
我们为与 Db2 的使用开发了一个 Debezium 连接器,该连接器现已作为 Debezium 孵化器的一部分可用。在这里,我们描述了变更数据捕获 (CDC) 的用例、Db2 生态系统中已有的各种方法,以及我们如何转向 Debezium。此外,我们还论证了我们实现 Db2 Debezium 连接器所采取的方法。
背景:将数据引入数据湖
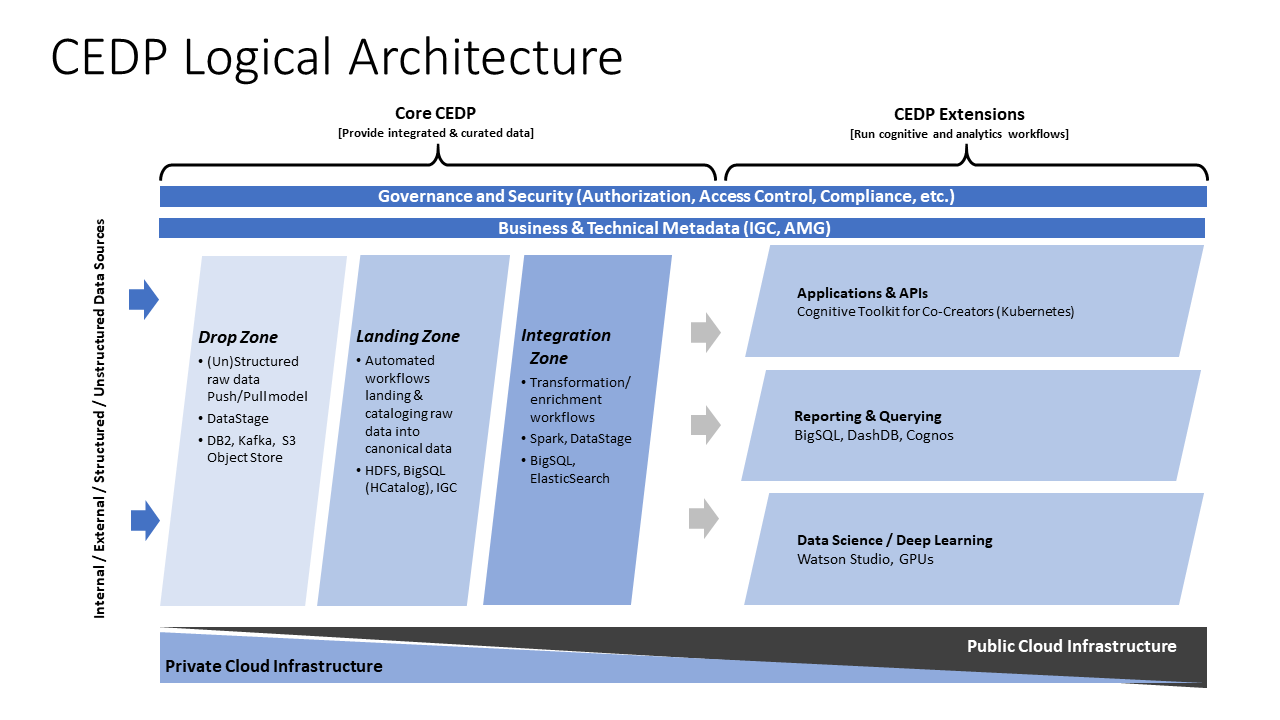
高效地从Db2获取数据
数据被摄取到一个不可变的数据湖的登陆区(Landing Zone)。这个登陆区实现为一个HDFS实例。流式数据(例如新闻)使用Kafka从源端移动,然后使用适当的连接器写入HDFS。
我们的一个关键设计目标是自动化。每天需要摄取来自200多个不同来源的5000多张关系数据库表。为了扩展数据处理平台(除了允许数据所有者将数据带入平台的数据治理流程之外),摄取本身必须是自助服务的。
最初,关系数据总是使用Sqoop从源端批量加载。提供一个REST接口,以便数据所有者可以配置数据何时移动,例如,定期触发、事件触发等。Sqoop摄取是一组分布式任务,每个任务使用JDBC连接读取关系数据库表的一部分,生成数据的基于文件的表示(例如,Parquet),然后将其存储在HDFS上。使用Sqoop,我们可以完全刷新数据,或者追加数据。但是,我们**无法**以增量方式修改数据。
从实际角度来看,这限制了数据更新的周期。一些较大的表代表数十GB的压缩Parquet数据。虽然Sqoop允许对同一表并行运行许多任务,但瓶颈通常是WAN上的网络和/或源数据库系统本身的速率控制。通常,任何特定一天只有一小部分表被修改,这意味着会不必要地传输大量数据。
为了解决这些问题,我们引入了变更数据捕获(CDC)来传输WAN上的数据。将数据以CDC模式摄取到专为永不变动的文件设计的存储系统中存在问题。虽然像Deltalakes或Hive 3.0这样的近期工作已开始将增量变更引入Hadoop生态系统,但这些对于我们的需求来说还不够成熟。
作为替代方案,我们使用了“关系数据库暂存区”(Relational Database Drop Zone)的概念,数据所有者可以在其中实例化其数据库的副本,然后我们从中摄取到HDFS。由于暂存区和登陆区位于同一数据中心,并且数据摄取任务是高度可并行的,因此实际摄取大型表通常比从源端传输数据快几个数量级。
数据所有者可以使用他们喜欢的任何工具将数据移动到他们的暂存区。特别是,他们可以传输通过CDC获得的**数据变更**。
CDC系统几乎与关系数据库本身一样古老。通常,这些系统是为了备份或故障恢复而设计的,并供数据库管理员使用。
Db2拥有悠久的历史,已有40多年的历史,并运行在包括zOS、AIX、Linux和Windows在内的广泛操作系统上。它已经发展出一套复杂的CDC工具,用于在不同场景中使用。我们开始探索使用IBM的SQL Replication。一旦管理员将表设置为CDC模式,就会启动一个捕获代理,该代理从事务日志读取对这些表的更改。这些更改存储在专用的CDC表中。在远程数据库上,应用代理会定期从这些CDC表中读取更改并更新影子表。
虽然概念上很简单,但由于以下原因,在实践中难以自动化:
-
源端和目标端紧密耦合,因此同一表不能轻易地复制到多个不同的目标数据库系统。
-
如果源系统已在为表使用复制(例如,用于备份目的),则不能使用此方法复制到数据湖。
-
