
大多数情况下,Debezium 用于将数据更改流式传输到 Apache Kafka。但如果您使用的是其他流式传输平台,例如 Apache Pulsar,或者云原生解决方案,例如 Amazon Kinesis、Azure Event Hubs 等等呢?您仍然可以受益于 Debezium 强大的变更数据捕获 (CDC) 功能,并从 MySQL、Postgres、SQL Server 等数据库中摄取更改吗?
事实证明,只需一点粘合代码,就可以做到!接下来,我们将讨论如何使用 Debezium 捕获 MySQL 数据库中的更改,并将更改事件流式传输到 Kinesis,这是一个在 Amazon 云中提供的完全托管的数据流服务。
介绍 Debezium 嵌入式引擎
Debezium 实现为一套 Kafka 连接器,因此通常通过 Kafka Connect 运行。但 Debezium 中有一个鲜为人知的宝藏,那就是 嵌入式引擎。
使用此引擎时,Debezium 连接器不在 Kafka Connect 中执行,而是作为库嵌入到您自己的 Java 应用程序中。为此,debezium-embedded 模块提供了一个小型运行时环境,该环境执行本来由 Kafka Connect 框架处理的任务:从连接器请求更改记录、提交偏移量等。连接器生成的每个更改记录都会传递给一个配置的事件处理程序方法,在本例中,该方法会将记录转换为其 JSON 表示形式,并使用 Kinesis Java API 将其提交到 Kinesis 流。
整体架构如下所示
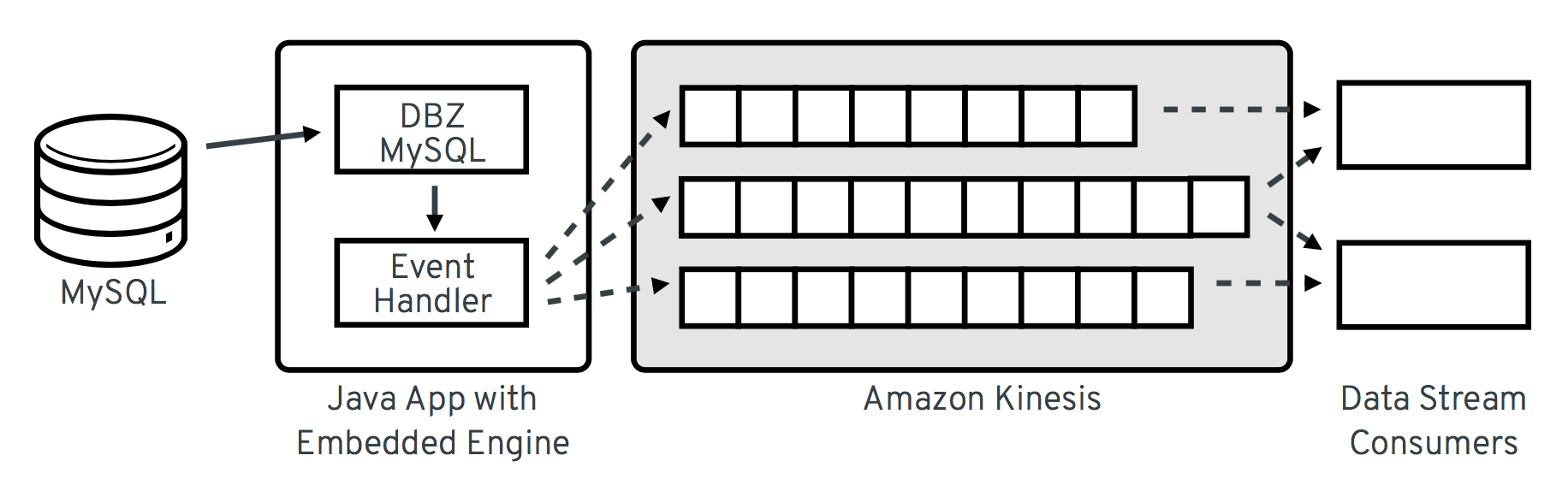
现在让我们一步步介绍所需的代码相关部分。完整的可执行示例可以在 GitHub 上的 debezium-examples 仓库中找到。
设置
要使用 Debezium 的嵌入式引擎,请将 debezium-embedded 依赖项以及您选择的 Debezium 连接器添加到项目的 pom.xml 文件中。在下面的示例中,我们将使用 MySQL 连接器。我们还需要添加对 Kinesis Client API 的依赖项,因此以下是所需的依赖项
...
