
欢迎来到最新一期的“Debezium 社区故事”,这是一系列对 Debezium 和变更数据捕获社区成员(如用户、贡献者或集成商)的采访。今天,我很高兴能与 Sergei Morozov 对话。

Sergei,您能介绍一下自己吗?如果您不为 Debezium 贡献,您的工作是什么?
大家好,我叫 Sergei,是 SugarCRM 的软件架构师。我的大部分职业生涯都在构建基于 LAMP 堆栈的软件。几年前,我的团队开始构建一个数据流平台,旨在集成现有的 SugarCRM 产品以及我们希望在这些产品之上构建的新服务。我们开始使用 Maxwell's Daemon、AWS Kinesis 和 DynamoDB 对平台进行原型设计,后来切换到 Kafka、Kafka Connect 和 Debezium。
有趣的是,Debezium 是我们开始尝试 Kafka 生态系统的原因。在转型之前我们构建的解决方案只能流式传输 CDC 变更,而不能快照初始状态。在进行快照工作期间,我们偶然发现了 Debezium 并发现了 Kafka。经过一番尝试并了解了更多关于生态系统的信息后,我们决定切换技术栈。
在您当前的项目中,Debezium 和变更数据捕获的用例是什么?
我们从基于 MySQL 和 SQL Server 的产品中捕获数据变更,并使用它们来支持 AI 和数据分析用例。除了处理最近的变更,我们还尽可能多地存储历史数据。这些数据来自云环境中数千个客户数据库。
我们将其用于 AI、分析和支持未来的用例。例如,SugarPredict 提供商机评分,帮助销售代表专注于那些更有可能成交的商机。来自 CRM 和其他来源的历史数据用于训练 AI 模型。数据变更事件用于运行评分过程和更新预测。
从数据流的角度来看,它看起来非常简单,但由于产品的灵活性和云规模,存在一些工程挑战。
这听起来很有趣;您能告诉我们您遇到的挑战以及如何解决它们吗?
当然。让我详细介绍一下。我希望我们的想法和解决方案能对社区有所帮助。
灵活性和数据序列化
提供数据变更的产品具有极高的可定制性。客户可以创建新的模块、字段、安装扩展等,从 CDC 的角度来看,这意味着客户可以完全控制数据库 schema。再加上数千个客户的规模,这使得使用 Apache Avro 变得具有挑战性,因为它意味着 schema 由开发人员管理。
几年前,我们测试了当时的实际标准 Schema Registry,并得出结论,它在云端大约一百万条消息 schema 的规模下表现不佳,更不用说数量无限的 schema 版本了。相比之下,该 schema 注册表附带的托管服务最多可存储一千个 schema。因此,我们求助于使用 JSON 来序列化数据。
