
基于微服务的架构可以被视为一种行业趋势,因此最近在企业应用程序中经常出现。保持多个服务及其后端数据存储之间数据同步的一种可能方法是采用一种称为更改数据捕获(简称 CDC)的方法。
本质上,CDC 允许监听数据流的一端(即数据源)发生的任何修改,并将它们作为变更事件通信给其他感兴趣的方,或存储到数据接收器。与其以点对点的方式进行,不如建议解耦数据源和数据接收器之间的事件流。可以使用 Debezium 和 Apache Kafka 基于此场景实现,并且相对容易,几乎不需要编写代码。
例如,考虑订单管理系统的以下基于微服务的架构
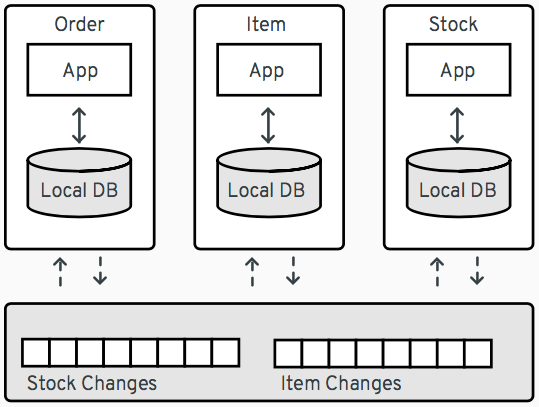
该系统包含三个服务:Order、Item 和 Stock。如果 Order 服务收到订单请求,它将需要来自其他两个服务的信息,例如项目定义或特定项目的库存数量。与其通过同步调用这些服务来获取此信息,不如使用 CDC 来为 Item 和 Stock 服务管理的数据设置变更事件流。Order 服务可以订阅这些事件流,并在自己的数据库中保留相关项目和库存数据的本地副本。这种方法有助于解耦服务(例如,不受服务中断的直接影响),并且也有益于整体性能,因为每个服务都可以仅保留其他服务中它感兴趣的数据项的优化视图。
如何处理聚合对象?
然而,有些用例比较棘手。有时通过所谓的聚合(领域驱动设计 (DDD) 定义的概念/模式)在服务和数据存储之间共享信息非常有用。总的来说,DDD 聚合用于传输状态,这些状态可能包含多个不同的域对象,它们共同被视为单一的信息单元。
具体示例如下:
-
客户及其地址,表示为一个客户记录聚合,存储客户信息和地址列表。
-
订单及其对应的行项目,表示为一个订单记录聚合,存储订单信息及其所有行项目。
很可能支持这些 DDD 聚合的域对象的数据存储在 RDBMS 的单独关系中。在使用 Debezium 当前提供的 CDC 功能时,所有对域对象的更改都将被独立捕获,并且默认最终会反映在单独的 Kafka 主题中,每个 RDBMS 关系对应一个主题。虽然这种行为对许多用例非常有帮助,但对其他用例(例如上面描述的 DDD 聚合场景)可能非常有限。因此,这篇博文将探讨如何基于 Debezium CDC 事件,使用 Kafka Streams API 构建 DDD 聚合。
从数据源捕获变更事件
这篇博文的完整源代码在 GitHub 上的 Debezium 示例仓库中提供。首先克隆此仓库并进入 kstreams 目录。
git clone https://github.com/debezium/debezium-examples.git
cd kstreams该项目提供了一个 Docker Compose 文件,其中包含您可能已经从 Debezium 教程中了解过的所有组件的服务:
-
一个包含 Debezium CDC 连接器的 Kafka Connect 实例
-
MySQL(已填充一些测试数据)
此外,它还声明了以下服务:
-
MongoDB,将用作数据接收器
-
另一个 Kafka Connect 实例,将托管 MongoDB 接收器连接器
-
我们将要构建的 DDD 聚合过程的服务
我们将在稍后讨论这三个服务。现在,让我们准备好管道的源端。
export DEBEZIUM_VERSION=0.7
docker-compose up mysql zookeeper kafka connect_source一旦所有服务都启动起来,就可以通过提交以下 JSON 文档来注册 Debezium MySQL 连接器实例。
{
"name": "mysql-source",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"table.whitelist": "inventory.customers,inventory.addresses",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"transforms": "unwrap",
"transforms.unwrap.type":"io.debezium.transforms.UnwrapFromEnvelope",
"transforms.unwrap.drop.tombstones":"false"
}
}为此,请运行以下 curl 命令:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" https://:8083/connectors/ -d @mysql-source.json这会为指定的数据库设置连接器,使用给定的凭据。对于我们的目的,我们只对 customers 和 addresses 表的更改感兴趣,因此 table.whitelist 属性被设置为仅选择这两个表。另一个值得注意的地方是应用的“解包”转换。默认情况下,Debezium 的 CDC 事件将包含已更改行的旧状态和新状态以及有关更改源的其他元数据。通过应用 UnwrapFromEnvelope SMT(单条消息转换),只有新状态才会被传播到相应的 Kafka 主题。
