
在 ScyllaDB,我们开发高性能的 NoSQL 数据库 Scylla,它与 Apache Cassandra、Amazon DynamoDB 和 Redis API 兼容。今年早些时候,我们在 Scylla 4.3 中引入了对 变更数据捕获 (CDC) 的支持。这项新功能似乎与 Apache Kafka 生态系统集成非常契合,因此我们使用 Debezium 框架开发了 Scylla CDC 源连接器。在这篇博文中,我们将介绍 Scylla CDC 的基本结构,我们选择 Debezium 框架的原因以及我们做出的设计决策。
Scylla 中的 CDC 支持
变更数据捕获(CDC)允许用户跟踪 Scylla 数据库中的数据修改。它可以轻松地在任何 Scylla 表上启用/禁用。启用后,所有修改(INSERT、UPDATE、DELETE)的日志将被创建并自动更新。
在设计 Scylla 中的 CDC 实现时,我们希望让 CDC 日志的消费变得容易。因此,CDC 日志被存储为常规的 Scylla 表,可通过任何现有的 CQL 驱动程序访问。当对启用了 CDC 的表进行修改时,关于该操作的信息将被保存到 CDC 日志表中。
这是一个快速的演示:首先,我们将创建一个启用了 CDC 的表
CREATE TABLE ks.orders(
user text,
order_id int,
order_name text,
PRIMARY KEY(user, order_id)
) WITH cdc = {'enabled': true};接下来,让我们执行一些操作
INSERT INTO ks.orders(user, order_id, order_name)
VALUES ('Tim', 1, 'apple');
INSERT INTO ks.orders(user, order_id, order_name)
VALUES ('Alice', 2, 'blueberries');
UPDATE ks.orders
SET order_name = 'pineapple'
WHERE user = 'Tim' AND order_id = 1;最后,让我们查看修改后的表的内容
SELECT * FROM ks.orders;
user | order_id | order_name
------+----------+-------------
Tim | 1 | pineapple
Alice | 2 | blueberries仅看这张表,您无法重构发生的所有修改,例如,在 UPDATE 之前 Tim 的订单名称。让我们看看 CDC 日志,可以方便地作为一张表访问(为清晰起见,部分列已截断)
SELECT * FROM ks.orders_scylla_cdc_log;
cdc$stream_id | cdc$time | | cdc$operation | order_id | order_name | user
---------------+----------+-...-+---------------+----------+-------------+----------
0x2e46a... | 7604... | ... | 2 | 1 | apple | Tim
0x2e46a... | 8fdc... | ... | 1 | 1 | pineapple | Tim
0x41400... | 808e... | ... | 2 | 2 | blueberries | Alice所有三个操作都显示在 CDC 日志中。有两个 INSERT(cdc$operation = 2)和一个 UPDATE(cdc$operation = 1)。对于每个操作,其时间戳也保存在 cdc$time 列中。时间戳被编码为基于时间的 UUID 值,如 RFC 4122 规范所述,可以使用 Scylla 驱动程序中的辅助方法进行解码。
选择 Debezium
当我们在考虑客户如何访问 CDC 日志时,将其与 Kafka 一起使用似乎是最方便的方法。因此,我们决定为 Scylla CDC 开发一个源连接器。
作为第一个概念验证,我们使用 Kafka Connect API 实现了一个源连接器。这个原型对于我们确定连接器是否能水平扩展(将在本文的后面讨论)至关重要。
然而,我们很快意识到,仅使用 Kafka Connect API,我们将不得不重写许多在其他连接器中已有的功能。我们也希望我们的连接器在 Kafka 社区中成为一个“好公民”,遵循最佳实践和约定。这正是我们选择 Debezium 的原因!
