
欢迎阅读第一期“Debezium 社区故事”,这是一个新的系列,采访 Debezium 和变更数据捕获社区的成员,如用户、贡献者或集成商。我们计划以宽松的节奏发布更多本系列的文章,如果您想参与其中,请告诉我们。在今天的访谈中,我很高兴能与 Renato Mefi 对话,他是一位长期的 Debezium 用户和贡献者。

Renato,你能介绍一下你自己吗?如果你不为 Debezium 做贡献,你的工作是什么?
大家好,我是 Renato。我第一次提交 Debezium 代码是在 2018 年 11 月 12 日,至今已有很长一段美好的时光,我很高兴有机会在这里与大家分享我的故事!
我是荷兰阿姆斯特丹 SurveyMonkey 的一名首席软件工程师,在 CX(客户体验)套件的平台团队工作。如果你对 CX 套件感到好奇,可以 在这里查看。
在互联网上,你会发现我谈论 Docker、Debezium、Kafka、微服务以及其他我喜欢的东西。尽管那些出色的工程技术让我非常兴奋,但此刻我同样对平台工程团队以及它们如何在组织中运作充满热情。下面我要讲述的故事代表了我对这一点的看法,即在采用新技术和为整体解决难题时,平台团队的作用有多么关键,在这种情况下,它由 Debezium 提供支持!
在您目前的项目中,您使用 Debezium 和 CDC 的用例是什么?
这是一个漫长而愉快的 E故事(就互联网而言,算是长的),我们从 2018 年第四季度开始使用 Debezium,在撰写这些答案时,已经使用了两年时间。
当我将 Debezium 归类到我们的产品中时,我说它是一个架构组件,这样做的目的是将其定位为平台/基础设施的考量,使其能够触及堆栈和服务的多个部分。我认为 Debezium 的这种抽象是它在我们的平台中获得采用和增长的关键成功因素之一,我来更好地解释一下!
我们的第一个用例很可能是 CDC 最常见的用例之一,即 绞杀者模式,而它在我们引入 Debezium 之前就已经存在了;所以让我先讲这个故事:当我加入 Usabilla(后来被 SurveyMoney 收购)时,我们已经有一个将平台迁移到新架构的努力,并且绞杀者模式已经存在。当最初的几个服务开始增长时,它们将数据从旧系统导出的主要方式是轮询数据库,无需多言,这可能会非常糟糕!我们的旧数据库是一个 MongoDB 集群,由于我当时对轮询方法感到担忧,所以我开始研究各种可能性。我希望找到类似流式 API 的东西,但最终我遇到了数据库变更日志(写前日志,在 Mongo 中称为“oplog”!
我立刻想到:“哦,我可以写一个查询 oplog 中数据的程序,然后将其发送到 Kafka”。所以我咨询了我们内部的高级 SRE 和 MongoDB 专家 Gijs Kunze,他认为这可能是一个好主意;下一步,我去找我的同事 Rafael Dohms 谈了谈,我们决定进行一些额外的搜索,就这样,我们找到了 Debezium!它完美地满足了我们的需求,而且比我们自己写的任何东西都要好!
现在回到我们的用例,它之所以成为我们的一个架构组件,基本上是因为这种方法,我们将其抽象并封装在一个名为 Legacy Data Syncer (LDS) 的项目中(对我们来说是 LDS,因为缩写永远不会过时)。虽然启动一个带有 Debezium 的 Kafka Connect 看起来很简单,但要使其生产就绪、监控数据库中的多个集合、暴露指标、进行转换等等,并非易事。那么它是如何工作的呢?每次工程团队需要从我们的旧系统捕获数据,以便开始对某个功能进行绞杀时,他们只需要做两件事:打开一个 pull request,这实际上是在 LDS 中添加了一行,然后创建他们的 Kafka 消费者!
