
本文最初发表在 WePay Engineering 博客。
如果您想知道为什么要在 Kafka 中流式传输数据库更改,我强烈建议您阅读 微服务最难的部分:您的数据。在 WePay,我们希望集成我们的微服务和下游数据存储,以便每个系统都能访问它所需的数据。我们将 Kafka 用作数据集成层,因此我们需要一种方法将我们的数据库数据导入其中。
去年,Yelp 工程团队发布了一系列关于他们数据管道的优秀博文。其中包括一篇关于他们如何将 MySQL 数据流式传输到 Kafka的讨论。他们的架构涉及一系列自研软件来完成任务,特别是schematizer和MySQL streamer。这篇博文引发了 Debezium 博客上一篇关于使用 Kafka Connect、Debezium 和 Confluent Schema Registry 的等效架构提议的深思熟虑的帖子。这个提议的架构是我们一直在 WePay 实现的,这篇博文将介绍我们如何利用 Debezium 和 Kafka Connect 将我们的 MySQL 数据库流式传输到 Kafka。
架构
数据流始于每个微服务的 MySQL 数据库。这些数据库在 Google Cloud 中作为 CloudSQL MySQL 实例运行,并启用了 GTID。我们设置了一个专供 Debezium 使用的下游 MySQL 集群。每个 CloudSQL 实例将其数据复制到 Debezium 集群,该集群由两台 MySQL 服务器组成:一个主(活动)服务器和一个辅助(被动)服务器。这个单一的 Debezium 集群是一个操作技巧,可以让我们更轻松地操作 Debezium。与其让 Debezium 直接连接到数十个微服务数据库,不如我们只需连接到一个数据库。这还将 Debezium 与主 CloudSQL 实例正在处理的生产 OLTP 工作负载隔离开来。
我们为每个微服务数据库运行一个 Debezium 连接器(在 Kafka Connect 框架的分布式模式下)。这里的目标仍然是隔离。理论上,我们可以运行一个 Debezium 连接器,为所有数据库生成消息(因为所有微服务数据库都在 Debezium 集群中)。这种方法实际上资源效率更高,因为每个 Debezium 连接器都需要读取 MySQL 的整个二进制日志。我们选择不这样做,因为我们希望能够独立地启动和停止 Debezium 连接器,并为每个微服务数据库配置不同的连接器。
Debezium 连接器将 MySQL 消息馈送到 Kafka(并将其模式添加到 Confluent Schema Registry),下游系统可以从中消费。我们使用我们的 Kafka Connect BigQuery 连接器,使用 BigQuery 的流式 API将 MySQL 数据加载到 BigQuery 中。这使我们拥有一个 BigQuery 数据仓库,其数据延迟通常小于 30 秒。其他微服务、流处理器和数据基础设施也会消费这些数据流。
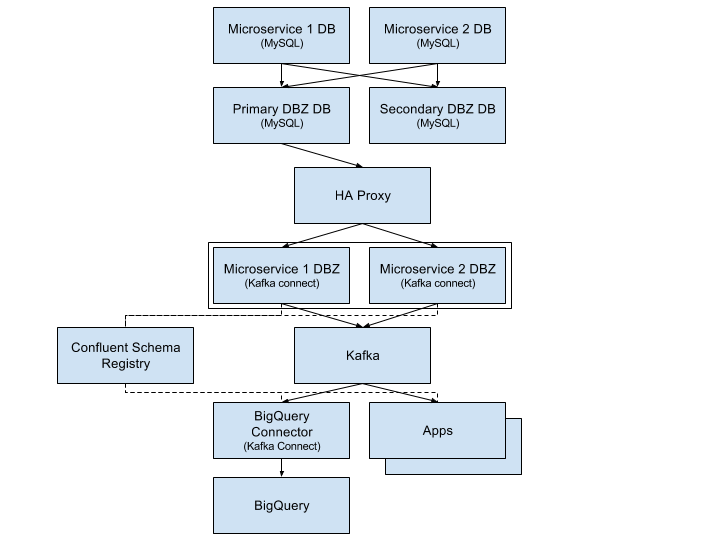
Debezium
本文的其余部分将重点介绍 Debezium(上图中的 DBZ 方框),以及我们如何配置和操作它。Debezium 的工作原理是连接到 MySQL 并假装是一个副本。MySQL 将其复制数据发送给 Debezium,认为它实际上是在将数据传送到另一个下游 MySQL 实例。然后 Debezium 接收数据,将模式从 MySQL 模式转换为 Kafka Connect 结构,并将其转发到 Kafka。
添加新数据库
当一个新的带有 CloudSQL 数据库的微服务上线时,我们希望将该数据加载到 Kafka 中。这个过程的第一步是将数据加载到 Debezium MySQL 集群。这涉及几个步骤:
