
本文最初发布于 Bolt Labs Engineering 博客。
传统上,Bolt 的大部分后端服务都由 MySQL 提供支持。我们设计了数据库模式,使其分片到不同的 MySQL 集群中。每个 MySQL 集群包含一部分数据,并由一个主节点和多个复制节点组成。
一旦数据持久化到数据库,我们就使用 Debezium MySQL 连接器来捕获数据更改事件并将其发送到 Kafka。这为我们提供了一种轻松可靠的方式来在后端微服务之间通信更改。
Bolt 的 Vitess
Bolt 在过去几年中取得了显著增长,写入 MySQL 的数据量也随之增加。手动分片数据库已成为一个成本高昂且耗时且易出错的过程。因此,我们开始评估更具可扩展性的数据库,其中之一就是 Vitess。Vitess 是一个基于 MySQL 的开源数据库集群系统,为 MySQL 提供水平扩展能力。它起源于 YouTube 并经过实战考验,后来开源,并被 Slack、Github、JD.com 等公司用于支持其后端存储。它将重要的 MySQL 功能与 NoSQL 数据库的可扩展性结合在一起。
Vitess 提供的一个最重要的功能是其内置的分片。它允许数据库通过添加新的分片来水平扩展,而这对后端应用程序逻辑是透明的。对您的应用程序而言,Vitess 看起来就像一个巨大的单个数据库,但实际上数据在后台被分区到多个物理分片中。对于任何表,都可以选择任意列作为分片键,Vitess 会自动将所有插入和更新无缝定向到相应分片。
下图 1 展示了后端服务如何与 Vitess 交互。总体而言,服务通过负载均衡器连接到无状态的 VTGate 实例。每个 VTGate 都在其内存中缓存了 Vitess 集群的拓扑,并将查询重定向到分片内的正确分片和正确的 VTTablet(及其底层 MySQL 实例)。下面将详细介绍 VTTablet。
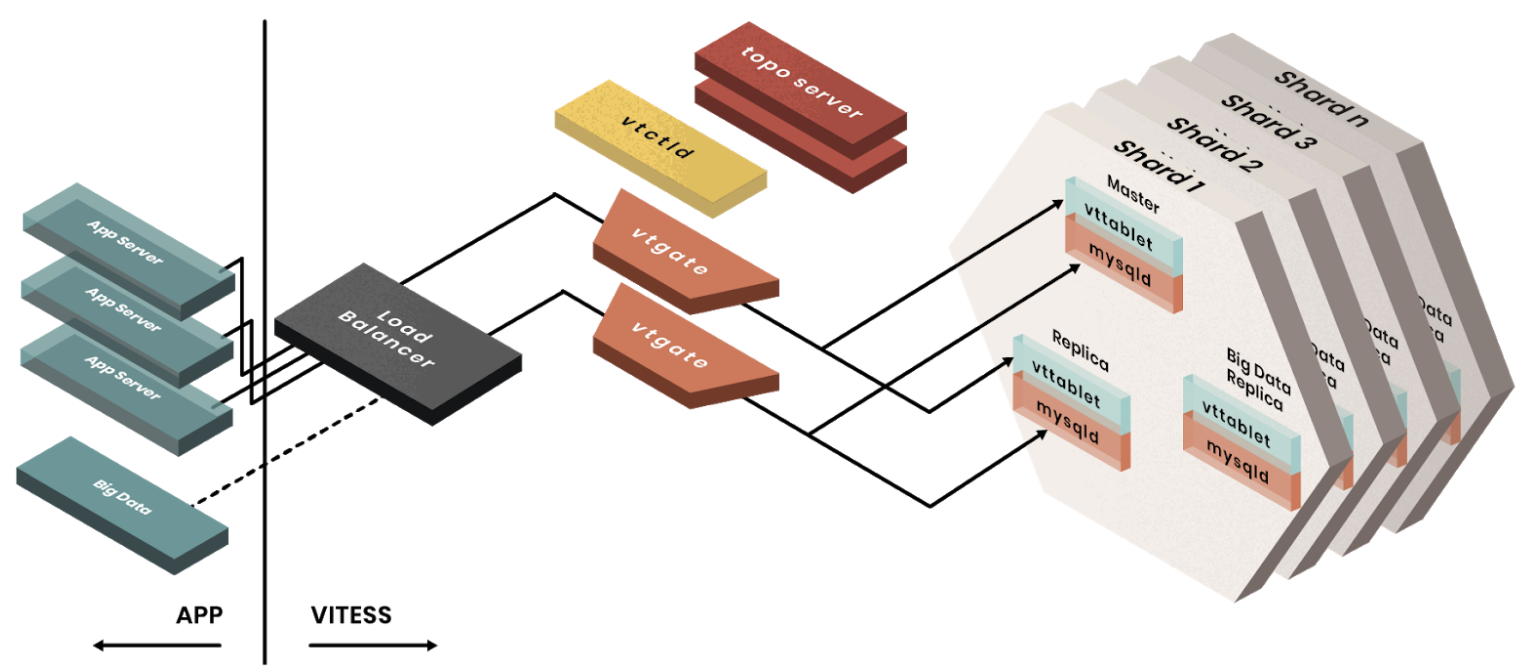
图 1. Vitess 架构。参考:https://www.planetscale.com/vitess
Vitess 提供的其他有用功能包括:
-
故障转移(又称 Reparenting)对客户端来说是简单透明的。客户端只需与 VTGate 通信,VTGate 会透明地处理故障转移和新主节点的服务发现。
-