入职挑战
SugarCloud 是 SugarCRM 产品的多租户托管环境。它由几十个大型 MySQL 兼容的 AWS Aurora 集群组成,每个集群通常托管一百到一千个客户数据库。集群存储大小从几百 GB 到 5 TB 不等。
当 Debezium 的 MySQL 连接器首次启动时,它会执行初始一致快照,为了保证一致性,它通常会获取一个短暂的全局读锁来捕获所有相关表的 schema。由于 AWS Aurora 不允许执行全局锁,Debezium 必须在快照的整个持续时间内单独锁定所有表。
数据库集群的快照需要几个小时到几天的时间,这是我们无法承受的,因为它会要求给定集群上托管的所有客户实例停机。幸运的是,我们偶然发现了 The Data Guy 的精彩文章 Debezium MySQL Snapshot For AWS RDS Aurora From Backup Snaphot,它描述了一种变通方法,使我们能够在不导致任何应用程序停机的情况下快照所有数据。我们实现了一个 shell 脚本,该脚本克隆数据库集群,记录生成克隆的 binlog 位置,对克隆进行快照,然后重新配置连接器以从快照的位置流式传输。
实例生命周期管理
SugarCloud 是一个非常动态的环境。一旦客户数据库部署到其中一个集群中,就不能保证它在整个生命周期中都保留在那里。数据库可以备份和恢复。它可以为了负载均衡而在同一 AWS 区域的集群之间移动。如果客户要求,它可以从一个 AWS 区域移动到另一个区域。
我们的源连接器配置为从给定集群上的所有数据库捕获所有数据变更,但并非所有这些变更从数据消费者的角度来看都是有意义的。例如,当数据库从另一个集群上的备份中恢复时,mysqldump 生成的 INSERT 语句不代表新行。它们代表备份期间数据库的状态,应该被忽略。
为了实现原始数据的后处理,每个集群上都有一个系统数据库,集群管理系统将所有与实例生命周期相关的事件记录到其中(参见outbox 模式)。
为了根据生命周期事件对原始数据进行后处理,我们构建了一个 Kafka Streams 应用程序,该应用程序部署在 Debezium 和实际数据消费者之间。在内部,它使用了一个状态存储,该存储实际上是每个客户数据库状态(活动/维护)的投影。在从 SQL dump 恢复数据库之前,数据库被标记为“维护中”(一个事件被发送到 outbox),因此所有相应的 INSERTs 都将被忽略,直到维护结束(另一个事件被发送)。
存储
