
业务应用程序通常需要维护某种形式的审计日志,即应用程序数据所有更改的持久化跟踪。如果仔细看,带有 Debezium 数据更改事件的 Kafka 主题与之非常相似:它源自数据库事务日志,描述了应用程序记录的所有更改。所缺少的只是一些元数据:数据为何、何时以及由谁更改?在本博文中,我们将探讨如何通过变更数据捕获 (CDC) 提供和公开这些元数据,以及如何使用流处理来丰富实际的数据更改事件以包含此类元数据。
维护数据审计跟踪的原因有很多:例如,法规要求可能强制企业保留其客户、采购订单、发票或其他数据的完整历史信息。同样,对于企业自身而言,深入了解某些数据更改的原因和方式也非常有用,例如,可以改进业务流程或分析错误。
创建审计跟踪的一种常见方法是使用应用程序端库。通过集成到选定的持久性库中,它们可以维护数据表中的特定列(“createdBy”、“lastUpdated”等),以及/或将早期记录版本复制到某种形式的历史表中。
不过,这也有一些缺点:
-
在 OLTP 事务中写入历史表记录会增加事务中执行的语句数量(每次更新或删除,还必须在相应的历史表中写入一条插入语句),因此可能导致应用程序响应时间变长。
-
在批量更新和删除的情况下(例如 `DELETE from purchaseorders where status = 'SHIPPED'`),通常无法提供审计事件,因为用于将库集成到持久性框架中的侦听器不知道所有受影响的记录。
-
直接在数据库中进行的更改无法跟踪,例如在运行数据加载、在存储过程中进行批量处理或在紧急数据修补期间绕过应用程序时。
另一种技术是数据库触发器。无论操作是由应用程序还是数据库本身发出的,它们都不会遗漏任何操作。它们还能够处理受批量语句影响的每一条记录。缺点是,在 OLTP 事务中执行触发器时,延迟仍然会增加。此外,还需要一个流程来为每张表安装和更新触发器。
基于变更数据捕获的审计日志
当利用事务日志作为审计跟踪的来源,并使用变更数据捕获来检索更改信息并将其发送到消息代理或日志(如 Apache Kafka)时,上述问题就不会存在。
CDC 进程异步运行,可以提取更改数据,而不会影响 OLTP 事务。每当发生数据更改时,事务日志中都会有一条条目,无论是从应用程序发出的还是直接在数据库中执行的。对于批量操作中更新或删除的每条记录,都会有一条日志条目,因此可以生成每条记录的更改事件。此外,对数据模型也没有影响,也就是说,不需要创建特殊的列或历史表。
但是,CDC 如何访问我们最初讨论过的元数据呢?例如,这可以是执行数据更改的应用程序用户、其 IP 地址和设备配置、跟踪的 span ID,或应用程序用例的标识符等数据。
由于这些元数据通常不会(也不应该)存储在应用程序的实际业务表中,因此必须单独提供。一种方法是使用一个单独的表来存储这些元数据。对于每个已执行的事务,业务应用程序都会在该表中生成一条记录,其中包含所有必需的元数据,并使用事务 ID 作为主键。在执行手动数据更改时,也很容易通过额外的插入来提供元数据记录。由于 Debezium 的数据更改事件包含导致特定更改的事务 ID,因此可以关联数据更改事件和元数据记录。