因此,当您启动 Scylla CDC 源连接器时,配置参数将立即变得熟悉,因为其中许多参数与其他 Debezium 连接器是通用的。生成的变更数据事件具有与由其他 Debezium 连接器生成的 Envelope 结构相同的结构。这种相似性允许使用许多标准的 Debezium 功能,例如 New Record State Extraction(新记录状态提取)。
事件表示
在我们决定使用 Debezium 框架后,我们研究了 Scylla CDC 操作应如何在 Debezium 的 Envelope 格式中表示。
Envelope 格式包含以下字段:
-
op- 操作类型:c表示创建,u表示更新,d表示删除,r表示读取 -
before- 事件发生前行的状态 -
after- 事件发生后行的状态 -
source- 事件的元数据 -
ts_ms- 连接器处理事件的时间
将 Scylla 操作映射到 op 字段相对容易:INSERT 为 c,UPDATE 为 u,DELETE 为 d。
我们决定跳过跨越多行的 DELETE 事件,例如范围 DELETE。
DELETE FROM ks.table
WHERE pk = 1 AND ck > 0 AND ck < 5表示此类操作将不必要地使格式复杂化,以便容纳额外的范围信息。此外,它将打破 Envelope 代表单个行修改的预期。
在 Scylla CDC 中,范围 DELETE 以两条记录的形式存储在 CDC 表中:第一条记录编码有关已删除范围开始的信息(在上面的示例中:pk = 1, ck > 0),第二条记录编码有关已删除范围结束的信息(在上面的示例中:pk = 1, ck < 5)。在该范围内存在的每条记录的信息均未持久化。这对应于 Scylla 中的 DELETE 操作会生成数据库中的墓碑。
默认情况下,Scylla 的 CDC 仅存储主键和操作的修改后的列。例如,假设我创建了一个表并插入了一行
CREATE TABLE ks.example(
pk int,
v1 int,
v2 int,
v3 int,
PRIMARY KEY(pk)) WITH cdc = {'enabled': true};
INSERT INTO ks.example(pk, v1, v2, v3)
VALUES (1, 2, 3, 4);在 Scylla 中,您可以发出另一个 INSERT 语句,该语句将覆盖其中一些列
INSERT INTO ks.example(pk, v1, v3)
VALUES (1, 20, null);v2 列在此查询后未被更改,我们也没有关于其先前值的信息。
我们必须能够表示三种可能性:列未被修改,列被赋值为 NULL,或者列被赋值为非 NULL 值。我们选择的表示方式受到 Debezium Cassandra 连接器 的启发,该连接器通过将列的值包装在结构中来工作
"v1": {"value": 1},
"v2": null,
"v3": {"value": null}null 结构值表示列未被修改(v2 字段)。如果列被赋值为 NULL 值(v3 字段),则将有一个带有 NULL value 字段的结构。非 NULL 列赋值(v1 字段)将填充 value 字段的内容。这种格式使我们能够正确表示所有可能性,并区分赋值 NULL 和未修改。
但是,大多数 sink 连接器将无法正确解析此类结构。因此,我们决定开发自己的 SMT,基于 Debezium 的 New Record State Extraction SMT。我们的 ScyllaExtractNewState SMT 通过应用 Debezium 的 New Record State Extraction 并展平 {"value": …} 结构来工作(但代价是无法区分 NULL 值和缺失的列值)。
"v1": 1,
"v2": null,