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-embedded</artifactId>
<version>0.8.3.Final</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-mysql</artifactId>
<version>0.8.3.Final</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>amazon-kinesis-client</artifactId>
<version>1.9.0</version>
</dependency>
...配置嵌入式引擎
Debezium 嵌入式引擎通过 io.debezium.config.Configuration 实例进行配置。此类可以从系统属性或给定的配置文件获取值,但为了示例的方便,我们将仅通过其流畅的构建器 API 传递所有必需的值。
Configuration config = Configuration.create()
.with(EmbeddedEngine.CONNECTOR_CLASS, "io.debezium.connector.mysql.MySqlConnector")
.with(EmbeddedEngine.ENGINE_NAME, "kinesis")
.with(MySqlConnectorConfig.SERVER_NAME, "kinesis")
.with(MySqlConnectorConfig.SERVER_ID, 8192)
.with(MySqlConnectorConfig.HOSTNAME, "localhost")
.with(MySqlConnectorConfig.PORT, 3306)
.with(MySqlConnectorConfig.USER, "debezium")
.with(MySqlConnectorConfig.PASSWORD, "dbz")
.with(MySqlConnectorConfig.DATABASE_WHITELIST, "inventory")
.with(MySqlConnectorConfig.TABLE_WHITELIST, "inventory.customers")
.with(EmbeddedEngine.OFFSET_STORAGE,
"org.apache.kafka.connect.storage.MemoryOffsetBackingStore")
.with(MySqlConnectorConfig.DATABASE_HISTORY,
MemoryDatabaseHistory.class.getName())
.with("schemas.enable", false)
.build();如果您之前在 Kafka Connect 中设置过 Debezium MySQL 连接器,那么大多数属性看起来都会很熟悉。
但是,让我们更详细地讨论 OFFSET_STORAGE 和 DATABASE_HISTORY 选项。它们涉及连接器偏移量和数据库历史记录的持久化方式。当通过 Kafka Connect 运行连接器时,两者通常会存储在特定的 Kafka 主题中。但在这里这不是一个选项,因此需要替代方案。在此示例中,我们将仅在内存中保留偏移量和数据库历史记录。也就是说,如果引擎重新启动,这些信息将丢失,并且连接器将从头开始,例如,从新的初始快照开始。
虽然这超出了本博客文章的范围,但创建 OffsetBackingStore 和 DatabaseHistory 合约的替代实现并不难。例如,如果您完全投入 AWS 云服务,则可以考虑将偏移量和数据库历史记录存储在 DynamoDB NoSQL 存储中。请注意,与 Kafka 不同,Kinesis 流不适合存储数据库历史记录。原因是 Kinesis 数据流的最大保留期为七天,而数据库历史记录必须在连接器的整个生命周期内保留。另一种替代方案是分别使用基于文件系统的现有实现 FileOffsetBackingStore 和 FileDatabaseHistory。
下一步是从配置构建 EmbeddedEngine 实例。同样,这可以通过流畅的 API 完成。
EmbeddedEngine engine = EmbeddedEngine.create()
.using(config)
.using(this.getClass().getClassLoader())
.using(Clock.SYSTEM)
.notifying(this::sendRecord)
.build();这里最有趣的部分是 notifying 调用。这里传递的方法将由引擎为每个发出的数据更改记录调用。因此,让我们看看该方法的实现。
将更改记录发送到 Kinesis
sendRecord() 方法是实现魔力的地方。我们将把传入的 SourceRecord 转换为等效的 JSON 表示形式,并将其传播到 Kinesis 流。
为此,理解 Apache Kafka 和 Kinesis 之间的一些概念差异非常重要。具体来说,Kafka 中的消息具有一个键和一个值(两者都是任意字节数组)。对于 Debezium,数据更改事件的键代表受影响记录的主键,而值是包含旧行和新行状态以及一些附加元数据的结构。
另一方面,Kinesis 中的消息包含一个数据 blob(同样是任意字节序列)和一个分区键。Kinesis 流可以分成多个分片,分区键用于确定给定的消息应进入哪个分片。
现在,人们可能会考虑将 Debezium 更改数据事件中的键映射到 Kinesis 分区键,但分区键的长度限制为 256 字节。根据捕获表中主键列的长度,这可能不够。因此,一个更安全的选择是为更改消息键创建哈希值,并将其用作分区键。这反过来意味着更改消息键结构应与实际值一起添加到 Kinesis 消息的数据 blob 中。虽然键列值本身也包含在值结构中,但否则使用者将不知道哪些列构成了主键。
考虑到这一点,让我们看看 sendRecord() 的实现。
private void sendRecord(SourceRecord record) {
// We are interested only in data events not schema change events
if (record.topic().equals("kinesis")) {
return;
}
// create schema for container with key *and* value
Schema schema = SchemaBuilder.struct()
.field("key", record.keySchema())