-
对微服务数据库中的数据执行 MySQL 转储。
-
暂停辅助 Debezium MySQL 数据库。
-
将 MySQL 转储加载到辅助 Debezium MySQL 数据库。
-
重置
GTID_PURGED参数,使其包含新数据库转储的 GTID。 -
取消暂停辅助 Debezium MySQL 数据库。
-
更新 HA Proxy 指向辅助服务器,它现在将成为主服务器。
-
对旧的主实例(现在是辅助实例)执行步骤 2-5。
我们运行的实际命令是
# (1) Take a dump of the database we wish to add.
$ mydumper --host=123.123.123.123 --port=3306 --user=foo --password=********* -B log --trx-consistency-only --triggers --routines -o /mysqldata/new_db/ -c -L mydumper.log
# (2) Stop all replication on the secondary Debezium cluster.
$ mysql> STOP SLAVE for channel 'foo';
$ mysql> STOP SLAVE for channel 'bar';
$ mysql> STOP SLAVE for channel 'baz';
# Get the current GTID purged values from MySQL.
$ mysql> SHOW GLOBAL VARIABLES like '%gtid_purged%';
# (3) Load the dump of the database into the Debezium cluster.
$ myloader -d /mysqldata/new_db/ -s new_db
# (4) Clear out existing GTID_PURGED values so that we can overwrite it to include the GTID from the new dump file.
$ mysql> reset master;
# Set the new GTID_PURGED value, including the GTID_PURGED value from the MySQL dump file.
$ mysql> set global GTID_PURGED="f3a44d1a-11e6-44ba-bf12-040bab830af0:1-10752,c627b2bc-b36a-11e6-a886-42010af00790:1-9052,01261abc3-6ade-11e6-9647-42010af0044a:1-375342";
# (5) Start replication for the new DB.
$ mysql> CHANGE MASTER TO MASTER_HOST='123.123.123.123', MASTER_USER='REPLICATION_USER', MASTER_PASSWORD='REPLICATION_PASSWORD',MASTER_AUTO_POSITION=1 for CHANNEL 'new_db';
$ mysql> START SLAVE for channel 'new_db';
# Start replication for the DBs that we paused.
$ mysql> START SLAVE for channel 'foo';
$ mysql> START SLAVE for channel 'bar';
$ mysql> START SLAVE for channel 'baz';
# Repeat steps 2-5 on the old primary (now secondary).完成这些步骤后,主服务器和辅助服务器 Debezium MySQL 都将拥有新数据库。完成后,我们可以将一个新的 Debezium 连接器添加到 Kafka Connect 集群。此连接器的配置大致如下:
{
"name": "debezium-connector-microservice1",
"config": {
"name": "debezium-connector-microservice1",
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "dbz-mysql01",
"database.port": "3306",
"database.user": "user",
"database.password": "*******",
"database.server.id": "101",
"database.server.name": "db.debezium.microservice1",
"gtid.source.includes": "c34aeb9e-89ad-11e6-877b-42010a93af2d",
"database.whitelist": "microservice1_db",
"poll.interval.ms": "2",
"table.whitelist": "microservice1_db.table1,microservice1_db.table2",