一旦连接器部署完成并完成了对两个捕获表的初始快照,我们就可以查看它们了。
docker-compose exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.customers # or dbserver1.inventory.addresses例如,您应该看到以下输出:
(为了便于阅读,已格式化并省略了模式信息)关于客户变更的主题:
{
"schema": { ... },
"payload": {
"id": 1001
}
}
{
"schema": { ... },
"payload": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
}
}
...构建 DDD 聚合
KStreams 应用程序将处理来自两个 Kafka 主题的数据。这些主题接收基于 MySQL 中的 customers 和 addresses 关系的 CDC 事件,每个主题都有其对应的 Jackson 注解的 POJO(Customer 和 Address),并包含一个持有 CDC 事件类型(即 UPSERT/DELETE)的字段。
由于 Kafka 主题记录是 Debezium JSON 格式,并且具有解包的信封,因此已编写了一个特殊的 SerDe,以便能够使用其 POJO 或 Debezium 事件表示来读/写这些记录。序列化器只是使用 Jackson 将 POJO 转换为 JSON,而反序列化器是“混合”的,能够从 Debezium CDC 事件或 JSON 化 POJO 进行反序列化。
有了这个前提,就可以如下构建用于实时创建和维护 DDD 聚合的 KStreams 拓扑:
Customers 主题(“父”)
所有客户记录只是从 customers 主题读取到 KTable 中,该 KTable 将根据记录键(即客户的 PK)自动维护每个客户的最新状态。
KTable<DefaultId, Customer> customerTable =
builder.table(parentTopic, Consumed.with(defaultIdSerde,customerSerde));Addresses 主题(“子”)
对于地址记录,处理过程更复杂,需要几个步骤。首先,所有地址记录被读取到一个 KStream 中。
KStream<DefaultId, Address> addressStream = builder.stream(childrenTopic,
Consumed.with(defaultIdSerde, addressSerde));其次,基于地址记录的键(关系中的原始主键)对这些地址记录进行“伪”分组。在此步骤中,将维护与相应客户记录的关系。这有效地允许跟踪哪个地址记录属于哪个客户记录,即使在地址记录删除的情况下也是如此。为此,引入了一个额外的 LatestAddress POJO,它除了Address 记录本身外,还可以存储最新的已知 PK <-> FK 关系。
KTable<DefaultId,LatestAddress> tempTable = addressStream
.groupByKey(Serialized.with(defaultIdSerde, addressSerde))
.aggregate(
() -> new LatestAddress(),
(DefaultId addressId, Address address, LatestAddress latest) -> {
latest.update(
address, addressId, new DefaultId(address.getCustomer_id()));
return latest;
},
Materialized.<DefaultId,LatestAddress,KeyValueStore<Bytes, byte[]>>
as(childrenTopic+"_table_temp")
.withKeySerde(defaultIdSerde)
.withValueSerde(latestAddressSerde)
);第三,中间 KTable 再次转换为 KStream。LatestAddress 记录被转换为以客户 ID(FK 关系)作为新键,以便按客户进行分组。在分组过程中,会更新特定于客户的地址,这可能导致添加或删除地址记录。为此,引入了另一个名为 Addresses 的 POJO,它包含一个地址记录的映射,该映射会相应地更新。结果是一个 KTable,其中包含每个客户 ID 的最新Addresses。
KTable<DefaultId, Addresses> addressTable = tempTable.toStream()
