
在数据更改后更新外部全文搜索索引(例如 Elasticsearch)是变更数据捕获 (CDC) 非常流行的用例。
正如我们在一段时间前的 博客文章 中讨论过的,Debezium 的 CDC 源连接器与 Confluent 的 Elasticsearch 接收器连接器 的结合,可以轻松地在 MySQL、Postgres 等数据库中捕获数据更改,并近乎实时地将它们推送到 Elasticsearch。这导致源数据库中的表与 Elasticsearch 中的相应搜索索引之间存在 1:1 的关系,对于许多用例来说是完全可以的。
但是,如果您想将整个聚合数据放入单个索引中,情况会更具挑战性。例如,一个客户及其所有地址;这些通常存储在关系型数据库的两个单独的表中,通过外键连接,而您只想在 Elasticsearch 中有一个索引,其中包含具有嵌入式地址的客户文档,从而允许您根据地址高效地搜索客户。
继我们最近讨论的 基于 KStreams 的解决方案 之后,我们想在本文中介绍一个通过应用程序层驱动物化此类聚合视图的替代方案。
概述
其思想是在原始数据发生更改的时刻,在源数据库的单独表中物化视图。
聚合数据被序列化为 JSON 结构(自然可以表示任何嵌套的对象结构)并存储在一个特定的表中。这发生在实际更改数据的事务内部,这意味着聚合视图始终与主数据一致。特别是,这种方法不会暴露中间聚合,不像上面链接的帖子中讨论的基于 KStreams 的解决方案。
下图显示了整体架构
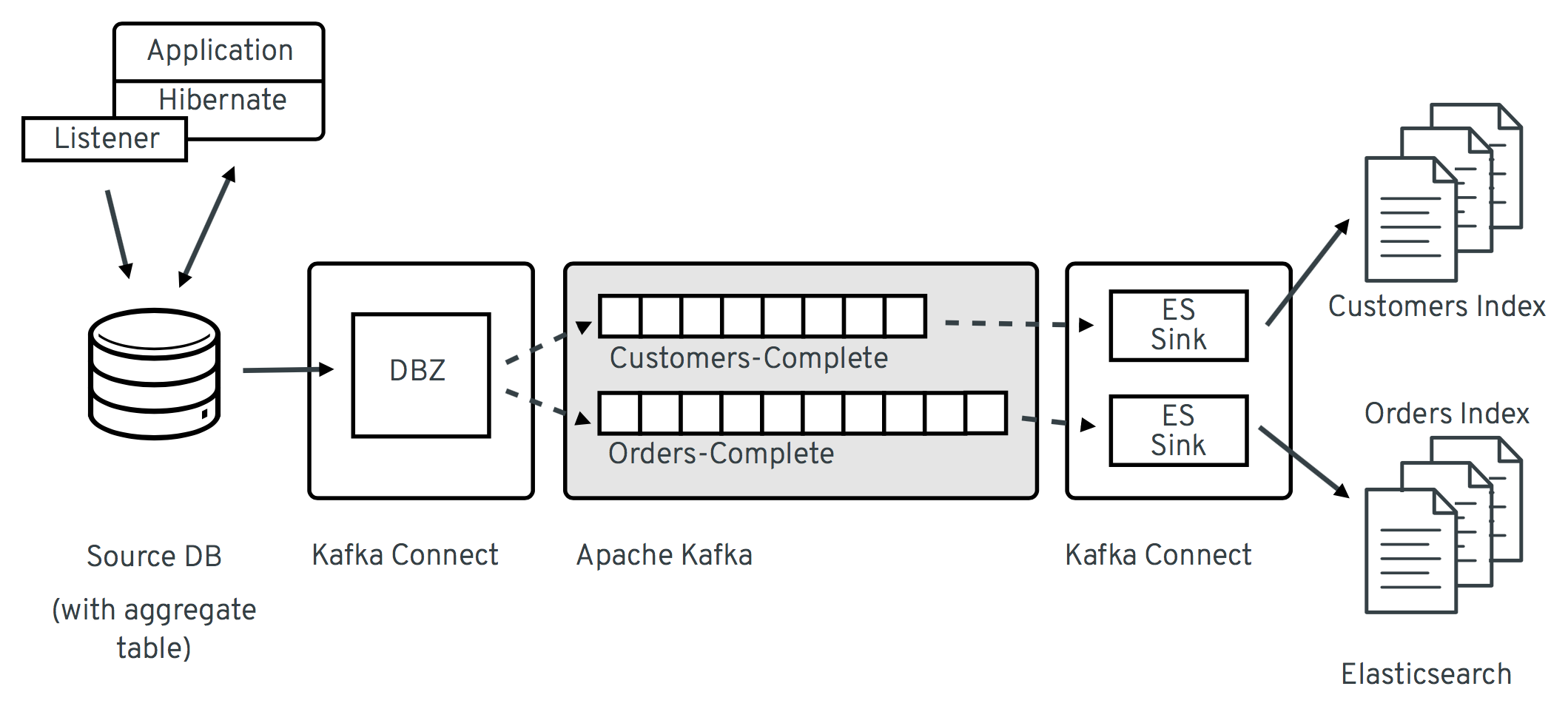
在这里,聚合视图通过对 Hibernate ORM 的一个小扩展来实现物化,该扩展将 JSON 聚合存储在源数据库中(请注意,“聚合视图”可以被概念上视为与不同关系型数据库中已知的“物化视图”相同,因为它们物化了“连接”操作的结果,但技术上我们不使用后者来存储聚合视图,而是使用常规表)。然后 Debezium 捕获该聚合表中的更改,并将其流式传输到每个聚合类型的一个主题。Elasticsearch 接收器连接器可以订阅这些主题,并更新相应的全文索引。
您可以在我们的 示例存储库 中找到该想法的概念验证实现(所谓的 Hibernate 扩展和相关代码)。当然,这个通用想法不限于 Hibernate ORM 或 JPA,您可以使用任何其他数据访问 API 实现类似的功能。
通过 Hibernate ORM 创建聚合视图
在接下来的内容中,让我们假设我们在数据库中持久化一个简单的域模型(包括一个 `Customer` 实体和一些相关实体,如 `Address`、(customer) `Category` 等)。使用 Hibernate 进行此操作,允许我们通过 Hibernate 事件监听器 使聚合的创建对实际使用应用程序的代码完全透明。由于其可扩展的架构,我们只需将此监听器添加到类路径中,它将在引导实体管理器/会话工厂时自动拾取。
我们的示例监听器响应一个注解 `@MaterializeAggregate`,该注解标记了那些应该成为物化聚合根的实体类型。
@Entity
@MaterializeAggregate(aggregateName="customers-complete")
public class Customer {
@Id
private long id;
private String firstName;
@OneToMany(mappedBy = "customer", fetch = FetchType.EAGER, cascade = CascadeType.ALL)
private Set<Address> addresses;
@ManyToOne
private Category category;
...
}现在,如果任何用 `@MaterializeAggregate` 注解的实体通过 Hibernate 被插入、更新或删除,监听器就会生效,并物化聚合根(客户)及其关联实体(地址、类别)的 JSON 视图。
在底层,Jackson API 用于将模型序列化为 JSON。这意味着您可以使用它的任何注解来定制 JSON 输出,例如 `@JsonIgnore` 以排除 `Address` 到 `Customer` 的反向关系。
@Entity
public class Address {
@Id
private long id;
@ManyToOne
@JoinColumn(name = "customer_id")
@JsonIgnore
private Customer customer;
private String street;
private String city;
...
}请注意,`Address` 本身没有用 `@MaterializeAggregate` 注解,也就是说,它不会自行物化为聚合视图。