"column.truncate.to.1024.chars" : "microservice1_db.table1.text_col",
"database.history.kafka.bootstrap.servers": "kafka01:9093,kafka02:9093,kafka03:9093",
"database.history.kafka.topic": "debezium.history.microservice1",
"database.ssl.truststore": "/certs/truststore",
"database.ssl.truststore.password": "*******",
"database.ssl.mode": "required",
"database.history.producer.security.protocol": "SSL",
"database.history.producer.ssl.truststore.location": "/certs/truststore",
"database.history.producer.ssl.truststore.password": "*******",
"database.history.consumer.security.protocol": "SSL",
"database.history.consumer.ssl.truststore.location": "/certs/truststore",
"database.history.consumer.ssl.truststore.password": "*******",
}
}这些配置字段的详细信息可以在 此处找到。
新连接器将启动并开始快照数据库,因为这是它第一次启动。Debezium 的快照实现(参见 DBZ-31)使用与 MySQL 的 mysqldump 工具非常相似的方法。快照完成后,Debezium 将切换到使用 MySQL 的二进制日志来接收所有未来的数据库更新。
Kafka Connect 和 Debezium 协同工作,定期提交 Debezium 在 MySQL 二进制日志中的位置,该位置由MySQL 全局事务 ID (GTID) 描述。当 Debezium 重启时,Kafka Connect 会提供最后提交的 MySQL GTID,Debezium 将从那里恢复。(与上述相同的前提:由于提交频率是周期性的,您可能会看到一些重复的消息)。
请注意,提交只发生一次,因此 Debezium 可能会从日志中早于它接收到的最后一行记录的位置重新启动。在这种情况下,您将在 Debezium Kafka 主题中看到重复的消息。Debezium 以“至少一次”消息传递保证将消息写入 Kafka。
高可用性
我们最初使用 Debezium 时面临的一个挑战是如何使其容忍机器故障(包括上游 MySQL 服务器和 Debezium 本身)。在 5.6 版本之前的 MySQL 中,它使用(二进制日志文件名,文件偏移量)元组来建模副本在其父二进制日志中的位置。这种方法的问题是二进制日志文件名在 MySQL 机器之间不相同。这意味着从上游 MySQL 机器 1 读取的副本无法轻松故障转移到 MySQL 机器 2。有一个完整的工具生态系统(包括MHA)试图解决这个问题。
从 MySQL 5.6 开始,MySQL 引入了全局事务 ID 的概念。这些 GTID 在跨机器的 MySQL 二进制日志中标识一个特定位置。这意味着从一台 MySQL 服务器上的二进制日志读取的消费者可以切换到另一台,前提是两台服务器都提供了数据。这就是我们运行系统的方式。CloudSQL 实例和 Debezium MySQL 集群都启用了 GTID。Debezium MySQL 服务器还启用了复制二进制日志,以便存在 Debezium 可以读取的二进制日志(副本默认情况下通常不会启用二进制日志)。所有这些都使得 Debezium 能够从主 Debezium MySQL 服务器消费,但在发生故障时可以通过 HA Proxy 切换到辅助服务器。
如果 Debezium 本身运行的机器发生故障,Kafka Connect 框架会将连接器故障转移到集群中的另一台机器。当发生故障转移时,Debezium 会从 Kafka Connect 接收其最后提交的偏移量 (GTID),并从它上次停止的地方继续(与上述相同的注意事项:由于提交频率是周期性的,您可能会看到一些重复的消息)。
需要特别指出一个重要的配置是 gtid.source.includes 字段,我们上面已经设置了。当我们最初设置架构部分描述的拓扑时,我们发现即使主 Debezium 数据库和辅助数据库复制完全相同的数据,我们也无法从主 Debezium 数据库故障转移到辅助数据库。这是因为,除了主辅助机器都复制的各种上游数据库的 GTID 外,每台机器还有其各自 MySQL 数据库(例如 information_schema)的服务器 UUID。这两台服务器中存在不同的 UUID 导致 MySQL 在我们触发故障转移时感到困惑,因为 Debezium 的 GTID 将包含主服务器的服务器 UUID,而辅助服务器并不知道该 UUID。修复方法是从 GTID 中过滤掉我们不关心的所有 UUID。每个 Debezium 连接器会过滤掉除其关心的微服务数据库的 UUID 之外的所有服务器 UUID。这使得连接器能够无缝地从主服务器故障转移到辅助服务器。此问题在 DBZ-129 中有详细记录。