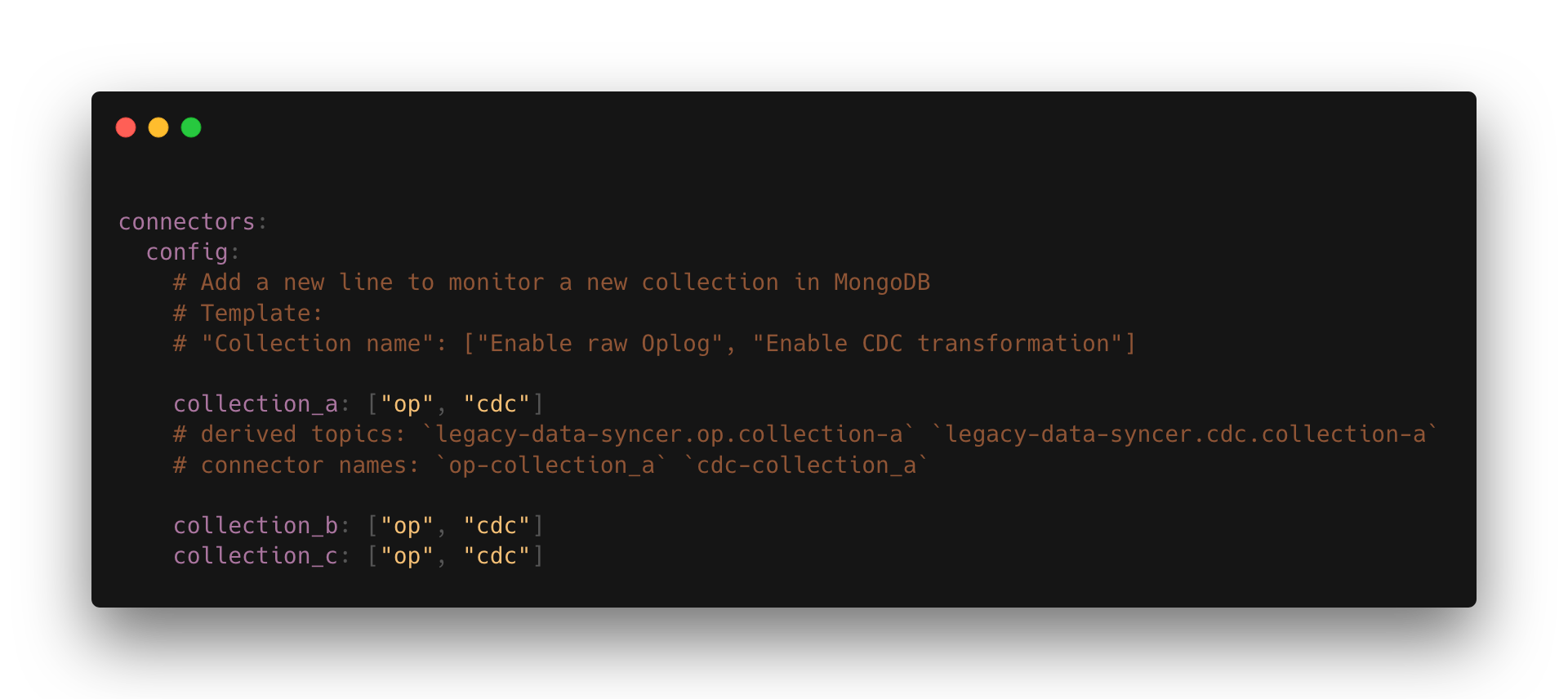
图 1. LDS 中的配置文件;开发人员将打开一个 PR 添加新行,其余的将得到处理。
合并 PR 后,我们的项目将为 Kafka Connect 提供完整的配置,确保执行快照,存在指标等等;我们对 Outbox 模式也做了同样的事情,并且我在这个 推文串 中对此进行了一些更详细的讨论。
为团队提供自助服务是消除采用阻力的绝佳方式,无需 Jira 票证,无需高级运维知识或任何其他东西即可运行。我还认为对 Debezium 在我们平台上的成功做出贡献的其他因素是它的可靠性和直观的价值感知,在这两年里,我们从未发生过重大故障或任何类型的关键问题!
您提到了 Outbox 模式;您能多谈谈为什么以及如何使用它吗?
当然!再说一遍,CDC 和 Debezium 能够简化大型平台一些最关键的架构部分,这真是太神奇了!在使用 Debezium 进行核心架构迁移一年后,我们又面临一个问题:如何在可靠地将数据写入我们的新真相源数据库的同时,将消息传播到 Kafka。虽然答案和解决方案看似简单,但每一种都带有主要的缺点。
我们有什么解决方案?