在本文的其余部分,我们将仔细研究业务应用程序如何提供事务范围的元数据,以及如何使用 Kafka Streams API 使用相应的元数据丰富数据更改事件。
解决方案概述
下图显示了总体解决方案设计,以管理蔬菜数据的微服务为例
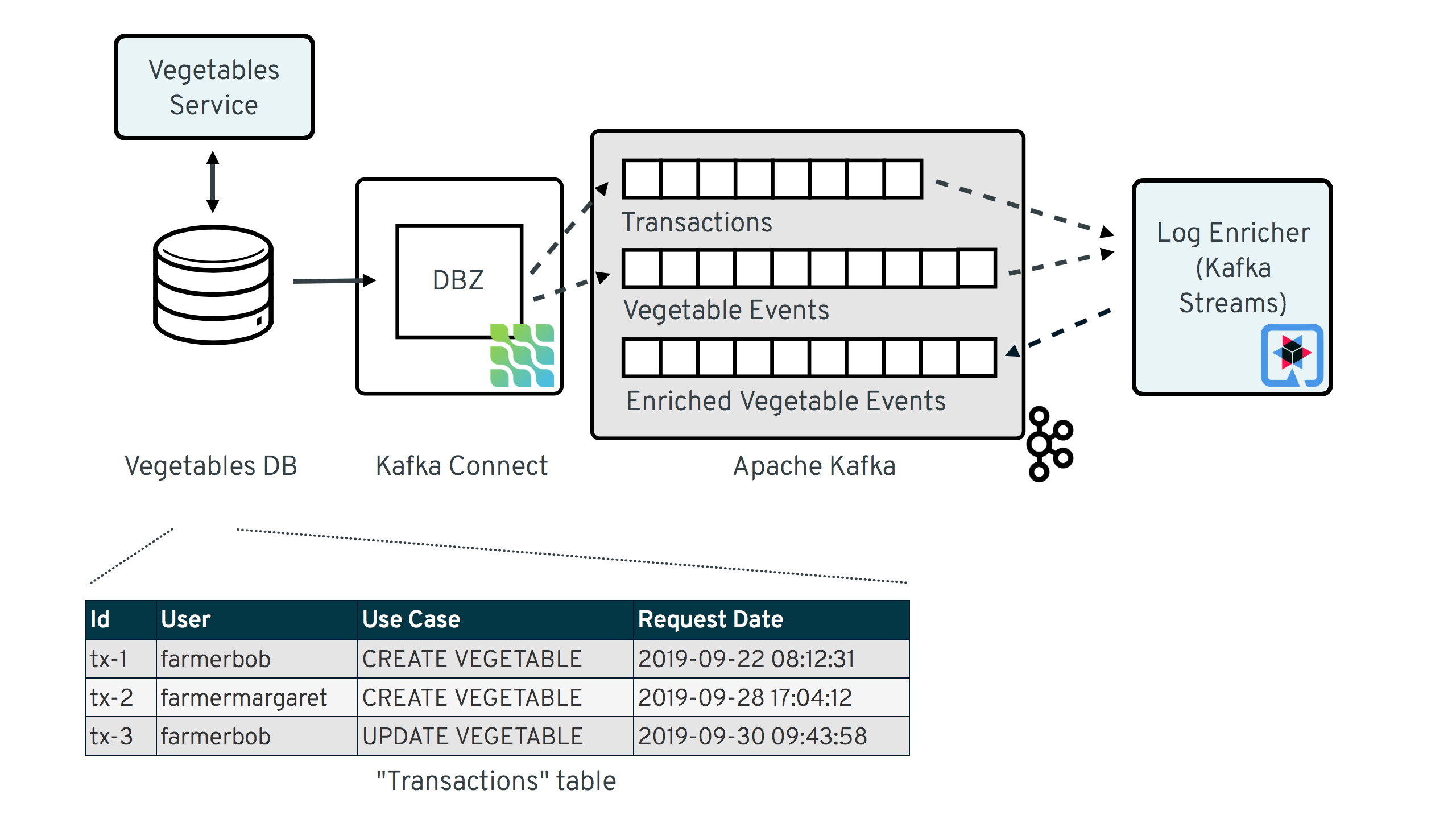
涉及两个服务:
-
vegetables-service:一个简单的 REST 服务,用于将蔬菜数据插入和更新到 Postgres 数据库;在其处理过程中,它不仅会更新其实际的“业务表” `vegetable`,还会将一些审计元数据插入到专用的元数据表 `transaction_context_data` 中;Debezium 用于将两个表中的更改事件流式传输到 Apache Kafka 中的相应主题。
-
log-enricher:一个使用 Kafka Streams 和 Quarkus 构建的流处理应用程序,它将来自包含蔬菜更改事件的 CDC 主题(`dbserver1.inventory.vegetable`)的消息与 `dbserver1.inventory.transaction_context_data` 主题中的相应元数据进行丰富,并将丰富后的蔬菜更改事件写回 Kafka 到 `dbserver1.inventory.vegetable.enriched` 主题。
您可以在 GitHub 上找到包含所有组件的完整示例,以及运行它们的说明。
提供审计元数据
首先,我们来讨论一下像蔬菜服务这样的应用程序如何提供所需的审计元数据。例如,应为审计目的提供以下元数据:
-
执行数据更改的应用程序用户,表示为 JWT 令牌(JSON Web Token)的 `sub` 声明。
-
请求时间戳,表示为 `Date` HTTP 标头。
-
用例标识符,通过调用 REST 资源方法的自定义 Java 注释提供。
以下是使用 JAX-RS API 持久化新蔬菜的 REST 资源的が基本实现。
@Path("/vegetables")
@RequestScoped
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public class VegetableResource {
@Inject
VegetableService vegetableService;
@POST
@RolesAllowed({"farmers"})
@Transactional
@Audited(useCase="CREATE VEGETABLE")
public Response createVegetable(Vegetable vegetable) {
if (vegetable.getId() != null) {
return Response.status(Status.BAD_REQUEST.getStatusCode()).build();
}
vegetable = vegetableService.createVegetable(vegetable);
return Response.ok(vegetable).status(Status.CREATED).build();
}
// update, delete ...