.field("value", record.valueSchema())
.build();
Struct message = new Struct(schema);
message.put("key", record.key());
message.put("value", record.value());
// create partition key by hashing the record's key
String partitionKey = String.valueOf(
record.key() != null ? record.key().hashCode() : -1);
// create data blob representing the container by using Kafka Connect's
// JSON converter
final byte[] payload = valueConverter.fromConnectData(
"dummy", schema, message);
// Assemble the put-record request ...
PutRecordRequest putRecord = new PutRecordRequest();
putRecord.setStreamName(record.topic());
putRecord.setPartitionKey(partitionKey);
putRecord.setData(ByteBuffer.wrap(payload));
// ... and execute it
kinesisClient.putRecord(putRecord);
}代码相当直接;如上所述,它首先创建一个包含传入源记录的键和值的容器结构。然后使用 Kafka Connect 提供的 JSON 转换器(JsonConverter 的实例)将此结构转换为二进制表示形式。然后,根据此 blob、分区键和更改记录的主题名称组装一个 PutRecordRequest,最终将其发送到 Kinesis。
Kinesis 客户端对象可以重用,并且设置一次如下所示。
// Uses the credentials from the local "default" AWS profile
AWSCredentialsProvider credentialsProvider =
new ProfileCredentialsProvider("default");
this.kinesisClient = AmazonKinesisClientBuilder.standard()
.withCredentials(credentialsProvider)
.withRegion("eu-central-1") // use your AWS region here
.build();至此,我们已经设置了 Debezium 的 EmbeddedEngine 实例,该实例运行配置的 MySQL 连接器并将每个发出的更改事件传递到 Amazon Kinesis。最后遗漏的步骤是实际运行引擎。这可以通过使用 Executor 在单独的线程上完成,例如如下所示。
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);请注意,您还应确保最终正确关闭引擎。如何在debezium-examples 仓库中的配套示例 中展示。
运行示例
最后,让我们看看如何运行完整示例并从 Kinesis 流中消费 Debezium CDC 事件。首先克隆示例仓库并进入kinesis 目录。
git clone https://github.com/debezium/debezium-examples.git
cd debezium-examples/kinesis确保您已满足示例README.md 中描述的先决条件;最重要的是,您应该有一个本地 Docker 安装,并且需要设置 AWS 帐户并安装 AWS 客户端工具。请注意,Kinesis 不包含在注册 AWS 时提供的免费套餐中,也就是说,在执行示例时您需要支付(少量)费用。完成后不要忘记删除您设置的流,我们不会支付您的 AWS 账单 :)
现在运行 Debezium 的 MySQL 示例数据库,以便有一些数据可供使用。
docker run -it --rm --name mysql -p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=debezium \
-e MYSQL_USER=mysqluser \
-e MYSQL_PASSWORD=mysqlpw \
debezium/example-mysql:0.8创建一个 Kinesis 流来捕获来自 customers 表的更改事件。
aws kinesis create-stream --stream-name kinesis.inventory.customers \
--shard-count 1执行运行 Debezium 嵌入式引擎的 Java 应用程序(如果需要,请先在 pom.xml 中调整 kinesis.region 属性的值为您自己的区域)。
mvn exec:java这将启动引擎和 MySQL 连接器,它将对捕获的数据库进行初始快照。
为了查看 Kinesis 流中的 CDC 事件,可以使用 AWS CLI(通常,您将实现一个 Kinesis Streams 应用程序来消费事件)。为此,请先设置一个 分片迭代器。
ITERATOR=$(aws kinesis get-shard-iterator --stream-name kinesis.inventory.customers --shard-id 0 --shard-iterator-type TRIM_HORIZON | jq '.ShardIterator')注意如何使用 jq 工具从 Kinesis API 返回的 JSON 结构中获取迭代器的生成 ID。接下来,可以使用该迭代器检查流。
aws kinesis get-records --shard-iterator $ITERATOR您应该收到一个类似这样的记录数组。
{
"Records": [
{
"SequenceNumber":
"49587760482547027816046765529422807492446419903410339842",
"ApproximateArrivalTimestamp": 1535551896.475,
"Data": "eyJiZWZvcm...4OTI3MzN9",
"PartitionKey": "eyJpZCI6MTAwMX0="
},
...