-
通过采用事件溯源,将最终一致性发挥到极致,先写入 Kafka,然后读取我们自己的写入;这里的缺点是增加了复杂性和加剧了最终一致性。
-
双重写入,嗯,实际上这不是一个选项,因为如您所知,“朋友不会让朋友进行双重写入”!
-
各种分布式事务方法,如 2PC 和 Saga;这里的成本是性能和工程投入,现在我们拥有的每个服务都必须要么成为事务协调器,要么具备回滚能力,级联效应也让我们相当头疼!
那么,还剩下什么?我们发现 Outbox 是适合我们的答案,但在我们深入探讨之前,让我先来谈谈我们决策过程中的成本效益分析!
尽管一些技术选项很有吸引力,例如事件溯源,但工程投入和增长是巨大的。此外,它不是即插即用的东西,而且在此过程中有大量的探索要做,那么约束和期望是什么?
-
可靠性;我们希望至少一次语义,精确一次不是必需的,因为我们可以唯一地标识每条消息/事件;
-
仅在服务之间最终一致,但在服务内部不一致。能够与某个模型真相源的服务进行交互,并立即获得答案,这不仅方便,而且功能强大(这也是单体架构如此吸引人的原因);
-
尽可能避免分布式事务,这很可怕,我们也应该感到可怕!
-
可管理的工程量;我们如何“轻松地”让 30 多名工程师采用一个解决方案来解决这个问题?同时,您如何确保每个服务和团队都能保证实施?
我们意识到 Outbox 模式将帮助我们满足这些要求:应用程序将通过 Outbox 表发布事件,该表在数据库中的业务事务中被写入。
与绞杀者模式一样,我们希望诉诸于架构组件,让团队可以自助服务。起初,我们正在探索一个自研解决方案,该解决方案可以查找每个服务中的 Outbox 表并发布消息。这种方法的缺点是轮询数据库的问题,尽管在这种情况下危害较小,因为我们不需要查找更新或删除。
幸运的是,那时我密切关注 Debezium 的工作,我阅读了关于使用 Outbox 模式实现微服务之间可靠数据交换的博客文章,那里就有我的答案!好吧,我的意思是,答案的一部分,我们仍然需要实现它,而这是一个留给下一个问题的故事!
快进几个月,我们就有了一种可靠的方式来交换服务之间的消息,并具备了我们想要的所有保证,通过应用一些平台 DevOps 的风格,我们也使其实现自助服务,并且易于集成到每个服务中!
用户可以指定他们的服务位于哪个数据库,表名是什么,以及哪个列用作事件路由器,您可以在官方 Debezium Outbox 事件路由器文档中找到更多细节。