"v3": nullScylla 的 CDC 还支持为每次操作记录前映像和后映像(需要额外成本)。我们计划在 Scylla CDC 源连接器的未来版本中增加对它们的 D支持。
水平扩展
即使在概念验证阶段,出色的性能也是一项基本要求。Scylla 数据库可以扩展到数百个节点和 PB 级别的数据,因此很明显,单个 Kafka Connect 工作节点(即使是多线程的)也无法处理大型 Scylla 集群的负载。
值得庆幸的是,我们在 Scylla 中实现 CDC 功能时考虑了这一点。通常,您可以将变更数据捕获视为一个按时间排序的变更队列。为了实现水平扩展,Scylla 维护一组多个按时间排序的变更队列,称为流(streams)。当只有一个 CDC 日志的消费者时,它必须查询所有流才能正确读取所有变更。这种设计的优点是可以引入额外的消费者,为每个消费者分配一个不相交的流集。结果是,您可以大大提高 CDC 日志处理的并行度。
这就是我们在 Scylla CDC 源连接器中实现的方法。启动时,连接器首先读取所有可用流的标识符。然后,它将这些流分发给多个 Kafka Connect 任务(可通过 tasks.max 配置)。
每个创建的 Kafka Connect 任务(可以在单独的 Kafka Connect 节点上运行)都从其分配的流集中读取 CDC 变更。如果您将任务数量加倍,每个任务只需读取一半数量的流——数据吞吐量减半,从而能够处理更高的负载。
解决大量流计数问题
在设计 Scylla 的 CDC 功能时,我们必须仔细选择要创建的流的数量。如果我们选择的流太少,消费者可能无法跟上单个流的数据吞吐量。这也会减慢 INSERT、UPDATE、DELETE 操作的速度,因为许多并发操作将争夺对单个流的访问。然而,如果 Scylla 创建了太多的流,消费者将不得不向 Scylla 发出大量查询(以覆盖每个流),造成不必要的负载。
Scylla 中 CDC 的当前实现会为每个集群创建 number_of_nodes * number_of_vnodes_per_node * number_of_shards 个流。VNodes 的数量指的是 Scylla 使用 Ring 架构,每个节点默认有 256 个 VNodes。每个 Scylla 节点由多个独立的分片组成,这些分片包含节点总数据的一部分。通常,每个超线程或物理核心有一个分片。
例如,如果您创建一个 4 节点 i3.metal(每个节点 72 个 vCPU)Scylla 集群,该集群能够处理大约每秒 600k 次操作(一半是 INSERT,一半是 SELECT),那么这将是:4 * 256 * 72 = 73728 个流。
我们很快意识到,在更大的集群中,如此多的流可能会成为一个问题
-
向 Scylla 发出过多查询——每个流一个查询
-
过多的 Kafka Connect 偏移量——每个流一个偏移量。存储偏移量意味着连接器在崩溃后可以从上次保存的位置恢复。
为了缓解这些问题,我们决定在客户端进行流分组。我们选择按 VNode 对流进行分组。这使得数量从 number_of_nodes * number_of_vnodes_per_node * number_of_shards 减少到 number_of_nodes * number_of_vnodes_per_node。在 4 节点 i3.metal 的情况下,这意味着从 73728 减少到 1024:只有 1024 个查询到 Scylla,以及 1024 个存储在 Kafka 上的偏移量。
然而,我们仍然对存储在 Kafka 上的偏移量数量感到不安。当我们查看其他连接器时,大多数连接器只为每个复制的表存储一个偏移量或最多几十个偏移量(因此扩展性有限)。
为了理解为什么将数千个流存储在 Kafka Connect 中可能是一个问题,让我们看看它的工作原理。源连接器创建的每个 Kafka Connect 记录都包含一个键/值偏移量,例如:键 - my_table;偏移量 - 25,这可能表示连接器已完成在 my_table 中读取 25 行。定期(由 offset.flush.interval.ms 配置),这些偏移量将被刷新到一个名为 connect-offsets 的 Kafka 主题中,作为常规 Kafka 消息。