}如果您以前使用 JAX-RS 构建过 REST 服务,那么这个实现看起来会很熟悉:一个用 `@POST` 注释的资源方法接受传入的请求负载,并通过 CDI 注入的服务 bean 进行处理。然而,`@Audited` 注释是特殊的。它是一种自定义注释类型,有两个用途:
-
指定应在审计日志中引用的用例(“CREATE VEGETABLE”)。
-
绑定一个将为 `@Audited` 注释的方法的每次调用触发的拦截器。
当调用用 `@Audited` 注释的方法时,该拦截器将启动,并实现写入事务范围的审计元数据的逻辑。它看起来像这样:
@Interceptor (1)
@Audited(useCase = "")
@Priority(value = Interceptor.Priority.APPLICATION + 100) (2)
public class TransactionInterceptor {
@Inject
JsonWebToken jwt; (3)
@Inject
EntityManager entityManager;
@Inject
HttpServletRequest request;
@AroundInvoke
public Object manageTransaction(InvocationContext ctx) throws Exception {
BigInteger txtId = (BigInteger) entityManager (4)
.createNativeQuery("SELECT txid_current()")
.getSingleResult();
String useCase = ctx.getMethod().getAnnotation(Audited.class).useCase();
TransactionContextData context = new TransactionContextData(); (5)
context.transactionId = txtId.longValueExact();
context.userName = jwt.<String>claim("sub").orElse("anonymous");
context.clientDate = getRequestDate();
context.useCase = useCase;
entityManager.persist(context);
return ctx.proceed(); (6)
}
private ZonedDateTime getRequestDate() {
String requestDate = request.getHeader(HttpHeaders.DATE);
return requestDate != null ?
ZonedDateTime.parse(requestDate, DateTimeFormatter.RFC_1123_DATE_TIME) :
null;
}
}| 1 | `@Interceptor` 和 `@Audited` 将此标记为绑定到我们自定义的 `@Audited` 注释的拦截器。 |
| 2 | `@Priority` 注释控制审计拦截器在拦截器堆栈中的哪个点被调用。任何应用程序提供的拦截器都应具有大于 `Priority.APPLICATION` (2000) 的优先级;特别是,这可以确保事务已通过 `@Transactional` 注释及其伴随的拦截器(在 `Priority.PLATFORM_BEFORE` 范围 (< 1000) 内运行)在之前启动。 |
| 3 | 通过 MicroProfile JWT RBAC API 注入的调用者的 JWT 令牌。 |
每次审计的方法调用都会触发拦截器,并且将:
-
获取当前事务 ID(具体方法因数据库而异,示例中调用了 Postgres 的 `txid_current()` 函数)
-
通过 JPA 持久化 `TransactionContextData` 实体;其主键值是之前选择的事务 ID,它具有用于用户名(从 JWT 令牌获取)、请求日期(从 `DATE` HTTP 请求头获取)和用例标识符(从调用方法的 `@Audited` 注释获取)的属性
-
继续调用方法的调用流程
调用 REST 服务来创建和更新一些蔬菜时,数据库中应创建以下记录(有关构建示例代码和使用合适的 JWT 令牌调用蔬菜服务的说明,请参阅提供的示例中的 README)。
vegetablesdb> select * from inventory.vegetable;
+------+---------------+---------+
| id | description | name |
|------+---------------+---------|
| 1 | Spicy! | Potato |
| 11 | Delicious! | Pumpkin |
| 10 | Tasty! | Tomato |
+------+---------------+---------+vegetablesdb> select * from inventory.transaction_context_data;
+------------------+---------------------+------------------+----------------+
| transaction_id | client_date | usecase | user_name |
|------------------+---------------------+------------------+----------------|
| 608 | 2019-08-22 08:12:31 | CREATE VEGETABLE | farmerbob |
| 609 | 2019-08-22 08:12:31 | CREATE VEGETABLE | farmerbob |
| 610 | 2019-08-22 08:12:31 | UPDATE VEGETABLE | farmermargaret |
+------------------+---------------------+------------------+----------------+使用审计元数据丰富更改事件
随着业务数据(蔬菜)和事务范围元数据存储在数据库中,现在是时候设置 Debezium Postgres 连接器,并将 `vegetable` 和 `transaction_context_data` 表的更改事件流式传输到相应的 Kafka 主题中。有关部署连接器的详细信息,请再次参阅示例 README 文件。