它会自动重写“有问题”的查询,这些查询可能会导致数据库性能下降。
-
它具有缓存机制,可以防止重复查询同时到达底层 MySQL 数据库。只有一个查询会到达数据库,其结果将被缓存并用于响应重复查询。
-
它具有连接池,消除了 MySQL 连接的高内存开销。因此,它可以轻松同时处理数千个连接。
-
可以配置连接超时和事务超时。
-
在进行重新分片操作时,停机时间最少。
-
下游 CDC 应用程序可以使用其 VStream 功能从 Vitess 读取更改事件。
流式传输 Vitess 选项
捕获数据更改并将其发布到 Apache Kafka 的能力是 Bolt 采用 Vitess 的要求之一。我们考虑了几种不同的选项。
选项 1:使用 Debezium MySQL 连接器
应用程序连接到 Vitess VTGate 发送查询。VTGate 支持 MySQL 协议并具有 SQL 解析器。您可以使用任何 MySQL 客户端(例如 JDBC)连接到 VTGate,VTGate 会将您的查询重定向到正确的分片并向您的客户端返回结果。
但是,VTGate 并不等同于 MySQL 实例,它更像是一个到各个 MySQL 实例的无状态代理。为了让 MySQL 连接器接收更改事件,Debezium MySQL 连接器需要连接到真实的 MySQL 实例。为了更清楚地说,VTGate 在兼容性方面也有一些已知问题,这使得连接到 VTGate 与连接到 MySQL 不同。
另一种选择是使用 Debezium MySQL 连接器直接连接到不同分片的底层 MySQL 实例。这有其优点和缺点。
一个优点是,对于未分片键空间(Vitess 的数据库术语),MySQL 连接器可以继续正常工作,我们不需要包含额外的逻辑或特定实现。它应该能正常工作。
最大的缺点之一是重新分片操作将变得更加复杂。例如,原始 MySQL 实例的 GTID 在重新分片时会发生变化,而 MySQL 连接器依赖 GTID 才能正常工作。我们还认为,将 MySQL 连接器直接连接到每个底层 MySQL 实例会违背 Vitess 作为新连接器(每次重新分片时需要添加或移除)操作简单性的初衷。更不用说这样的操作会导致 Kafka 代理内部数据重复。
选项 2:使用 JDBC 源连接器
