在内存中(在 Debezium 的内部队列中)收集。这样,每次提交(处理的事件集)可以处理更多记录,并实现一致的批次大小。最长等待时间和检查间隔通过 debezium.sink.batch.batch-size-wait.max-wait-ms 和 debezium.sink.batch.batch-size-wait.wait-interval-ms 属性进行控制。这些设置应与 Debezium 的 debezium.source.max.queue.size 和 debezium.source.max.batch.size 属性一起配置。
以下是所有相关设置的示例
debezium.sink.batch.batch-size-wait=MaxBatchSizeWait
debezium.sink.batch.batch-size-wait.max-wait-ms=60000
debezium.sink.batch.batch-size-wait.wait-interval-ms=10000
debezium.sink.batch.metrics.snapshot-mbean=debezium.postgres:type=connector-metrics,context=snapshot,server=testc
debezium.sink.batch.metrics.streaming-mbean=debezium.postgres:type=connector-metrics,context=streaming,server=testc
# increase max.batch.size to receive large number of events per batch
debezium.source.max.batch.size=50000
debezium.source.max.queue.size=400000创建额外的数据湖层
此时,数据湖的原始层已加载,包括数据去重和近实时管道功能。在此之上构建经过精心处理的层(有时称为分析层或数据仓库层)变得非常直接和简单。在分析层,原始数据被准备以满足分析需求;通常,原始数据会被重新组织、清理、版本化(参见下面的示例)、聚合,并可能应用业务逻辑。使用可伸缩处理引擎通过 SQL 进行此类数据转换是最常见的方式。
MERGE INTO dwh.consumers t
USING (
-- new data to insert
SELECT customer_id, name, effective_date, to_date('9999-12-31', 'yyyy-MM-dd') as end_date
FROM debezium.consumers
UNION ALL
-- update exiting records. close end_date
SELECT t.customer_id, t.name, t.effective_date, s.effective_date as end_date
FROM debezium.consumers s
INNER JOIN dwh.consumers t on s.customer_id = t.customer_id AND t.current = true
) s
ON s.customer_id = t.customer_id AND s.effective_date = t.effective_date
-- close last records/versions.
WHEN MATCHED
THEN UPDATE SET t.current = false, t.end_date = s.end_date
-- insert new versions and new data
WHEN NOT MATCHED THEN
INSERT(customer_id, name, current, effective_date, end_date)
VALUES(s.customer_id, s.name, true, s.effective_date, s.end_date);其他数据湖层可能需要定期使用新数据进行更新。最简单的方法是使用 SQL 更新或删除语句。这些 SQL 操作也受到 Iceberg 的支持。
INSERT INTO prod.db.table SELECT ...;
DELETE FROM prod.db.table WHERE ts >= '2020-05-01 00:00:00' and ts < '2020-06-01 00:00:00';
DELETE FROM prod.db.orders AS t1 WHERE EXISTS (SELECT order_id FROM prod.db.returned_orders WHERE t1.order_id = order_id;
UPDATE prod.db.all_events
SET session_time = 0, ignored = true
WHERE session_time < (SELECT min(session_time) FROM prod.db.good_events));总结与贡献
基于 Debezium 和 Apache Iceberg,Debezium Server Iceberg 使设置数据湖的低延迟数据摄取管道变得非常简单。该项目完全开源,使用 Apache 2.0 许可证。Debezium Server Iceberg 仍然是一个年轻的项目,还有许多可以改进的地方。请随时测试它、提供反馈、提交功能请求或发送 pull 请求。您可以通过此项目查看更多示例,并开始尝试 Iceberg 和 Spark。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。