`dbserver1.inventory.vegetable` 主题应包含已创建、已更新和已删除的蔬菜记录的更改事件,而 `dbserver1.inventory.transaction_context_data` 主题应仅包含为每条插入的元数据记录创建的消息。
| 主题保留 为了管理涉及主题的增长,每个主题的保留策略都应该定义得当。例如,对于实际的审计日志主题(包含丰富后的更改事件),基于时间的保留策略可能更合适,让每个日志事件保留尽可能长的时间,以满足您的需求。另一方面,事务元数据主题可以相对短暂,因为一旦所有相应的更改数据事件都已处理完毕,其条目就不再需要了。最好设置一些端到端延迟监控,以确保日志丰富器流处理应用程序能够跟上传入的消息,并且不会落后太远,以免事务消息在处理相应的更改事件之前被丢弃。 |
现在,如果我们查看这两个主题的消息,可以看到它们可以基于事务 ID 进行关联。它属于蔬菜更改事件的 `source` 结构的一部分,并且是事务元数据事件的消息键。

一旦找到了给定蔬菜更改事件的相应事务事件,就可以将前者中的 `client_date`、`usecase` 和 `user_name` 属性添加到后者。
这种消息转换是 Kafka Streams 的绝佳用例,它是一个用于在 Kafka 主题之上实现流处理应用程序的 Java API,提供了允许您过滤、转换、聚合和连接 Kafka 消息的运算符。
作为我们流处理应用程序的运行时环境,我们将使用 Quarkus,它是一个“为 GraalVM 和 OpenJDK HotSpot 量身定制的 Kubernetes 原生 Java 堆栈,由最优秀的 Java 库和标准组成”。
| 使用 Quarkus 构建 Kafka Streams 应用程序 Quarkus 附带一个Kafka Streams 扩展,以及许多其他扩展,该扩展允许构建在 JVM 和原生编译代码上运行的流处理应用程序。它负责流拓扑的生命周期,因此您无需处理注册 JVM 关机挂钩、等待所有输入主题创建等详细信息。 该扩展还附带“实时开发”支持,它会在您处理时自动重新加载流处理应用程序,从而在开发期间实现非常快的周转周期。 |
连接逻辑
当考虑连接逻辑的实际实现时,流到流连接可能看起来是一个合适的解决方案。通过为两个主题创建 `KStream`,我们可以尝试实现连接功能。一个挑战是如何定义一个合适的连接窗口,因为两个主题上的消息之间没有时间保证,并且我们不能错过任何事件。
另一个问题涉及到更改事件的排序保证。默认情况下,Debezium 将使用表的唯一键作为相应 Kafka 消息的消息键。这意味着同一蔬菜记录的所有消息将具有相同的键,因此将进入蔬菜 Kafka 主题的同一分区。这反过来又保证了这些事件的消费者以与创建时完全相同的顺序看到与同一蔬菜记录相关的消息。
现在,为了连接两个流,消息键在两边必须相同。这意味着蔬菜主题必须按事务 ID 重键(我们不能重键事务元数据主题,因为元数据事件中不包含有关相关蔬菜的信息;即使有,一个事务也可能影响多个蔬菜记录)。通过这样做,我们会丢失原始排序保证。一个蔬菜记录可能在两个后续事务中被修改,其更改事件可能位于重键主题的不同分区中,这可能导致消费者在收到第一个更改事件之前收到第二个更改事件。
如果 `KStream`-`KStream` 连接不可行,还有什么可以做的?`KStream` 和 `GlobalKTable` 之间的连接看起来也很有前景。它没有流到流连接的共分区要求,因为分布式 Kafka Streams 应用程序的所有节点都存在 `GlobalKTable` 的所有分区。这似乎是一个可以接受的权衡,因为来自事务元数据主题的消息可以相对快速地丢弃,并且相应表的大小应该在合理范围内。因此,我们可以有一个源自蔬菜主题的 `KStream` 和一个基于事务元数据主题的 `GlobalKTable`。
但不幸的是,存在时间问题:由于消息是从多个主题消费的,因此可能会出现这样的情况:在处理蔬菜流中的元素时,相应的事务元数据消息尚不可用。因此,根据我们是使用内连接还是左连接,在这种情况下,我们要么会跳过更改事件,要么在没有用事务元数据对其进行丰富的情况下传播它们。这两种结果都是不可取的。
带缓冲的自定义连接
`KStream` 和 `GlobalKTable` 的组合仍然指向正确的方向。只是我们不必依赖内置的连接运算符,而是必须实现自定义的连接逻辑。基本思想是缓冲到达蔬菜 `KStream` 的消息,直到相应的事务元数据消息可以从 `GlobalKTable` 的状态存储中获得。这可以通过创建一个自定义的转换器来实现,该转换器实现所需的缓冲逻辑并应用于蔬菜 `KStream`。
让我们从流拓扑本身开始。由于 Quarkus Kafka Streams 扩展,返回 `Topology` 对象的 CDI producer 方法是构建该拓扑所需的一切。
@ApplicationScoped
public class TopologyProducer {
static final String STREAM_BUFFER_NAME = "stream-buffer-state-store";
static final String STORE_NAME = "transaction-meta-data";
@ConfigProperty(name = "audit.context.data.topic")
String txContextDataTopic;
@ConfigProperty(name = "audit.vegetables.topic")
String vegetablesTopic;
@ConfigProperty(name = "audit.vegetables.enriched.topic")
String vegetablesEnrichedTopic;
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
StoreBuilder<KeyValueStore<Long, JsonObject>> streamBufferStateStore =
Stores
.keyValueStoreBuilder(
Stores.persistentKeyValueStore(STREAM_BUFFER_NAME),
new Serdes.LongSerde(),
new JsonObjectSerde()
)
.withCachingDisabled();
builder.addStateStore(streamBufferStateStore); (1)