模式
Debezium 的消息格式同时包含行的“之前”和“之后”版本。对于插入,"之前"为 null。对于删除,"之后"为 null。更新字段会同时填充“之前”和“之后”字段。消息还包括一些服务器信息,例如消息来自的服务器 ID、消息的 GTID、服务器时间戳等。
{
"before": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"name": "mysql-server-1",
"server_id": 223344,
"ts_sec": 1465581,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 484,
"row": 0,
"snapshot": null
},
"op": "u",
"ts_ms": 1465581029523
}Debezium 发送到 Kafka 的序列化格式是可配置的。我们在 WePay 更喜欢 Avro,因为它体积小巧、模式 DDL、性能好且生态系统丰富。我们将 Kafka Connect 配置为使用 Confluent 的 Avro 编码器编解码器。此编码器将消息序列化为 Avro,同时还将模式注册到 Confluent Schema Registry。
如果 MySQL 表的模式发生更改,Debezium 会通过更新其事件消息的“之前”和“之后”部分中的结构和模式来适应更改。这在 Avro 编码器看来将是一个新模式,它将在消息发送到 Kafka 之前将其注册到 Schema Registry。Registry 会运行完整的兼容性检查,以确保下游消费者不会因模式演变而中断。
请注意,仍然有可能在 MySQL 模式本身中进行不兼容的更改,这将破坏下游消费者。我们尚未为 MySQL 表的 ALTER 命令添加自动兼容性检查。
未来工作
单体数据库
除了我们的微服务之外,我们还有一个比我们的微服务数据库大得多的遗留单体数据库。我们正在升级该集群以支持 GTID。完成此操作后,我们计划将此集群也复制到 Kafka 中,使用 Debezium。
大表快照
我们很幸运,我们所有的微服务数据库都相对易于管理。我们的单体数据库中有一些表要大得多。我们尚未测试 Debezium 与非常大的表,因此尚不清楚是否需要进行任何调整或补丁才能在初始 Debezium 加载时快照这些表。我们已收到社区报告,称较大的表(60 亿+ 行)确实可以正常工作,前提是设置了 DBZ-152 中公开的配置。这是我们计划在不久的将来进行的工作。
更多监控
Kafka Connect 目前无法轻松地通过 Kafka 指标框架公开指标。因此,Kafka Connect 框架提供的指标非常少。Debezium 通过 JMX 公开指标(参见 DBZ-134),但我们目前并未将其公开到我们的指标系统中。我们确实监控系统,但当出现问题时,很难确定发生了什么。KAFKA-2376 是旨在解决底层 Kafka Connect 问题的开放 JIRA。
更多数据库
随着我们添加更多微服务数据库,我们将开始对我们拥有的两个 Debezium MySQL 服务器施加压力。最终,我们计划将我们拥有的单个 Debezium 集群分成多个集群,一些微服务只复制到一个集群,其余的复制到其他集群。
统一兼容性检查
正如我在上面的模式部分提到的,Confluent Schema Registry 目前开箱即用地运行模式兼容性检查。这使得我们很容易防止向 Kafka 引入不兼容的向后和向前更改。我们目前在 MySQL 层没有等效的检查。这是一个问题,因为它意味着 DBA 可以在 MySQL 层进行不兼容的更改。然后 Debezium 在尝试将新消息生成到 Kafka 时会失败。我们需要确保这不会发生,方法是在 MySQL 层添加等效的检查。DBZ-70 对此进行了更详细的讨论。
自动主题配置
我们目前使用主题自动创建在 Kafka 中运行,默认配置为 6 个分区,以及基于时间/大小的保留策略。此配置对于 Debezium 主题的意义不大。至少,它们应该使用日志压缩作为其保留策略。我们计划编写一个脚本来查找配置不当的 Debezium 主题,并将其更新为适当的保留设置。
结论
我们在过去 8 个月里一直在生产环境中使用 Debezium。最初,我们将其作为隐式运行,然后启用了上面架构图中所示的实时 BigQuery 管道。最近,我们已经开始在微服务和流处理系统中消费消息。我们期待将更多数据添加到管道中,并解决“未来工作”部分提出的一些问题。
特别感谢 Randall Hauch,他在解决大量 bug 修复和功能请求方面提供了宝贵的帮助。
关于 Debezium
Debezium 是一个开源的分布式平台,可以将现有数据库转变为事件流,使应用程序能够几乎即时地看到并响应数据库中已提交的每个行级更改。Debezium 构建在 Kafka 之上,并提供了 Kafka Connect 兼容的连接器,用于监控特定的数据库管理系统。Debezium 将数据更改的历史记录在 Kafka 日志中,这样您的应用程序可以随时停止和重新启动,并可以轻松地消费在未运行时错过的所有事件,确保所有事件都被正确且完整地处理。Debezium 在 Apache 许可证 2.0 下是 开源 的。