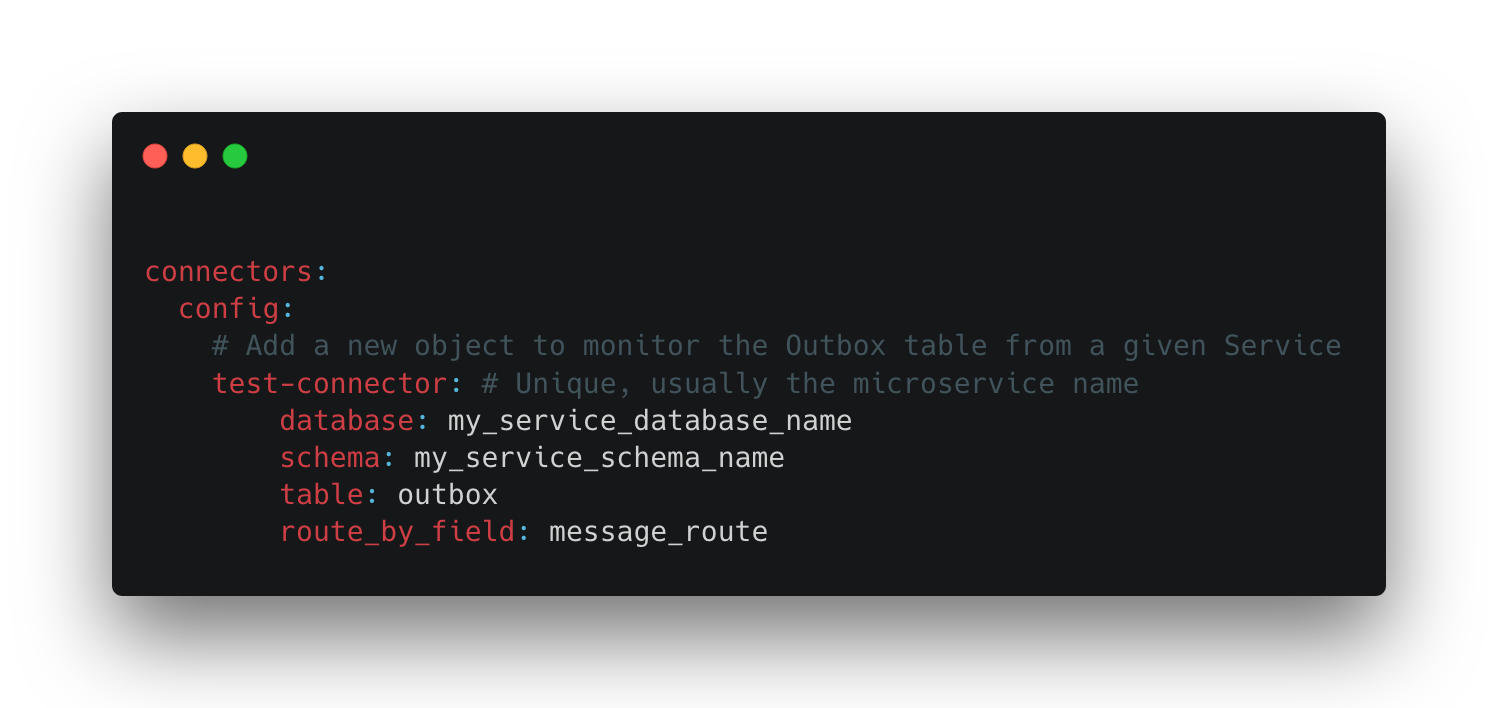
图 2. 配置 Outbox 连接器的配置文件
您不仅在使用 Debezium,还为该项目做出了贡献。您的经历如何?您是否也在做其他开源工作?
正如我开头透露的那样,我使用 Debezium 和贡献 Debezium 是齐头并进的。在我们 SurveyMonkey 的两个 Debezium 用例中,我都获得了为 Debezium 和 Kafka(仅是一个 bug 修复,但我为此感到高兴!)做出贡献的好机会。
起初,我一直在修复 Debezium MongoDB 连接器中的 bug;随着我们将其广泛推广到所有团队,开始出现许多边缘情况,尤其是在将原始数据库事务日志转换为易于阅读的 Kafka Connect struct 的转换过程中。此外,由于我们的架构选择,我们将原始日志和转换后的数据分为两个不同的步骤,它们进入不同的主题,并配置为单独的 Kafka Connect 连接器。
快速插播:这个决定的理由是为了能够应对转换错误;MongoDB 有一个复制窗口,如果您丢失了它,意味着您将不得不对集合进行新的完整快照,并且在此过程中可能会丢失删除事件。因此,我们选择了一种更安全的方法,即将转换逻辑与原始日志分开:我们称之为 `op`(代表 operation)的步骤,是 Debezium MongoDB 源连接器,它将原始数据输出到主题,没有任何更改或转换,最大限度地减少了过程中的错误几率。第二步称为 `cdc`,是一个 Salesforce Mirus 源连接器,它读取 `op` 输出主题,使用 Debezium 文档展平 SMT 转换消息,并输出到最终主题,供服务消费。通过这种方法,我们现在拥有两个主要能力:能够抵抗上述的本地/自定义转换过程中的错误和崩溃,并且我们有机会根据需要更改转换,而无需重新读取数据库,这为我们提供了更大的灵活性。这还为 Debezium 本身增加了一些额外的特性和挑战!随着我不断贡献,我注意到了一些可以改进的地方并开始修复它们,包括几乎完全重构 Debezium 容器镜像的构建过程、其脚本以及其他较小的方面!
让我们回到 Outbox 模式;当这篇博文出现在 Debezium 博客上时,它主要是一个想法和概念验证。但我们真的希望它能在生产环境中运行,那么为什么不与其合作呢?