builder.globalTable(txContextDataTopic, Materialized.as(STORE_NAME)); (2)
builder.<JsonObject, JsonObject>stream(vegetablesTopic) (3)
.filter((id, changeEvent) -> changeEvent != null)
.filter((id, changeEvent) -> !changeEvent.getString("op").equals("r"))
.transform(() -> new ChangeEventEnricher(), STREAM_BUFFER_NAME)
.to(vegetablesEnrichedTopic);
return builder.build();
}
}| 1 | 作为更改事件的缓冲状态存储,这些更改事件尚无法处理。 |
| 2 | 基于事务元数据主题的 `GlobalKTable`。 |
| 3 | 基于蔬菜主题的 `KStream`;在此流上,任何传入的墓碑标记都被过滤掉,原因是审计日志主题的保留策略通常应该是基于时间的,而不是基于日志压缩的。 类似地,快照事件也被过滤掉,假设它们与审计日志无关,并且 Debezium 连接器发起的快照事务没有相应的元数据。 任何其他消息都通过自定义 `Transformer`(见下文)用相应的事务元数据进行丰富,最后写入输出主题。 |
主题名称使用 MicroProfile Config API 注入,值在 Quarkus 的 `application.properties` 配置文件中提供。除了主题名称,该文件还包含有关 Kafka 引导服务器、默认 serdes 等信息。
audit.context.data.topic=dbserver1.inventory.transaction_context_data
audit.vegetables.topic=dbserver1.inventory.vegetable
audit.vegetables.enriched.topic=dbserver1.inventory.vegetable.enriched
# may be overridden with env vars
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-id=auditlog-enricher
quarkus.kafka-streams.topics=${audit.context.data.topic},${audit.vegetables.topic}
# pass-through
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUG
kafka-streams.default.key.serde=io.debezium.demos.auditing.enricher.JsonObjectSerde
kafka-streams.default.value.serde=io.debezium.demos.auditing.enricher.JsonObjectSerde
kafka-streams.processing.guarantee=exactly_once下一步,我们来看 `ChangeEventEnricher` 类,这是我们的自定义转换器。该实现基于更改事件被序列化为 JSON 的假设,但当然也可以使用 Avro 或 Protocol Buffers 等其他格式来完成。
这有点代码量,但希望将其分解成多个较小的方法可以使其更易于理解。
class ChangeEventEnricher implements Transformer
<JsonObject, JsonObject, KeyValue<JsonObject, JsonObject>> {
private static final Long BUFFER_OFFSETS_KEY = -1L;
private static final Logger LOG = LoggerFactory.getLogger(ChangeEventEnricher.class);
private ProcessorContext context;
private KeyValueStore<JsonObject, JsonObject> txMetaDataStore;
private KeyValueStore<Long, JsonObject> streamBuffer; (5)
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
streamBuffer = (KeyValueStore<Long, JsonObject>) context.getStateStore(
TopologyProducer.STREAM_BUFFER_NAME
);
txMetaDataStore = (KeyValueStore<JsonObject, JsonObject>) context.getStateStore(
TopologyProducer.STORE_NAME
);
context.schedule(
Duration.ofSeconds(1),
PunctuationType.WALL_CLOCK_TIME, ts -> enrichAndEmitBufferedEvents()
); (4)
}
@Override
public KeyValue<JsonObject, JsonObject> transform(JsonObject key, JsonObject value) {
boolean enrichedAllBufferedEvents = enrichAndEmitBufferedEvents(); (3)
if (!enrichedAllBufferedEvents) {
bufferChangeEvent(key, value);
return null;
}
KeyValue<JsonObject, JsonObject> enriched = enrichWithTxMetaData(key, value); (1)
if (enriched == null) { (2)
bufferChangeEvent(key, value);
}
return enriched;
}
/**
* Enriches the buffered change event(s) with the metadata from the associated
* transactions and forwards them.