我们还考虑使用JDBC 源连接器。它允许将来自支持 JDBC 驱动程序的任何关系型数据库的数据源接到 Kafka。因此,它与 Vitess VTGate 兼容。它也有其优点和缺点。
优点
-
它与 VTGate 兼容。
-
它能更好地处理 Vitess 重新分片操作。在重新分片操作期间,读取操作会被(VTGate)自动重定向到目标分片。它不会产生任何重复或丢失数据。
缺点
-
它是基于轮询的,这意味着连接器会按照定义的间隔(通常是几秒钟)轮询数据库以获取新更改事件。这意味着与 Debezium MySQL 连接器相比,我们的延迟会高得多。
-
它的偏移量由表的增量主键或表的某个时间戳列管理。如果我们使用时间戳列作为偏移量,我们将不得不为每个表创建时间戳列的二级索引。这增加了我们后端服务的约束。如果我们使用增量主键,我们将错过行更新的更改事件,因为主键根本没有更新。
-
JDBC 连接器创建的主题名称不包含表的模式名称。使用
topic.prefix连接器配置意味着我们每个模式有一个连接器。在 Bolt,我们有大量的模式,这意味着我们需要创建大量的 JDBC 源连接器。 -
在 Bolt,我们的下游应用程序已经设置为使用 Debezium 的数据格式和主题命名约定,例如,我们需要将下游应用程序的解码逻辑更改为新的数据格式。
-
行删除未捕获。
选项 3:使用 VStream gRPC
VTGate 公开了一个名为 VStream 的 gRPC 服务。它是一个服务器端流式服务。任何 gRPC 客户端都可以订阅VStream服务,以获取底层 MySQL 实例的连续更改事件流。VStream 发出的更改事件包含与底层 MySQL 实例的 MySQL 二进制日志相似的信息。单个 VStream 甚至可以订阅给定键空间内的多个分片,这使得它成为构建 CDC 工具的一个非常方便的 API。
在后台,如图 2 所示,VStream 从多个VTTablet读取更改事件,每个分片一个 VTTablet。因此,它不会从给定分片的多个 VTTablet 发送重复项。每个 VTTablet 都是其 MySQL 实例的代理。典型的拓扑将包括一个主 VTTablet 及其相应的 MySQL 实例,以及多个副本 VTTablet,每个副本 VTTablet 都是其自己的副本 MySQL 实例的代理。VTTablet 从其底层 MySQL 实例获取更改事件,并将更改事件发送回 VTGate,VTGate 再将更改事件发送回 VStream 的 gRPC 客户端。