存储所有历史数据的需求带来了足够的存储挑战。自去年年底以来,我们已收集了超过 120TB 的压缩 CDC 事件。目前我们将历史数据存储在 S3 中,但计划在 AWS MSK 中提供 S3 支持的分层存储(KIP-405)后将其移回 Kafka。
基础设施
我们的软件主要运行在 Kubernetes 中,除了 broker 本身,我们所有的 Kafka 相关基础设施都由 Strimzi 管理。Strimzi 不仅允许使用相同的工具管理应用程序和 Kafka 资源,它还为自动化提供了坚实的基础。
当我们开始设计数据流平台时,其中一个要求是它应该自动适应 SugarCloud 中的某些变化。例如,当部署一个新的 Aurora 集群时,应该为这个集群部署数据流管道。另一个要求是管道应该部署在多个 AWS 区域,并通过 Sugar 的单一控制平面(代号 Mothership)进行管理。我们深入一层,构建了 Mothership Operator,它充当管理管道的 API。
当创建一个新的 Aurora 集群时,Mothership 在 Vault 中创建一个包含数据库凭证和 StackIngestor 的秘密。StackIngestor 包含有关 Aurora 集群的信息:其 AWS 区域、MySQL 端点、Vault 秘密的名称以及其他技术信息。Mothership Operator 订阅 StackIngestor 中的变化,并管理实现管道的 Kafka 资源。
除了一些例外,每个管道都部署在 Aurora 集群所在的同一 AWS 区域。每个区域都部署了 Strimzi Topic 和 Cluster 操作符。管道由几个 Kafka 主题、一个源连接器(Debezium)、一个目标连接器(S3)组成,并运行在共享或专用的 Kafka Connect 集群上。对于在主区域中创建的每个 StackIngestor,Mothership Operator 在区域 Kubernetes 集群中创建所需的 Strimzi 资源。Strimzi 操作符订阅其资源的更新并管理 Kafka 中的相应资源。
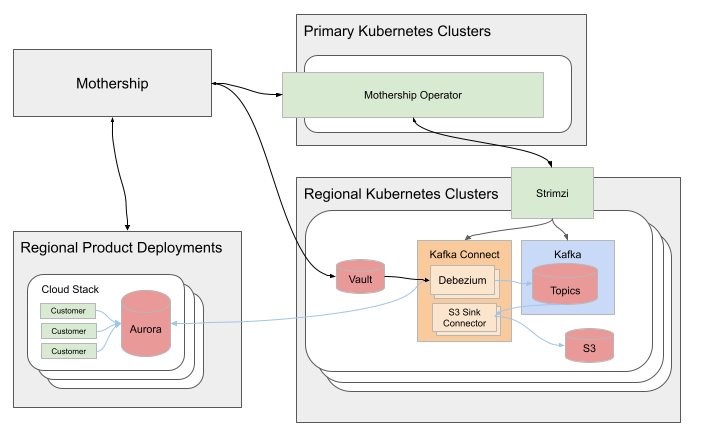
图 1. 系统概览
我们还使用 Strimzi 将 Debezium 的 JMX 指标导出到 Prometheus。Prometheus 指标在 Grafana 中可视化。我们从一个社区仪表板(也由 The Data Guy 提供)开始,并对其进行了改进,以更好地适应多租户用例。
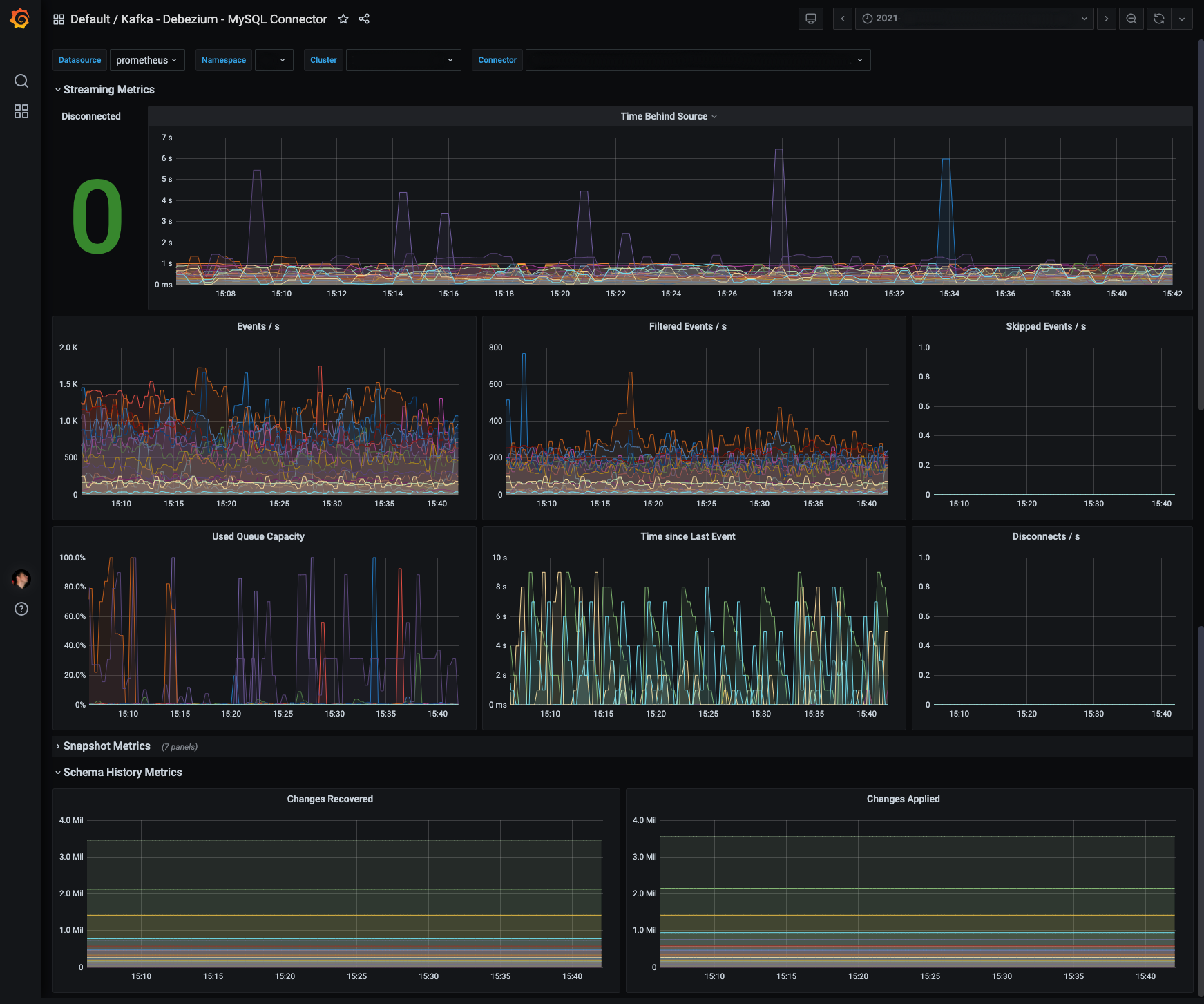
图 2. 多租户 Debezium 仪表板
您不仅使用 Debezium,还为该项目做出了贡献。您的体验如何?
