
上周宣布Quarkus 以来,在 Java 社区引起了极大的兴趣:它由最优秀的 Java 库和标准构建而成,支持构建基于 GraalVM 和 OpenJDK HotSpot 的 Kubernetes 原生应用程序。在这篇博文中,我们将演示基于 Quarkus 的微服务如何通过 Apache Kafka 消费 Debezium 的数据变更事件。为此,我们将看看如何将我们最近关于Outbox 模式的帖子中的运输微服务转换为基于 Quarkus 的服务。
Quarkus 是一个为基于 Java 平台构建云原生应用程序而设计的 Java 技术栈。它集成了成熟的库,如 Hibernate ORM、Vert.x、Netty、RESTEasy 和 Apache Camel,以及来自 Eclipse MicroProfile 计划的 API,例如 Config 或 Reactive Messaging。使用 Quarkus,您可以同时使用命令式和响应式风格开发应用程序,也可以根据需要组合这两种方法。
它旨在显著降低内存消耗并提高启动时间。最后但同样重要的是,Quarkus 支持 OpenJDK HotSpot 和 GraalVM 虚拟机。使用 GraalVM,可以将应用程序编译成原生二进制文件,从而进一步减少资源消耗和启动时间。
要了解更多关于 Quarkus 本身的信息,我们建议您参考其出色的 入门指南。
使用 Quarkus 消费 Kafka 消息
在最初的 示例应用程序 中演示了 outbox 模式,有一个基于 Thorntail 的微服务(“shipment”)用于消费 Debezium 连接器产生的事件。我们已经使用一个名为“shipment-service-quarkus”的新服务扩展了这个示例。它提供了与“shipment-service”相同的功能,但它是作为一个基于 Quarkus 的微服务实现的,而不是 Thorntail。
这使得整体架构看起来像这样
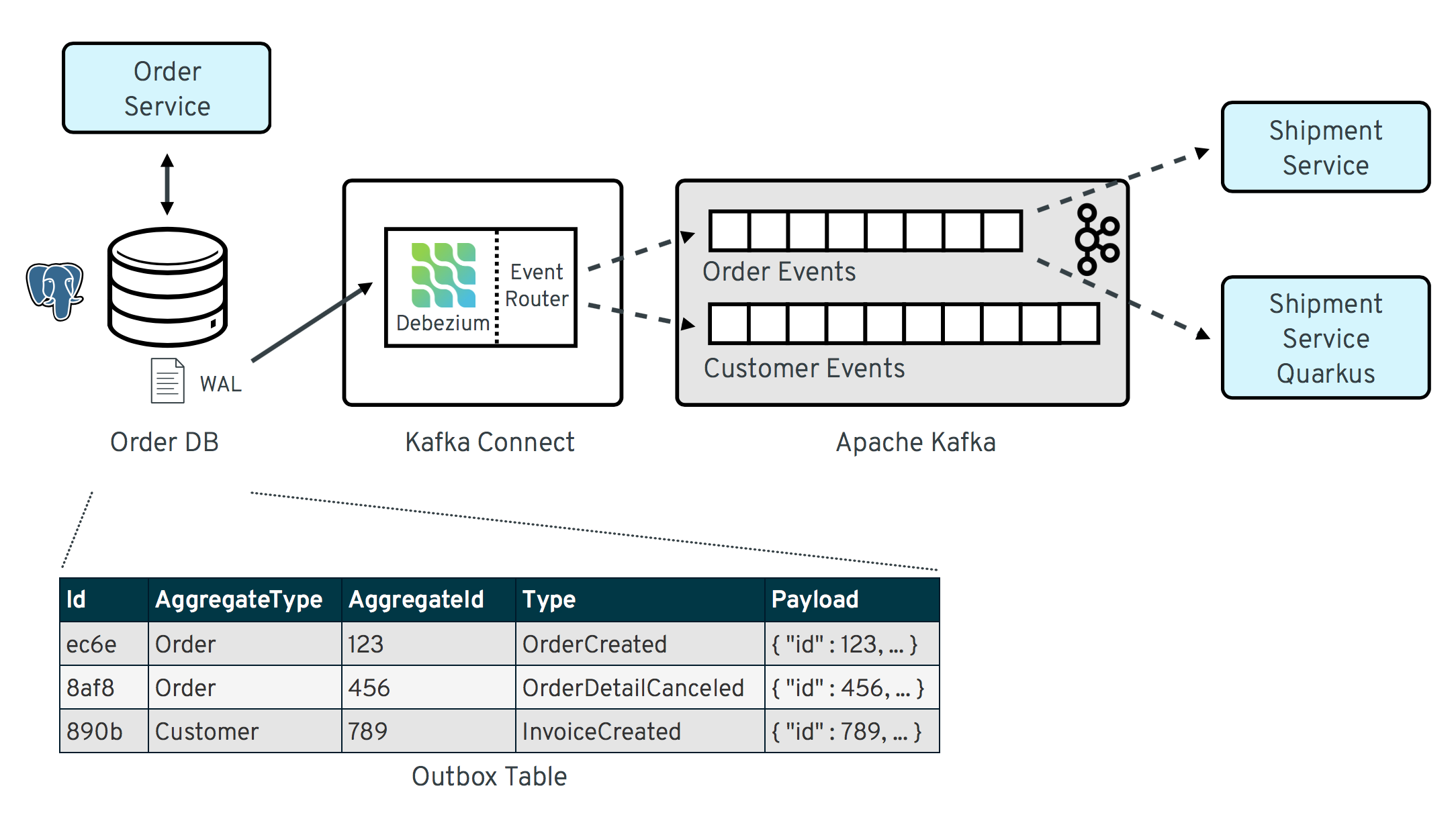
要将原始服务适配成一个基于 Quarkus 的应用程序,只需要进行一些小的改动
-
Quarkus 目前只支持 MariaDB 而不支持 MySQL;因此,我们包含了一个 MariaDB 实例,服务将数据写入其中
-
用于反序列化传入 JSON 消息的 JSON-P API 目前无法在没有 RESTEasy 的情况下使用(参见 issue #1480,该问题应该很快就会修复);因此,代码已被修改为使用 Jackson API
-