在使用 JPA 的 `EntityManager` 插入或更新一些客户后,让我们看一下由监听器填充的 `aggregates` 表(为简洁起见,省略了值 schema)。
> select * from aggregates;
| rootType | keySchema | rootId | materialization | valueSchema |
| customers-complete
| {
"schema" : {
"type" : "struct",
"fields" : [ {
"type" : "int64",
"optional" : false,
"field" : "id"
} ],
"optional" : false,
"name" : "customers-complete.Key"
}
}
| { "id" : 1004 }
| { "schema" : { ... } }
| {
"id" : 1004,
"firstName" : "Anne",
"lastName" : "Kretchmar",
"email" : "annek@noanswer.org",
"tags" : [ "long-term", "vip" ],
"birthday" : 5098,
"category" : {
"id" : 100001,
"name" : "Retail"
},
"addresses" : [ {
"id" : 16,
"street" : "1289 University Hill Road",
"city" : "Canehill",
"state" : "Arkansas",
"zip" : "72717",
"type" : "SHIPPING"
} ]
} |该表包含以下列:
-
rootType:聚合的名称,如 `@MaterializeAggregate` 注解中所指定。 -
rootId:聚合的 ID,序列化为 JSON。 -
materialization:聚合本身,序列化为 JSON;在本例中是客户及其地址、类别等。 -
keySchema:行键的 Kafka Connect schema。 -
valueSchema:物化数据的 Kafka Connect schema。
让我们稍微讨论一下这两个 schema 列。JSON 本身在支持的数据类型方面非常有限。因此,例如,如果没有额外信息,我们将丢失数字字段值范围(int 与 long 等)的信息。因此,监听器从实体模型派生键和聚合视图的相应 schema 信息,并将其存储在聚合记录中。
现在,Jackson 本身仅支持 JSON Schema,这对于我们的目的来说可能有点太有限了。因此,示例实现为 Jackson 的 schema 系统提供了自定义序列化器,这允许我们发出 Kafka Connect 的 schema 表示(具有更精确的类型信息),而不是纯 JSON Schema。当我们想将键和值的基于字符串的 JSON 表示扩展为类型化的 Kafka Connect 记录时,这将在后续有所帮助。
捕获聚合表中的更改
现在我们已经有了一个机制,可以在应用程序数据通过 Hibernate 更改时,透明地将聚合持久化到源数据库中的一个单独表中。请注意,这发生在源事务的边界内,因此如果由于某种原因回滚了相同的事务,聚合视图也不会被更新。
Hibernate 监听器在写入聚合视图时使用 insert-or-update 语义,即对于给定的聚合根,聚合表中始终只有一个相应的条目反映其当前状态。如果删除了聚合根实体,监听器还将删除聚合表中的相应条目。
那么,现在让我们设置 Debezium 来捕获 `aggregates` 表中的任何更改。
curl -i -X POST \
-H "Accept:application/json" \
-H "Content-Type:application/json" \
http://localhost:8083/connectors/ -d @- <<-EOF
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.whitelist": "inventory",
"table.whitelist": ".*aggregates",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory"
}
}
EOF这会将 MySQL 连接器注册到“inventory”数据库(我们正在使用 Debezium 教程 的扩展版本),捕获“aggregates”表中的任何更改。
展开 JSON
如果我们现在浏览相应的 Kafka 主题,我们将看到 Debezium 格式的数据更改事件,用于 `aggregates` 表的所有更改。