*
* @return {@code true}, if all buffered events were enriched and forwarded,
* {@code false} otherwise.
*/
private boolean enrichAndEmitBufferedEvents() { (3)
Optional<BufferOffsets> seq = bufferOffsets();
if (!seq.isPresent()) {
return true;
}
BufferOffsets sequence = seq.get();
boolean enrichedAllBuffered = true;
for(long i = sequence.getFirstValue(); i < sequence.getNextValue(); i++) {
JsonObject buffered = streamBuffer.get(i);
LOG.info("Processing buffered change event for key {}",
buffered.getJsonObject("key"));
KeyValue<JsonObject, JsonObject> enriched = enrichWithTxMetaData(
buffered.getJsonObject("key"), buffered.getJsonObject("changeEvent"));
if (enriched == null) {
enrichedAllBuffered = false;
break;
}
context.forward(enriched.key, enriched.value);
streamBuffer.delete(i);
sequence.incrementFirstValue();
}
if (sequence.isModified()) {
streamBuffer.put(BUFFER_OFFSETS_KEY, sequence.toJson());
}
return enrichedAllBuffered;
}
/**
* Adds the given change event to the stream-side buffer.
*/
private void bufferChangeEvent(JsonObject key, JsonObject changeEvent) { (2)
LOG.info("Buffering change event for key {}", key);
BufferOffsets sequence = bufferOffsets().orElseGet(BufferOffsets::initial);
JsonObject wrapper = Json.createObjectBuilder()
.add("key", key)
.add("changeEvent", changeEvent)
.build();
streamBuffer.putAll(Arrays.asList(
KeyValue.pair(sequence.getNextValueAndIncrement(), wrapper),
KeyValue.pair(BUFFER_OFFSETS_KEY, sequence.toJson())
));
}
/**
* Enriches the given change event with the metadata from the associated
* transaction.
*
* @return The enriched change event or {@code null} if no metadata for the
* associated transaction was found.
*/
private KeyValue<JsonObject, JsonObject> enrichWithTxMetaData(JsonObject key,