订阅 VStream 服务时,客户端可以指定 VGTID 和表类型(例如,MASTER,REPLICA)。VGTID 指定了 VStream 开始发送更改事件的位置。本质上,VGTID 包含(键空间、分片、分片 GTID)元组的列表。表类型指定了我们要从中读取更改事件的每个分片中的 MySQL 实例(主节点或副本)。
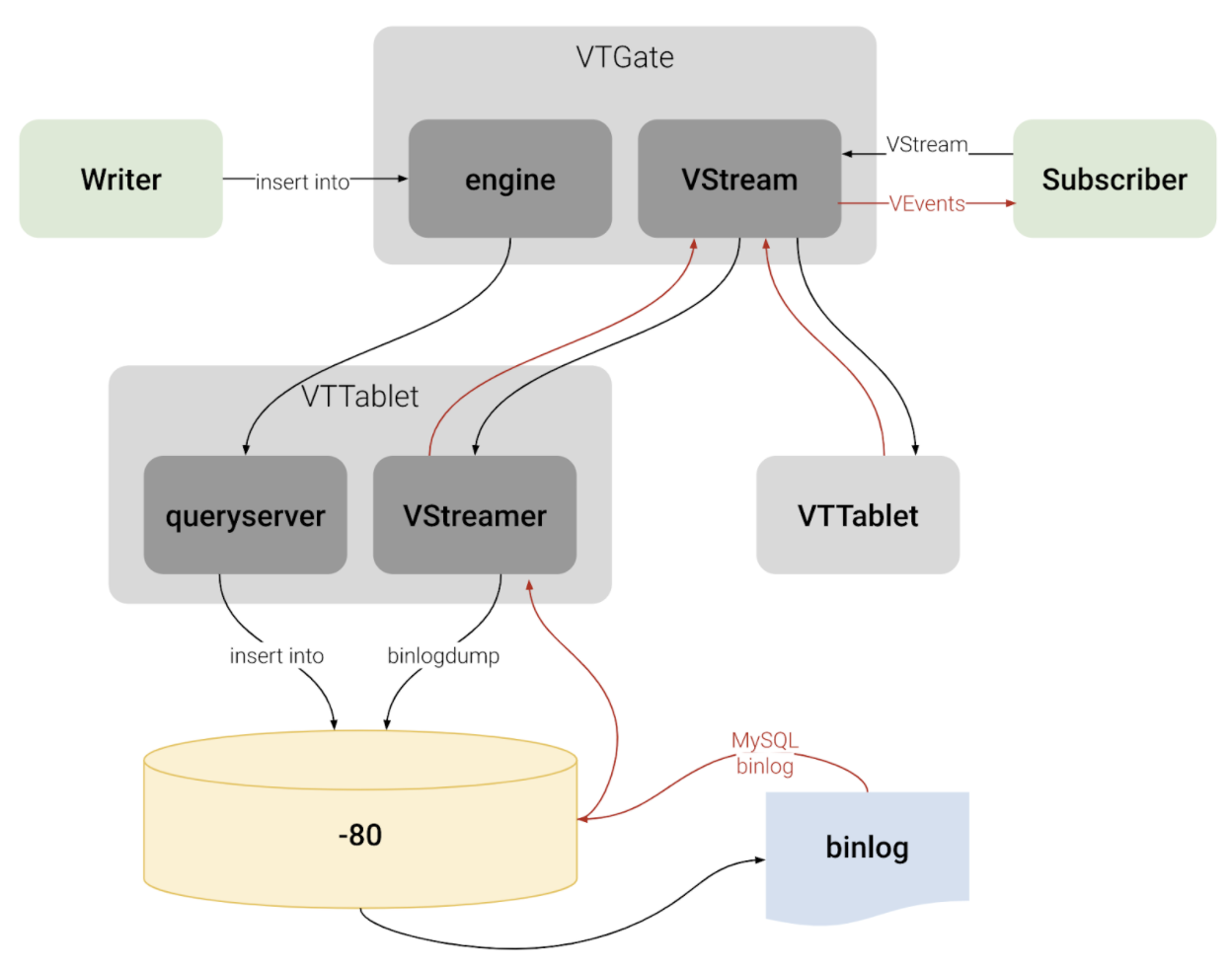
图 2. VStream 架构。参考:https://vitess.io/docs/concepts/vstream
使用 VStream gRPC 的一些优点是:
-
它是从 Vitess 接收更改事件的一种简单方式。Vitess 的文档也推荐使用 VStream 来构建下游的 CDC 进程。
-
VTGate 隐藏了连接到各种源 MySQL 实例的复杂性。
-
由于更改事件一旦发生就会流式传输到客户端,因此延迟很低。
-
更改事件不仅包含插入和更新,还包含删除。
-
可能是最大的优点之一是更改事件包含每个表的模式。因此,您不必担心提前获取每个表的模式(例如,通过解析 DDL 或查询表的定义)。
-
更改事件包含 VGTID,CDC 进程可以存储它并将其用作下次重新启动 CDC 进程的偏移量。
也有一些缺点:
-
虽然它包含表模式,但仍然缺少一些重要信息。例如,
Enum和Set列类型尚不提供所有允许的值。不过,这应该在下一个主要版本(Vitess 9)中修复。 -
由于 VStream 是一个 gRPC 服务,我们无法直接使用 Debezium MySQL 连接器。但是,用其他语言实现 gRPC 客户端相当简单。
总而言之,我们决定使用 VStream gRPC 来捕获 Vitess 的更改事件,并基于 Debezium 的所有最佳实践来实现我们的 Vitess 连接器。
Vitess 连接器深度解析和开源
在实现了 Vitess 连接器并深入研究 Vitess 的实现细节后,我们开始查看各种 Debezium 源连接器(MySQL、Postgres、SQLServer)的实现细节,借鉴一些想法。几乎所有这些连接器都是使用通用的连接器开发框架实现的。因此,很明显我们应该在其之上开发 Vitess 连接器。鉴于我们是 MySQL 连接器非常活跃的用户,并且我们受益于其开源,这使我们能够为其贡献我们自己缺少的功能。因此,我们决定将 Vitess 源连接器的代码库作为 Debezium 的一部分开源。请随时在此处了解更多信息:Debezium Vitess 连接器。我们欢迎并重视任何贡献。