记录“after”状态中的“materialization”字段仍然是一个包含 JSON 字符串的单个字段。我们更希望拥有一个强类型的 Kafka Connect 记录,其 schema 精确描述了聚合结构及其字段的类型。为此,示例项目提供了一个 SMT(单消息转换),它接受 JSON 物化和相应的 `valueSchema`,并将其转换为完整的 Kafka Connect 记录。键也进行同样的处理。DELETE 事件被重写为墓碑事件。最后,SMT 将每个记录重新路由到一个以聚合根命名的主题,允许消费者仅订阅特定聚合类型的更改。
因此,在注册 Debezium CDC 连接器时,让我们添加该 SMT。
...
"transforms":"expandjson",
"transforms.expandjson.type":"io.debezium.aggregation.smt.ExpandJsonSmt",
...现在浏览“customers-complete”主题时,我们将看到我们期望的强类型 Kafka Connect 记录。
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int64",
"optional": false,
"field": "id"
}
],
"optional": false,
"name": "customers-complete.Key"
},
"payload": {
"id": 1004
}
}
{
"schema": {
"type": "struct",
"fields": [ ... ],
"optional": true,
"name": "urn:jsonschema:com:example:domain:Customer"
},
"payload": {
"id": 1004,
"firstName": "Anne",
"lastName": "Kretchmar",
"email": "annek@noanswer.org",
"active": true,
"tags" : [ "long-term", "vip" ],
"birthday" : 5098,
"category": {
"id": 100001,
"name": "Retail"
},
"addresses": [
{
"id": 16,
"street": "1289 University Hill Road",
"city": "Canehill",
"state": "Arkansas",
"zip": "72717",
"type": "LIVING"
}
]
}
}要确认这些是实际的类型化 Kafka Connect 记录,而不仅仅是一个 JSON 字符串字段,您可以例如使用 Avro 消息转换器,并在 schema 注册表中检查消息 schema。
将聚合消息汇入 Elasticsearch
最后一步是注册 Confluent Elasticsearch 接收器连接器,将其与“customers-complete”主题连接起来,并让它将任何更改推送到相应的索引。
curl -i -X POST \
-H "Accept:application/json" \
-H "Content-Type:application/json" \
http://localhost:8083/connectors/ -d @- <<-EOF
{
"name": "es-customers",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "customers-complete",
"connection.url": "http://elastic:9200",
"key.ignore": "false",
"schema.ignore" : "false",
"behavior.on.null.values" : "delete",
"type.name": "customer-with-addresses",
"transforms" : "key",
"transforms.key.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.key.field": "id"
}
}
EOF这使用了 Connect 的 `ExtractField` 转换来仅从键结构中获取实际的 ID 值,并将其用作相应 Elasticsearch 文档的键。指定“behavior.on.null.values”选项将使连接器在遇到墓碑消息(即键存在但值不存在的消息)时,从索引中删除相应的文档。
最后,我们可以使用 Elasticsearch REST API 来浏览索引,当然也可以使用其强大的全文查询语言来查找具有地址或嵌入到聚合结构中的任何其他属性的客户。
> curl -X GET -H "Accept:application/json" \
http://localhost:9200/customers-complete/_search?pretty
{