源端需要提升的特权。数据所有者为Sqoop授予了对其系统的读取访问权限,但授予管理员权限会带来合规性问题。
-
目标端需要提升的特权。为了简单起见,我们的暂存区是单个Db2系统,每个数据源都有数据库实例。允许数据所有者设置SQL复制到暂存区将使他们能够访问彼此的实例,这违反了合规性。
-
这些工具是为系统管理员设计的,因此对于不熟悉的人来说,存在大量的陷阱。例如,必须小心选择各种参数,例如:事务日志必须处于允许CDC的模式,最后一次备份的时间,数据库是行导向还是列导向等等。
-
这是一个特定于Db2的解决方案;尽管大多数关系数据源是Db2,但我们也有Netezza、MySQL和SQL Server的数据源。
我们在实践中发现,上述因素的组合使得允许数据所有者使用IBM SQL Replication作为数据湖的CDC机制变得不切实际。
IBM提供了另一套数据复制工具,称为IBM InfoSphere Data Replication(IIDR)。它作为一种独立于Db2的产品出售。IIDR不是特定于Db2的解决方案,适用于广泛的关系数据库以及非关系数据存储系统(例如文件系统)。本质上,IIDR具有源代理和目标代理。源代理和目标代理在目标系统处或附近运行。源代理读取更改,并通过各种协议(包括TCP套接字、MQ、共享文件等)将更改传播到目标代理。源代理和目标代理通过称为访问服务器(Access Server)的实体进行配置,通过该服务器连接源和目标,并指定要捕获的表。访问服务器本身通常由系统管理员通过图形用户界面进行控制。
因此,例如,我们可以有一个Db2源代理和一个IIDR Kafka目标代理,它表现得像一个标准的Apache Kafka Connect源连接器,即它将更改事件写入Kafka主题。初始记录是Upsert消息(REFRESH阶段),后续更改则作为Upsert/Delete消息序列(MIRROR阶段)传播。
IIDR使得系统更加松耦合,并且不那么特定于Db2。然而,它仍然不容易自动化。本质上,我们需要能够通过REST调用让数据所有者指定源数据库系统和要复制的表,并在我们的Kubernetes集群上自动配置和部署必要的代理和访问服务器。由于我们不能直接在源系统上运行,因此我们对远程Db2系统进行目录化,使其看起来像是本地的,并在那里运行代理。
IIDR假定代理与关系数据库系统运行在相同的硬件架构上。IIDR代理使用低级Db2 API来读取事务日志。我们的许多源系统运行在AIX/PowerPC上,而代理部署所在的Kubernetes平台运行在Linux/Intel上。这会导致字节序不兼容问题。
此方法有两个限制:
-
IIDR旨在由系统管理员进行监控和管理。尝试通过解析日志的脚本来捕获管理员的操作和响应,并尝试对IIDR中的故障做出反应,只会是脆弱的。只要一切正常运行,系统就会运行良好,但如果出现故障(网络中断、Kubernetes代理故障、LDAP停机等),则几乎不可能自动化适当的响应。
-
虽然尽量减少对源系统的影响是一个值得称赞的目标,但从实际角度来看,在生产系统中独立于源系统运行CDC系统几乎是不可能的。如果系统管理员使用备份重新加载了表的旧版本或彻底更改了表的DDL,CDC系统必须意识到这种情况的发生并采取适当的行动。在更改DDL的情况下,会创建一个新版本的表,因此也必须创建KTable的新版本。
我们在尝试使用上述方法针对真实生产系统进行CDC时,遇到了这些以及更多的问题。我们得出结论,CDC系统和源系统的管理不能独立进行,我们的许多问题源于尝试将IIDR用于非预期用途。