JsonObject changeEvent) { (1)
JsonObject txId = Json.createObjectBuilder()
.add("transaction_id", changeEvent.get("source").asJsonObject()
.getJsonNumber("txId").longValue())
.build();
JsonObject metaData = txMetaDataStore.get(txId);
if (metaData != null) {
LOG.info("Enriched change event for key {}", key);
metaData = Json.createObjectBuilder(metaData.get("after").asJsonObject())
.remove("transaction_id")
.build();
return KeyValue.pair(
key,
Json.createObjectBuilder(changeEvent)
.add("audit", metaData)
.build()
);
}
LOG.warn("No metadata found for transaction {}", txId);
return null;
}
private Optional<BufferOffsets> bufferOffsets() {
JsonObject bufferOffsets = streamBuffer.get(BUFFER_OFFSETS_KEY);
if (bufferOffsets == null) {
return Optional.empty();
}
else {
return Optional.of(BufferOffsets.fromJson(bufferOffsets));
}
}
@Override
public void close() {
}
}| 1 | 当收到蔬菜更改事件时,使用更改事件的 `source` 块中的事务 ID 作为键,在事务主题 `GlobalKTable` 的状态存储中查找相应的元数据;如果找到了元数据,则将元数据添加到更改事件(在 `audit` 字段下)并返回该丰富后的事件。 |
| 2 | 如果未找到元数据,则将传入事件添加到更改事件的缓冲区中并返回。 |
| 3 | 在实际处理传入事件之前,会处理所有缓冲的事件;这对于确保保留原始更改事件是必需的;只有当所有事件都能被丰富后,传入事件才会被处理。 |
| 4 | 为了在没有新更改事件到来时也能发出缓冲的事件,会安排一个标点,定期处理缓冲区。 |
| 5 | 一个用于蔬菜事件的缓冲区,其相应的元数据尚未到达。 |
关键部分是未处理更改事件的缓冲区。为了维护事件的顺序,必须按插入顺序处理缓冲区,从第一个插入的事件开始(想想 FIFO 队列)。由于从 `KeyValueStore` 获取所有条目时没有保证的遍历顺序,因此通过使用严格递增序列的值作为键来实现这一点。密钥值存储中的一个特殊条目用于存储有关缓冲区中当前“最旧”索引和下一个序列值的信息。
人们也可以考虑这种缓冲区的替代实现,例如基于 Kafka 主题或自定义 `KeyValueStore` 实现,该实现确保从最早到最新的条目进行迭代。最终,如果 Kafka Streams 提供了内置的重试尚未连接的流元素的方法,这将很有用;这将避免任何自定义缓冲实现。
| 如果出现问题 对于可靠且一致的处理逻辑,考虑故障情况(例如,如果流应用程序在将元素添加到缓冲区后但在更新序列值之前崩溃)至关重要。 关键在于 `application.properties` 中给出的 `processing.guarantee` 属性的 `exactly_once` 值。这确保了事务性一致的处理;例如,在上述场景中,重新启动后,原始更改事件将被再次处理,并且缓冲区状态将与事件首次处理之前完全相同。 丰富后的蔬菜事件的消费者应应用 `read_committed` 的隔离级别;否则,在应用程序崩溃后(如果在缓冲区事件被转发但尚未从缓冲区中删除之后),它们可能会看到未提交的、因此重复的消息。 |