]
}Data 元素是消息数据 blob 的 Base64 编码表示。再次使用 jq 会很方便:我们可以使用它来提取每条记录的 Data 部分并解码 Base64 表示(确保使用 jq 1.6 或更高版本)。
aws kinesis get-records --shard-iterator $ITERATOR | \
jq -r '.Records[].Data | @base64d' | jq .现在您应该看到 JSON 格式的更改事件,每个事件都带有键和值。
{
"key": {
"id": 1001
},
"value": {
"before": null,
"after": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "0.8.1.Final",
"name": "kinesis",
"server_id": 0,
"ts_sec": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"snapshot": true,
"thread": null,
"db": "inventory",
"table": "customers",
"query": null
},
"op": "c",
"ts_ms": 1535555325628
}
}
...接下来,让我们尝试更新 MySQL 中的一条记录。
# Start MySQL CLI client
docker run -it --rm --name mysqlterm --link mysql --rm mysql:5.7 \
sh -c 'exec mysql -h"$MYSQL_PORT_3306_TCP_ADDR" \
-P"$MYSQL_PORT_3306_TCP_PORT" -uroot -p"$MYSQL_ENV_MYSQL_ROOT_PASSWORD"'
# In the MySQL client
use inventory;
update customers set first_name = 'Trudy' where id = 1001;如果您现在再次获取迭代器,您应该会看到一条代表该更新的额外数据更改事件。
...
{
"key": {
"id": 1001
},
"value": {
"before": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"after": {
"id": 1001,
"first_name": "Trudy",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "0.8.1.Final",
"name": "kinesis",
"server_id": 223344,
"ts_sec": 1535627629,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 364,
"row": 0,
"snapshot": false,
"thread": 10,
"db": "inventory",
"table": "customers",
"query": null
},
"op": "u",
"ts_ms": 1535627622546
}
}完成后,通过按 Ctrl + C 停止嵌入式引擎应用程序,通过运行 docker stop mysql 停止 MySQL 服务器,并删除 Kinesis 中的 kinesis.inventory.customers 流。
总结和展望
在这篇博客文章中,我们展示了 Debezium 不仅可以用于将数据更改流式传输到 Apache Kafka,还可以流式传输到 Amazon Kinesis 等其他流式传输平台。利用其嵌入式引擎并实现一些粘合代码,您可以受益于 Debezium 提供的所有 CDC 连接器及其功能,并将它们连接到您选择的流式传输解决方案。
我们正在考虑进一步简化 Debezium 的使用。我们正在考虑提供一个小型独立的 Debezium 运行时,您可以直接执行它,而不是要求您实现自己的应用程序来调用嵌入式引擎 API。它将配置要运行的源连接器,并利用具有 Kinesis、Apache Pulsar 等现成实现的 outbound 插件 SPI。当然,这样的运行时还将为安全地持久化偏移量和数据库历史记录提供合适的实现,并提供监控、健康检查等手段。这意味着您可以以健壮可靠的方式将 Debezium 源连接器连接到您首选的流式传输平台,而无需手动编码!
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。