不幸的是,Kafka 不是一个键值存储。当连接器启动时,它必须扫描 connect-offsets 主题上的所有消息以找到它需要的消息。当它更新之前保存的偏移量时,它只是将新值追加到该主题,而不删除之前的条目。对于只有一个偏移量的连接器来说,这不是问题——当每分钟更新一次时,这个主题在一周后将持有大约 10,000 条消息。然而,在 Scylla CDC 源连接器的情况下,这个数字可能要大几个数量级!
幸运的是,可以通过为 connect-offsets 主题设置更积极的压缩配置来轻松缓解此问题。默认配置的 retention.ms 为 7 天,segment.bytes 为 1GB,该主题在短短几个小时后(对于具有数十个节点和非常小的 offset.flush.interval.ms 的 Scylla 集群)可能会增长到几百兆字节。这使得连接器的启动时间变慢,因为它需要在启动/重启后扫描整个偏移量主题。通过调整 segment.bytes、segment.ms 或 cleanup.policy、retention.ms,我们能够缓解问题并显著减小 connect-offsets 主题的大小。前两个选项指定日志压缩过程的频率。当一个段被压缩时,具有相同键的所有消息将被缩减为最新的一个(最新偏移量)。或者,设置更短的保留时间(但比 Scylla 的 CDC 保留时间长)被证明是减小偏移量主题大小的好选择。
基准测试:近乎线性的扩展
为了验证我们的连接器是否真的可以水平扩展,我们进行了一项基准测试,以测量在不断增大的 Kafka Connect 集群上 Scylla CDC 源连接器的最大吞吐量。
首先,我们启动了一个单节点 i3.4xlarge Scylla 集群(基于官方 Scylla AMI)。接下来,我们在一个启用了 CDC 的表上插入了 5000 万行(总大小 5.33GB)。之后,我们在 1、3 或 5 个节点(r5n.2xlarge)上启动了一个 Apache Kafka 2.6.0 集群和 Kafka Connect 集群。我们启动了 Scylla CDC 源连接器来消费之前填充的启用了 CDC 的表中的数据,并测量了生成所有 5000 万条 Kafka 消息所需的时间。
我们的连接器能够近乎线性地扩展吞吐量
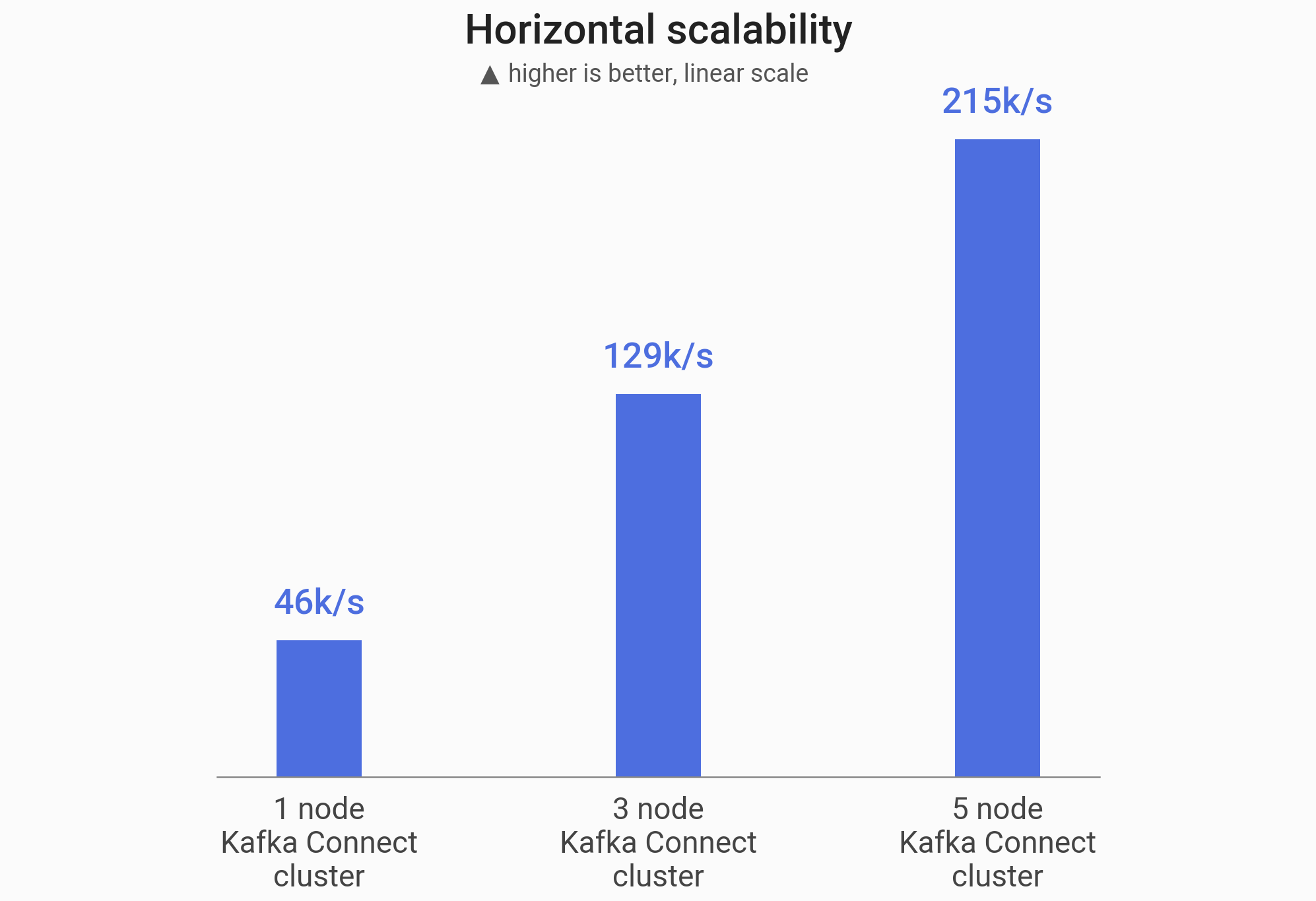
| Kafka 集群大小 | 吞吐量 | 加速比 |
|---|---|---|
1 个节点 | 46k/秒 | 1 倍 |
3 个节点 | 129k/秒 | 2.8 倍 |
5 个节点 | 215k/秒 | 4.7 倍 |
结论
在这篇博文中,我们深入探讨了 Scylla CDC 源连接器的开发。我们从 Scylla 中 CDC 实现的概述开始。我们讨论了选择 Debezium 而不是仅仅使用 Kafka Connect API 来构建连接器的原因,从而使其对用户来说熟悉且符合 Kafka 的习惯。接下来,我们研究了遇到的两个问题:如何表示 Scylla 变更以及如何使连接器可扩展。
我们非常期待通过更多功能继续改进我们的连接器,并使其性能更上一层楼。我们热切地期待着 Debezium 生态系统的发展,并集成 Debezium 最新版本中引入的功能。
如果您想亲自查看此连接器,其源代码的 GitHub 存储库可在以下位置找到:github.com/scylladb/scylla-cdc-source-connector。您可以在这里了解更多关于 Scylla 的信息:scylladb.com。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。