.map((addressId, latestAddress) ->
new KeyValue<>(latestAddress.getCustomerId(),latestAddress))
.groupByKey(Serialized.with(defaultIdSerde,latestAddressSerde))
.aggregate(
() -> new Addresses(),
(customerId, latestAddress, addresses) -> {
addresses.update(latestAddress);
return addresses;
},
Materialized.<DefaultId,Addresses,KeyValueStore<Bytes, byte[]>>
as(childrenTopic+"_table_aggregate")
.withKeySerde(defaultIdSerde)
.withValueSerde(addressesSerde)
);组合客户和地址
最后,可以通过连接 customers KTable 和 addresses KTable 将客户和地址轻松地组合起来,从而构建由 CustomerAddressAggregate POJO 表示的 DDD 聚合。最后,KTable 的更改被写入 KStream,然后保存到 Kafka 主题中。这使得 DDD 聚合的结果可以以多种方式使用。
KTable<DefaultId,CustomerAddressAggregate> dddAggregate =
customerTable.join(addressTable, (customer, addresses) ->
customer.get_eventType() == EventType.DELETE ?
null :
new CustomerAddressAggregate(customer,addresses.getEntries())
);
dddAggregate.toStream().to("final_ddd_aggregates",
Produced.with(defaultIdSerde,(Serde)aggregateSerde));| Customers KTable 中的记录可能会收到 CDC 删除事件。如果是这样,可以通过检查客户 POJO 的事件类型字段来检测,并例如返回“null”而不是 DDD 聚合。当消耗方也需要相应地处理删除时,这种约定会很有帮助。 |
运行聚合管道
实现了聚合管道后,是时候进行测试了。为此,构建包含完整实现的 poc-ddd-aggregates Maven 项目。
mvn clean package -f poc-ddd-aggregates/pom.xml然后从 Compose 文件运行 aggregator 服务,该服务使用此项目构建的 JAR,并使用 java-jboss-openjdk8-jdk 基础镜像启动它。
docker-compose up -d aggregator一旦聚合管道正在运行,我们就可以使用控制台消费者查看聚合后的事件。
docker-compose exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic final_ddd_aggregates将 DDD 聚合传输到数据接收器
我们最初的目标是构建这些 DDD 聚合,以便在数据源(此处为 MySQL 表)和便捷的数据接收器之间传输数据和同步更改。根据定义,DDD 聚合通常是复杂的数据结构,因此将其写入提供灵活查询和/或索引方式的数据存储非常合理。谈到 NoSQL 数据库,文档存储似乎是最自然的选择,MongoDB 是此类用例的领先数据库。
得益于 Kafka Connect 和众多即用型连接器,这几乎毫不费力。使用开源社区的MongoDB 接收器连接器,可以轻松地将 DDD 聚合写入 MongoDB。只需进行适当的配置,然后将其发布到 Kafka Connect 的REST API 即可运行连接器。
因此,让我们启动 MongoDB 和另一个用于托管接收器连接器的 Kafka Connect 实例。
docker-compose up -d mongodb connect_sink如果 DDD 聚合需要未修改地写入 MongoDB,配置可能非常简单,如下所示:
{
"name": "mongodb-sink",
"config": {
"connector.class": "at.grahsl.kafka.connect.mongodb.MongoDbSinkConnector",
"tasks.max": "1",
"topics": "final_ddd_aggregates",
"mongodb.connection.uri": "mongodb://mongodb:27017/inventory?w=1&journal=true",