我想借此机会提到 Debezium 社区在帮助我开始贡献方面是多么有用。当我表达参与的意愿时,他们非常受欢迎,我们进行了电话会议,所以我很快就觉得在代码库中工作很有成效。
与他们交流后几乎立即,我开始了一个技术草稿(您可以在 这里查看),不久之后,就完成了第一个实现。我可以几乎肯定地说,我们是第一个运行由 Debezium 支持的事务性 Outbox 模式的人。我当时在我们的平台上运行了一个自定义构建,该构建最终成为了您今天在 Debezium 文档中看到的官方 Outbox 事件路由器。我很幸运能够在正确的时间与正确的人在一起,所以再次感谢 Debezium 团队在我起草和实现整个过程中给予的帮助!
我还会做更多的开源吗?是的,但我必须说,我的大部分开源活动都是“自私的”,我正在开发解决方案来解决我在工作中遇到的问题,但我乐于迈出额外一步,将其贡献给 OSS 世界,但这也会是季节性的。这样做的优点之一是,如果我为某个项目做某事,可以肯定的是,它将投入生产,并且很可能能发现更多棘手的问题!
您是否觉得 Debezium 缺少什么,或者您希望在未来看到哪些改进?
当我想到 Kafka 和 Debezium 生态系统时,我认为重要的下一步是那些能使其更易于访问的方面。尽管网上有很多内容和示例,但在阅读这些内容和实现生产就绪的实现之间仍然存在巨大的差距。
我的意思是,抽象出各个部分,赋予它们更多的意义。Outbox 模式就是一个很好的例子,人们并不自然地会想到 CDC,并且知道它与 Outbox 如此匹配,这个生态系统中还有很多用例有待探索。
如果您能获得开箱即用的所有功能,那会怎么样?您最喜欢的框架中的 Outbox 实现,它知道如何与 ORM 集成,处理事务部分,然后,如何塑造消息和事件?如何采用其 Schema 以及 Schema 的演进是什么样的。之后,接近消费者实现,我如何幂等地处理消息,尊重语义,进行重试,并在需要时将其投影到数据库。已经有一些这样的举措,例如 Quarkus Outbox 扩展,它负责框架和数据库集成。对我来说,未来包含这些东西,适用于多种框架和技术栈,甚至更广泛地帮助您设计良好的事件(也许由 AsyncAPI 提供支持),让每个人都能获得一个好的开端!
在不断发展的架构中,这些都是非常复杂的事情,模式将不断重复,希望社区能够就设计和实现达成共识,这正是我认为下一步要做的事情,一个好的架构的复杂性不再存在于连接线和插头中,使其更容易访问!
奖励问题:软件工程领域的下一个重大趋势是什么?
我认为我在之前的回答中已经为这个问题提供了一些线索!
对我来说,下一个重大趋势是一种方法论;我经常说 DevOps 的演进是自助服务,它可以发生在堆栈的许多层面上。我举的关于我们 Debezium 实现的例子,我称之为平台/运维和产品开发团队之间的自助服务,但它可以应用于许多,许多地方!
这个想法是促进复杂结构的实现,更加端到端,处理指标、警报和各种其他保证语义的最佳实践。我们可以看到存在朝着这一方向的融合,例如 Kubernetes Operator 是一个很好的例子,您可以在其中抽象一个用例,该用例将被转化为基础架构中的许多(如果不是几十个)内部资源。
我相信我们已经拥有了实现这一目标的基础技术,所有的 IaC、容器、框架、可观测性系统都已具备,我们只需要赋予它们意义!
在哪里有这样一个框架,我可以:处理用户请求,进行验证,写入真相源,将消息发布到我的代理,在另一个端点消费,在那里我唯一关心的是载荷本身?所有语义都应该得到处理,包括幂等性、重试、序列化/反序列化问题、死信队列、最终一致性缓解、指标、警报、SLO、SLA 等等!
而这正是我每天在工作中投入精力的地方,让所有工程团队都能以一种更愉快、更安全的方式开发他们的软件,这也概括了我对平台工程的热情!
Renato,非常感谢您抽出宝贵时间,很高兴您能来这里!
如果您想与 Renato Mefi 保持联系并与他讨论,请在下方留言或关注并联系他 在 Twitter 上。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。