不使用 Kafka 消费者 API,而是使用 MicroProfile 定义的 Reactive Messaging API 来接收来自 Apache Kafka 的消息;作为该 API 的一种实现,我们使用了 SmallRye 项目 提供的实现,它被打包为一个 Quarkus 扩展。
虽然前两个步骤只是技术细节,但 Reactive Messaging API 相比于原始消费者中的轮询循环是一个不错的简化。要消费 Kafka 主题中的消息,只需要用 @Incoming 注释一个方法,当新消息到达时,它就会被自动调用。
@ApplicationScoped
public class KafkaEventConsumer {
@Incoming("orders")
public CompletionStage<Void> onMessage(KafkaMessage<String, String> message)
throws IOException {
// handle message...
return message.ack();
}
}“orders”消息源通过 MicroProfile Config API 进行配置,它将其解析为在原始 outbox 示例中已知的“OrderEvents”主题。
构建过程
构建过程与之前基本相同。现在使用的是 Quarkus Maven 插件,而不是 Thorntail Maven 插件。
使用的 Quarkus 扩展如下
-
io.quarkus:quarkus-hibernate-orm:支持 Hibernate ORM 和 JPA
-
io.quarkus:quarkus-jdbc-mariadb:支持通过 JDBC 访问 MariaDB
-
io.quarkus:quarkus-smallrye-reactive-messaging-kafka:支持通过 MicroProfile Reactive Messaging API 访问 Kafka
它们还会引入其他一些扩展,例如 quarkus-arc(Quarkus CDI 运行时)和 quarkus-vertx(用于响应式消息支持)。
此外,还需要进行另外两项更改
-
添加了一个名为
native的新构建配置文件;这用于使用 Quarkus Maven 插件将服务编译成原生二进制镜像。 -
运行构建时启用了
native-image.docker-build系统属性;这意味着原生镜像构建是在 Docker 容器内完成的,因此无需在开发者的机器上安装 GraalVM。
所有繁重的工作都由 Quarkus Maven 插件完成,它在 pom.xml 中配置如下
<build>
<finalName>shipment</finalName>
<plugins>
...