总体而言,您可以在下图中看到,连接器实例在 Kafka Connect 工作器中创建。在撰写本文时,您有两个选项来配置连接器以从 Vitess 读取:
选项 1(推荐)
如图 3 所示,每个连接器捕获特定键空间内所有分片的更改事件。如果键空间未分片,连接器仍然可以从键空间中的唯一分片捕获更改事件。当连接器首次启动时,它会读取键空间中所有分片的当前 VGTID 位置。因为它订阅了所有分片,所以它会连续捕获所有分片的更改事件并将其发送到 Kafka。它会自动支持 Vitess 重新分片操作,不会丢失数据,也不会产生重复数据。
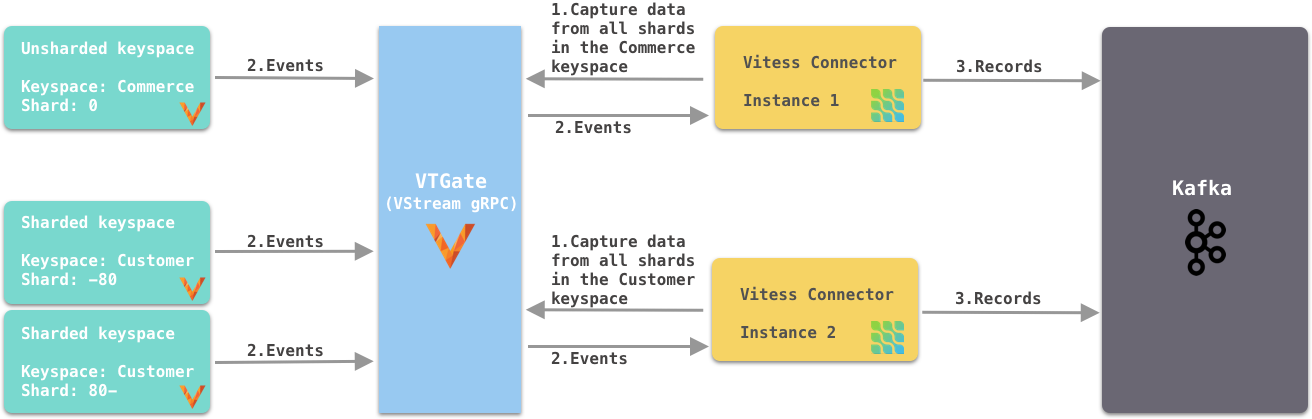
图 3. 每个连接器订阅特定键空间的所有分片
选项 2
如图 4 所示,每个连接器实例捕获特定键空间/分片对的更改事件。连接器实例通过 VTCtld gRPC(这是另一个 Vitess 组件)获取键空间/分片对的初始(当前)VGTID 位置。每个连接器实例独立使用其获取的 VGTID 来订阅 VStream gRPC,并连续从 VStream 捕获更改事件并将其发送到 Kafka。要支持 Vitess 重新分片操作,您需要更多的手动操作。
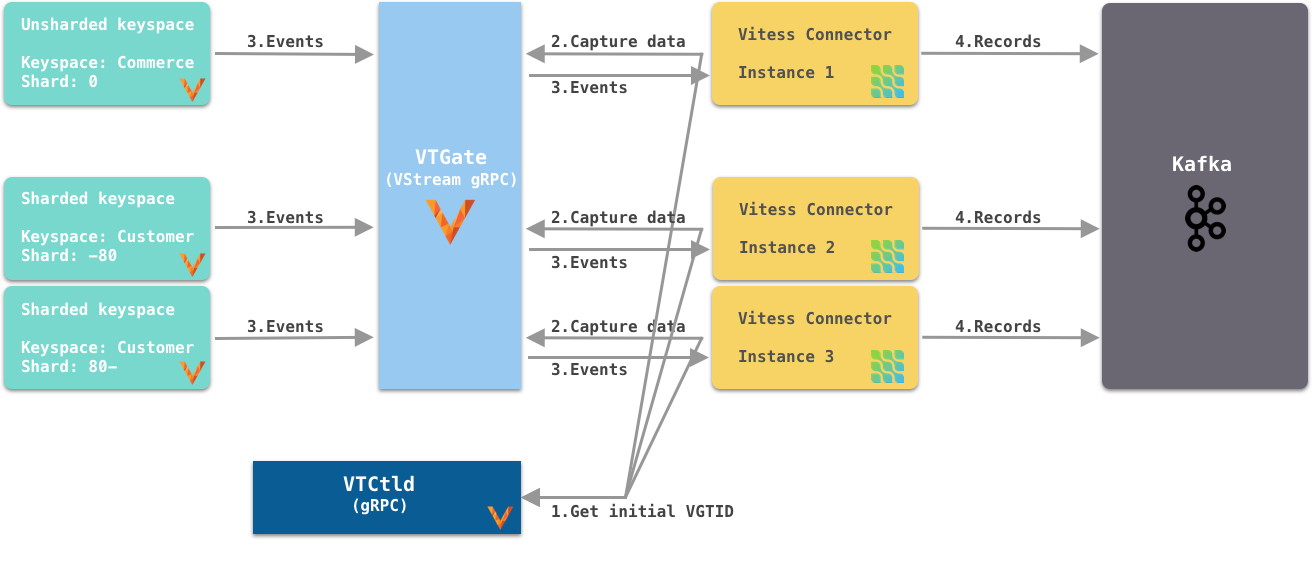
图 4. 每个连接器订阅特定键空间的一个分片
在内部,每个连接器任务使用一个 gRPC 线程来不断从 VStream 接收更改事件,并将事件放入内部阻塞队列。连接器任务线程从队列中轮询事件并将其发送到 Kafka,如图 5 所示。
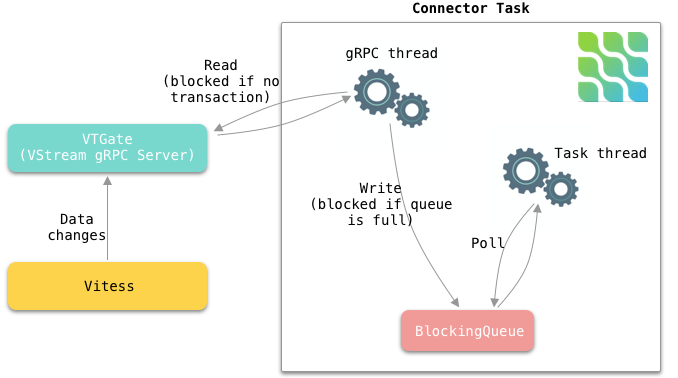
图 5. 每个连接器任务的内部工作方式
复制挑战
在实现 Vitess 连接器并深入研究 Vitess 的过程中,我们还认识到了一些挑战。
Vitess 重新分片