实现Debezium Db2连接器的策略
当Debezium可用时,我们开始评估它是否符合我们的需求。由于它支持广泛的关系数据库系统并且是开源的,我们可以想象数据库管理员会允许它用于生成其数据在下游应用程序中的表示。本质上,Debezium系统将成为数据库源系统的扩展。Debezium不需要生成与数据库表**完全相同**的副本(与IIDR或SQL Replication不同)。通常,下游应用程序用于辅助任务(例如分析),而不是故障转移,这意味着诸如保留精确类型之类的问题不那么紧迫。例如,如果时间戳字段在Elasticsearch中表示为字符串,那也不是世界末日。
我们对Debezium唯一的担忧是它没有Db2的连接器。
出现了两种策略:
-
使用低级Db2 API直接读取事务日志,就像IIDR所做的那样。
-
使用SQL Replication的CDC捕获表,通过SQL读取捕获表。
对代码的调查表明,Microsoft SQL Server的**现有连接器**所使用的模型可以很大程度上重用于Db2。本质上:
-
查询变更的SQL查询是不同的。
-
逻辑序列号(LSN)的结构和性质是不同的。
-
Db2区分数据库系统和数据库,而SQL Server不区分,这一点需要考虑。
除此之外,其他一切都可以重用。因此,我们修改了现有的SQL Server代码库来实现Db2连接器。
未来工作/扩展
基准测试
Db2和SQL Server的连接器都使用轮询模型,即连接器定期查询CDC表以确定自上次轮询以来发生了哪些变化。一个自然的问题是,考虑到轮询本身有成本,"最优"的轮询频率是多少?即,延迟和负载之间的权衡是什么?
我们有兴趣构建一个通用的基准测试框架,以更好地了解延迟、CDC系统的吞吐量和源系统的负载方面的权衡。
Db2通知系统
与其构建一个轮询的Db2连接器,不如创建一个通知系统也是可能的。我们曾考虑过这一点,但认为轮询连接器对于首次实现来说更简单。
构建Db2通知连接器的一种方法是:
-
通过使用操作系统文件系统监视器(Linux或Windows)来识别更改事件。这可以监视Db2数据库的事务日志目录,并在文件被修改或创建时发送事件。
-
通过读取实际的表更改来确定事件的确切性质,使用db2ReadLog API。原则上,此API可以作为服务远程调用。
-
通过SQL连接确定相关的Db2数据结构,例如表DDL。
Debezium事件驱动的Db2连接器将等待通知,然后通过db2ReadLog和SQL读取实际的更改。这将需要监视器代理在本地数据库系统上运行,类似于捕获服务器。
DML vs DDL更改
变更数据捕获(CDC)系统会传播通过数据操纵语言(DML)操作(如INSERT、DELETE等)在源表上进行的修改。它们不会显式处理通过数据定义语言(DDL)操作(如TRUNCATE、ALTER等)对源表进行的更改。Debezium在发生DDL更改时的行为尚不清楚。我们正在研究Debezium对此类更改的模型。
结论
虽然假设新的企业数据系统完全从头开始构建很有吸引力,但在相当长的一段时间内,与现有关系数据库系统进行交互几乎肯定是有必要的。Debezium是一个有前途的框架,用于将现有的企业数据系统连接到数据处理平台(如数据湖)。我们目前在IBM研究院的工作重点是构建混合云数据编排系统,其中Kafka和Debezium是核心组件。



关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。