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<version>${version.quarkus}</version>
<executions>
<execution>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
...
<profile>
<id>native</id>
<build>
<plugins>
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<version>${version.quarkus}</version>
<executions>
<execution>
<goals>
<goal>native-image</goal>
</goals>
<configuration>
<enableHttpUrlHandler>true</enableHttpUrlHandler>
<autoServiceLoaderRegistration>false</autoServiceLoaderRegistration>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>配置
与任何 Quarkus 应用程序一样,shipment 服务通过 application.properties 文件进行配置。
quarkus.datasource.url: jdbc:mariadb://shipment-db-quarkus:3306/shipmentdb
quarkus.datasource.driver: org.mariadb.jdbc.Driver
quarkus.datasource.username: mariadbuser
quarkus.datasource.password: mariadbpw
quarkus.hibernate-orm.database.generation=drop-and-create
quarkus.hibernate-orm.log.sql=true
smallrye.messaging.source.orders.type=io.smallrye.reactive.messaging.kafka.Kafka
smallrye.messaging.source.orders.topic=OrderEvents
smallrye.messaging.source.orders.bootstrap.servers=kafka:9092
smallrye.messaging.source.orders.key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
smallrye.messaging.source.orders.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
smallrye.messaging.source.orders.group.id=shipment-service-quarkus在我们的例子中,它包含
-
定义一个数据源(基于 MariaDB),shipment 服务将数据写入其中,
-
定义一个消息源,它以“OrderEvents”Kafka 主题为后盾,使用指定的引导服务器、反序列化器和 Kafka 消费者组 ID。
执行
Docker Compose 配置文件已得到丰富,增加了 MariaDB 和新的基于 Quarkus 的 shipment 服务。因此,当执行 docker-compose up 时,两个 shipment 服务将并排启动:原始的基于 Thorntail 的服务和使用 Quarkus 的新服务。当订单服务收到新的采购订单并通过 outbox 表将相应的事件导出到 Apache Kafka 时,这两个 shipment 服务都会处理该消息,因为它们使用不同的消费者组 ID。
性能数据
这些数据肯定不是科学的,但它们很好地表明了原生 Quarkus 应用程序和运行在 JVM 上的 Thorntail 服务之间的数量级差异。
| Quarkus 服务 | Thorntail 服务 | |
|---|---|---|
内存 [MB] | 33.8 | 1257 |
启动时间 [ms] | 260 | 5746 |
应用程序包大小 [MB] | 54 | 131 |
内存数据是通过 htop 工具获得的。启动时间测量直到应用程序就绪消息被打印出来。与所有性能测量一样,您应该根据您的设置和工作负载进行自己的比较,以深入了解您特定用例的实际差异。
总结
在这篇文章中,我们成功地演示了可以在使用 Quarkus Java 技术栈编写的 Java 应用程序中消费 Debezium 生成的事件。我们还展示了如何提供这样的应用程序作为二进制镜像,并提供了粗略的性能数据,证明了显著的资源节省。
如果您想亲眼看看将 Java 微服务作为原生镜像部署的威力,可以在 Debezium 示例仓库中找到此实现的完整 源代码。如果您有任何问题或反馈,请在下面的评论中告诉我们;期待您的回复!
非常感谢 Guillaume Smet 审阅了本文的早期版本!
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。