"mongodb.collection": "customers_with_addresses",
"mongodb.document.id.strategy": "at.grahsl.kafka.connect.mongodb.processor.id.strategy.FullKeyStrategy",
"mongodb.delete.on.null.values": true
}
}与源连接器一样,使用 curl 部署连接器。
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" https://:8084/connectors/ -d @mongodb-sink.json此连接器将从“final_ddd_aggregates”Kafka 主题中读取消息,并将它们作为 MongoDB 文档写入“customers_with_addresses”集合。
您可以通过启动 Mongo shell 并查询集合的内容来查看。
docker-compose exec mongodb bash -c 'mongo inventory'
> db.customers_with_addresses.find().pretty(){
"_id": {
"id": "1001"
},
"addresses": [
{
"zip": "76036",
"_eventType": "UPSERT",
"city": "Euless",
"street": "3183 Moore Avenue",
"id": "10",
"state": "Texas",
"customer_id": "1001",
"type": "SHIPPING"
},
{
"zip": "17116",
"_eventType": "UPSERT",
"city": "Harrisburg",
"street": "2389 Hidden Valley Road",
"id": "11",
"state": "Pennsylvania",
"customer_id": "1001",
"type": "BILLING"
}
],
"customer": {
"_eventType": "UPSERT",
"last_name": "Thomas",
"id": "1001",
"first_name": "Sally",
"email": "sally.thomas@acme.com"
}
}由于数据组合在单个文档中,某些部分可能不需要或冗余。为了摆脱任何不需要的数据(例如,每个地址子文档的 _eventType、customer_id),也可以调整配置以将上述字段列入黑名单。
最后,您在 MySQL 源数据库中更新了一些客户或地址数据。
docker-compose exec mysql bash -c 'mysql -u $MYSQL_USER -p$MYSQL_PASSWORD inventory'
mysql> update customers set first_name= "Sarah" where id = 1001;稍后,您应该会看到 MongoDB 中的相应聚合文档已相应更新。
缺点和局限性
虽然这个基于表级 CDC 事件创建 DDD 聚合的第一个版本基本可用,但了解其当前的局限性非常重要:
-
不具有通用性,因此需要为 POJO 和中间类型编写自定义代码。
-
由于缺少必要的数据预分区处理,因此无法跨多个实例进行扩展。
-
仅限于基于 1:N 关系的单个 JOIN 构建聚合。
-
生成的 DDD 聚合是最终一致的,这意味着它们可能在收敛之前暂时表现出中间状态。
前几个问题可以通过在 KStreams 应用程序上进行合理的工作来解决。最后一个问题,即处理生成的 DDD 聚合的最终一致性,要困难得多,需要对 Debezium 自己的 CDC 机制进行一些努力。
展望
在这篇文章中,我们描述了一种从 Debezium 的 CDC 事件创建聚合事件的方法。在后续的博文中,我们可能会更深入地探讨如何通过运行多个 KStreams 聚合实例来实现 DDD 的水平扩展。为此,需要在运行拓扑之前对数据进行适当的分区。此外,研究一个更通用的版本可能很有趣,该版本只需要自定义类来描述两个主要的 POJO。
我们也考虑提供一个现成的组件,它可以通用工作(基于 Connect 记录,即不绑定到特定的序列化格式,如 JSON),并且可以设置为可配置的独立进程来运行给定的聚合。
关于处理最终一致性,我们也获得了一些想法,但这些肯定需要更多的探索和调查。敬请关注!
我们很乐意听取您关于事件聚合主题的反馈。如果您对此主题有任何想法或意见,请通过在下方发表评论或向我们的邮件列表发送消息来与我们联系。


关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。