当配置连接器订阅给定键空间的所有分片时,Vitess 连接器支持 Vitess 重新分片操作。VStream 发送一个包含所有分片的分片 GTID 的 VGTID。Vitess 重新分片对用户是透明的。一旦完成,Vitess 将发送新分片的 VGTID。因此,连接器将在重新分片后使用新的 VGTID。但是,您需要确保连接器在重新分片操作发生时正在运行。尤其请检查连接器的偏移量主题是否具有新的 VGTID,然后再删除旧的分片。这是因为如果旧的分片被删除,VStream 将无法识别旧分片中的 VGTID。
如果您选择每个连接器订阅一个分片,则连接器不提供对 Vitess 重新分片的开箱即用支持。一种支持重新分片的手动变通方法是为每个目标分片创建新的连接器。例如,为 commerce/-80 分片创建一个新连接器,为 commerce/80- 分片创建另一个新连接器。请注意,由于它们是新连接器,默认情况下会创建新主题,但是,您可以使用Debezium 逻辑主题路由将记录路由到相同的主题。
偏移量管理
VStream 在其响应中包含 VGTID 事件。我们将 VGTID 作为偏移量保存在 Kafka 偏移量主题中,因此当连接器重新启动时,我们可以从保存的 VGTID 开始。但是,在极少数情况下,当一个事务包含大量行时,VStream 会将更改事件分批处理到多个响应中,只有最后一个响应包含 VGTID。在这种情况下,我们没有收到每个更改事件的 VGTID。我们有几种选择来解决这个问题:
-
我们可以将所有更改事件缓冲在内存中,等待包含 VGTID 的最后一个响应到达。这样,所有事件都将关联正确的 VGTID。一些缺点是,在事件发送到 Kafka 之前,我们的延迟会更高。此外,由于缓冲,内存使用量可能会大大增加。缓冲也增加了逻辑的复杂性。我们也无法控制 VStream 发送给我们的事件数量。
-
我们可以使用我们拥有的最新 VGTID,即来自上一个 VStream 响应的 VGTID。如果连接器在处理如此大的事务时失败并重新启动,它将从上一个 VStream 响应的 VGTID 开始,从而重新处理一些事件。因此,它具有至少一次事件传递语义,并且期望下游是幂等的。由于大多数事务不够大,大多数 VStream 响应将在响应中包含 VGTID,因此出现重复的可能性很低。最终,我们选择这种方法是因为它具有至少一次的传递保证和简洁的设计。
模式管理