根据我的经验,无论我接触什么开源软件——无论是在工作中还是为了乐趣——我总是最终发现该软件中有些地方需要改进才能支持我的用例。
我早在 2020 年 10 月就为 Debezium(或者更确切地说,是它的依赖项 mysql-binlog-connector-java)贡献了我的第一个补丁。我们当时刚刚将第一个连接器之一投入生产,并遇到了一个问题,即连接器消耗所有可用内存并在 binlog 的特定位置崩溃。这个问题非常紧迫,因为在 binlog 压缩启动之前我们时间非常有限,否则我们可能会开始丢失数据。与此同时,我们对 Debezium 和 Kafka Connect 架构只有基本的了解,并且对 Debezium 内部结构没有经验。
整个团队都涌了过来,发现连接器错误地解释了 AWS Aurora 生成的一个非标准 binlog 事件,而不是忽略它。故障排除和查找根本原因是最困难的部分。修复问题并进行单元测试相对容易。尽管这个改变并不那么明显,但我很高兴它被团队及时接受并得到了建设性的反馈。
您还在做其他开源工作吗?
我是 PHP 中最流行的关系数据库库 Doctrine DBAL 的维护者之一。我第一次在那里做出贡献是在我致力于将该库集成到 SugarCRM 核心产品中,并修复了一些阻碍集成的错误。经过几次发布才全部修复,最终我被邀请加入了核心团队。
除此之外,我偶尔还会为 PHP 生态系统中的一些开源项目做贡献:主要是那些我每天都会使用的,比如 PHPBrew、PHPUnit、PHP_CodeSniffer、Vimeo Psalm 和 PHP 本身。
Debezium 有没有什么您缺少的功能,或者您希望将来改进的地方?
虽然 Debezium 是一个出色的工具,涵盖了大多数行业标准的数据库平台,但我们团队面临的最大挑战仍然是如何将 Debezium 扩展到我们客户群的规模。SQL Server 连接器目前只能处理每个连接器一个逻辑数据库。我们有数百个客户数据库托管在 SQL Server 上,但为每个数据库运行专用连接器将需要昂贵的基础设施,并且难以管理。
今年早些时候,我们开始与 Debezium 团队合作,改进连接器,使其能够从多个数据库捕获变更并运行多个任务。这样,我们就可以运行十几个左右的连接器,而不是数百个。最初的设计在 DDD-1 中有所概述。
实施这些更改后,我们其中一个生产连接器从一百多个数据库捕获变更。与此同时,我们正在努力将这些更改贡献回上游。
额外问题:数据工程的下一个大事件是什么?
如今,特别是在多租户环境中,很难预测从“在我的机器上运行”到“在云规模上运行”需要多长时间。我期待着容器编排和数据流平台变得像 PowerPoint 图表上看起来那么简单易用的那一天。
Sergei,非常感谢您抽出时间,很高兴能邀请您!
如果您想与 Sergei Morozov 保持联系并与他讨论,请在下方留言或 在 Twitter 上关注并联系他。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。