"_shards": {
"failed": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "1004",
"_index": "customers-complete",
"_score": 1.0,
"_source": {
"active": true,
"addresses": [
{
"city": "Canehill",
"id": 16,
"state": "Arkansas",
"street": "1289 University Hill Road",
"type": "LIVING",
"zip": "72717"
}
],
"tags" : [ "long-term", "vip" ],
"birthday" : 5098,
"category": {
"id": 100001,
"name": "Retail"
},
"email": "annek@noanswer.org",
"firstName": "Anne",
"id": 1004,
"lastName": "Kretchmar",
"scores": [],
"someBlob": null,
"tags": []
},
"_type": "customer-with-addresses"
}
],
"max_score": 1.0,
"total": 1
},
"timed_out": false,
"took": 11
}这样,客户的完整数据,包括其地址、类别、标签等,就被物化为 Elasticsearch 中的单个文档。如果您使用 JPA 更新客户,您将近乎实时地看到索引中的数据相应更新。
优点和缺点
那么,与 基于 KStreams 的方法 相比,这种从多个源表物化聚合的方法有哪些优缺点?
最大的优点是数据一致性和对事务边界的感知,而建议形式的基于 KStreams 的解决方案容易暴露中间聚合。例如,如果您存储一个客户和三个地址,可能会发生流式查询首先创建一个客户和前两个地址的聚合,然后不久之后是所有三个地址的完整聚合。这里讨论的方法则不会出现这种情况,因为您只会将完整的聚合流式传输到 Kafka。此方法也感觉更“轻量级”,也就是说,一个简单的标记注解(以及一些用于微调输出 JSON 结构的 Jackson 注解)足以从您的域模型中实现聚合,而使用 KStreams 解决方案设置所需的流、临时表等需要更多的精力。
通过应用程序层驱动聚合的缺点是它不能完全独立于您访问主数据的方式。如果您绕过了应用程序,例如直接在数据库中修补数据,这些更新自然会被遗漏,需要刷新受影响的聚合。尽管这也可以通过变更数据捕获和 Debezium 来完成:源表中的更改事件可以被应用程序自身捕获和消费,允许它在外部数据更改后重新物化聚合。您还可能认为在源事务中运行 JSON 序列化并将聚合存储在源数据库中会带来一些开销。但这通常是可以接受的。
另一个需要问的问题是,在中间聚合表上使用变更数据捕获比直接向 Elasticsearch 发送 REST 请求有什么优势?答案是大大提高了健壮性和容错性。如果由于某种原因无法访问 Elasticsearch 集群,Kafka 和 Kafka Connect 的机制将确保所有更改事件最终都会传播,一旦接收器恢复正常。除了 Elasticsearch,其他消费者也可以订阅聚合主题,日志可以从头开始重放等等。
请注意,虽然我们主要讨论使用 Elasticsearch 作为数据接收器,但也有其他数据存储和连接器支持复杂结构化的记录。一个例子是 MongoDB 和 Hans-Peter Grahsl 维护的 接收器连接器,您可以使用它将客户聚合汇入 MongoDB,例如,允许通过单个主键查找来高效检索客户及其所有相关数据。
展望
Hibernate ORM 扩展以及本文讨论的 SMT 可以在我们的 示例存储库 中找到。目前它们应被视为“概念验证”级别。
话虽如此,我们正在考虑将其作为 Debezium 的一个正式组件,允许您仅通过引入这个新组件来在基于 Hibernate 的应用程序中使用这种聚合方法。为此,我们首先需要改进一些东西。最重要的是,需要一个 API 来允许您按需(重新)创建聚合,例如针对现有数据或通过 Criteria API / JPQL 更新的数据(这将由监听器错过)。此外,如果任何引用实体发生更改,聚合也应该自动重新创建(在当前的 PoC 中,只有客户实例本身发生更改才会触发其聚合视图重建,但其地址的更改则不会)。
如果您喜欢这个想法,请告诉我们,以便我们能够评估其普遍兴趣。此外,如果您有兴趣为 Debezium 项目做出贡献,这将是一个很好的工作项目。期待您的反馈,例如在下面的评论区或我们的 邮件列表 中。
非常感谢 Hans-Peter Grahsl 对本文早期版本的反馈!
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。