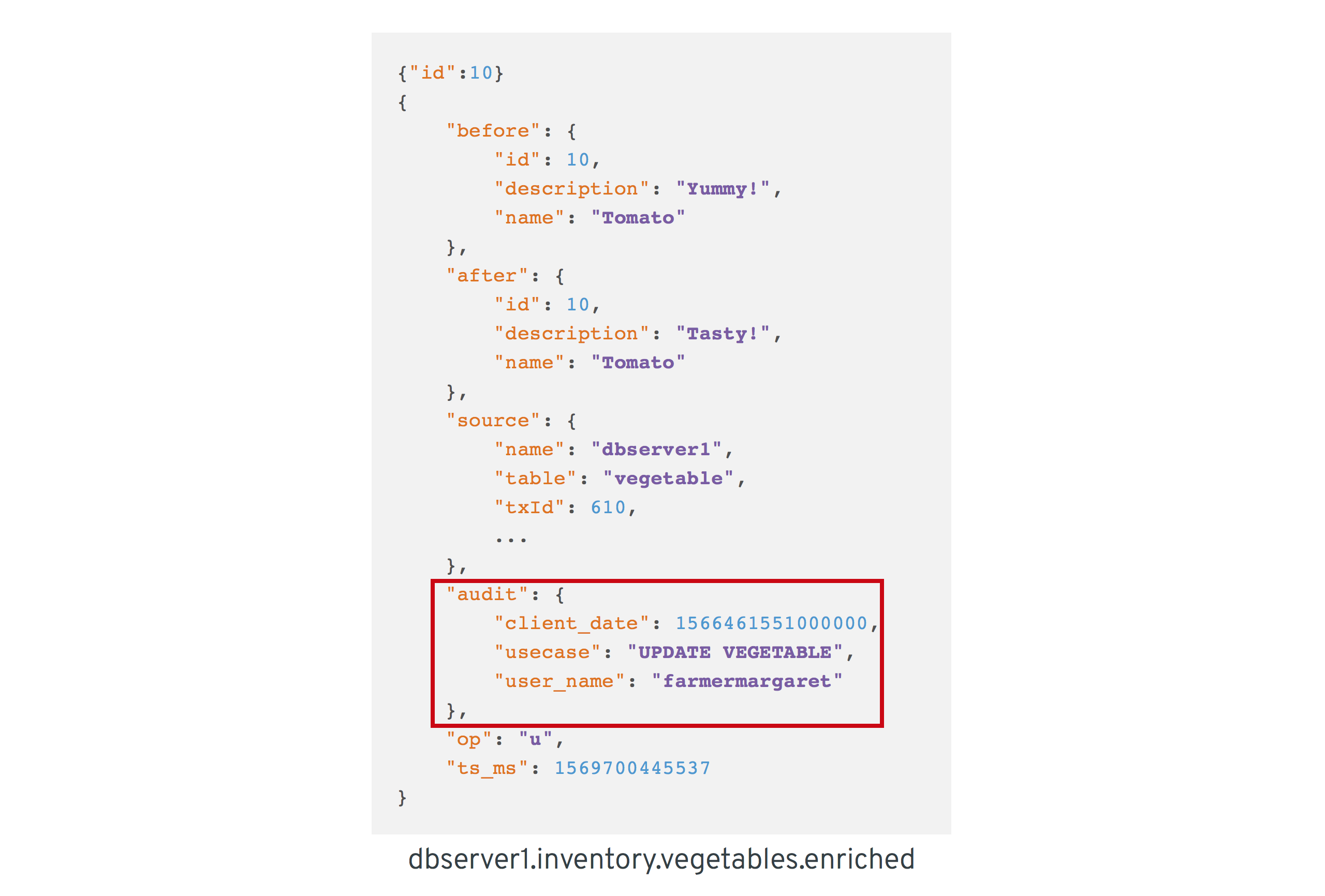
有了自定义转换器逻辑后,我们可以构建 Quarkus 项目并运行流处理应用程序。您应该在 `dbserver1.inventory.vegetable.enriched` 主题中看到类似这样的消息。
{"id":10}
{
"before": {
"id": 10,
"description": "Yummy!",
"name": "Tomato"
},
"after": {
"id": 10,
"description": "Tasty!",
"name": "Tomato"
},
"source": {
"version": "0.10.0-SNAPSHOT",
"connector": "postgresql",
"name": "dbserver1",
"ts_ms": 1569700445392,
"snapshot": "false",
"db": "vegetablesdb",
"schema": "inventory",
"table": "vegetable",
"txId": 610,
"lsn": 34204240,
"xmin": null
},
"op": "u",
"ts_ms": 1569700445537,
"audit": {
"client_date": 1566461551000000,
"usecase": "UPDATE VEGETABLE",
"user_name": "farmermargaret"
}
}当然,可以根据您的具体需求调整缓冲区处理逻辑;例如,代替无限期地等待相应的事务元数据,我们也可以决定在等待一段时间后传播未丰富化的更改事件,或者抛出指示缺少元数据的异常。
为了查看缓冲是否按预期工作,您可以做一个小实验:直接在数据库中使用 SQL 修改一个蔬菜记录。Debezium 将捕获事件,但由于没有提供相应的事务元数据,该事件将不会转发到丰富化的蔬菜主题。如果您使用 REST API 添加另一个蔬菜,它也不会被传播:尽管有其元数据记录,但它被之前的更改事件阻止了。只有当您在 `transaction_context_data` 表中插入了第一个更改事务的元数据记录后,这两个更改事件才会被处理并发送到输出主题。
总结
在这篇博客文章中,我们讨论了如何结合使用变更数据捕获和流处理来以高效、低开销的方式构建审计日志。与基于库和触发器的方法相比,形成审计跟踪的事件通过 CDC 从数据库的事务日志中检索,并且除了每笔事务插入单个元数据记录(任何类型的审计日志都需要类似形式的插入)外,不会对 OLTP 事务产生任何开销。此外,当数据记录受到批量更新或删除时,也可以获得审计日志条目,这通常是基于库的审计解决方案无法实现的。
通常应该包含在审计日志中的其他元数据,可以由应用程序通过单独的表提供,该表也通过 Debezium 进行捕获。借助 Kafka Streams,实际的数据更改事件可以用该元数据表中的数据进行丰富。
我们尚未讨论的一个方面是查询审计跟踪条目,例如,检查数据的特定先前版本。为此,丰富后的更改数据事件通常会存储在一个可查询的数据库中。与基本数据复制管道不同,在这种情况下,数据库中不仅会存储每个记录的最新版本,还会存储所有版本,即主键通常会附加每个更改的事务 ID。这将允许选择单个数据记录,甚至连接多个表以获取根据给定事务 ID 有效的数据。如何在未来更详细地实现这一点可以在未来的帖子中讨论。
我们非常欢迎您对此审计日志构建方法的反馈,请在下方发表评论。要开始您自己的实现,您可以查看 GitHub 上 Debezium 示例存储库中的代码。
非常感谢 Chris Cranford、Hans-Peter Grahsl、Ashhar Hasan、Anna McDonald 和 Jiri Pechanec 在撰写本文及配套示例代码时提供的反馈!
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。