VStream 的响应还包含一个 FIELD 事件。这是一个特殊事件,包含受影响行的表的模式。例如,假设我们有 2 个表,A 和 B。如果我们向表 A 插入几行,FIELD 事件将仅包含表 A 的模式。VStream 足够智能,仅在必要时包含 FIELD 事件。例如,当 VStream 客户端重新连接时,或当表的模式发生更改时。
旧版本的 VStream 只包含列类型(例如,Integer,Varchar),不包含其他信息,例如列是否是主键,列是否有默认值,Decimal 类型的精度和小数位数,Enum 类型的允许值等。
新版本(Vitess 8)的 VStream 开始包含更多关于每列的信息。这将帮助连接器更准确地反序列化某些类型,并在发送到 Kafka 的更改事件中具有更精确的模式。
未来的开发工作
-
我们可以使用 VStream 的 API 从最新的 VGTID 位置开始流式传输,而不是从 VTCtld gRPC 获取初始 VGTID 位置。这样做将消除对 VTCtld 的依赖。
-
我们尚不支持自动从更改事件中提取主键。目前,默认情况下,发送到 Kafka 的所有更改事件的键都为
null,除非指定了message.key.columns连接器配置。Vitess 最近在 VStream FIELD 事件中为每列添加了标志,这使我们能够很快实现此功能。 -
添加对初始快照的支持,以便在流式传输更改之前捕获所有现有数据。
总结
Bolt 的大部分后端服务都由 MySQL 提供支持。由于数据量和操作复杂性的显著增长,Bolt 开始评估 Vitess,以利用其可扩展性和内置功能,如重新分片。
为了捕获 Vitess 的数据更改,正如我们使用 Debezium MySQL 连接器所做的那样,我们考虑了几种选择。最终,我们基于通用的 Debezium 连接器框架实现了自己的 Vitess 连接器。在实现 Vitess 连接器的过程中,我们遇到了一些挑战。例如,对 Vitess 重新分片操作的支持、偏移量管理和模式管理。我们对解决这些挑战的方法进行了推理,并得出了解决方案。
我们还从多个社区收到了对该项目的极大兴趣,并决定在 Debezium 的支持下开源Vitess 连接器。请随时了解更多信息,我们欢迎并重视任何贡献。


关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。